Introducción
El objetivo de este post es mostrar algunas posibles aplicaciones de cadenas de Markov para el análisis de datos. Para ello, se utilizan datos de salarios de egresados universitarios en Argentina.
1. Librerías y definiciones
Se cargan las librerías a utilizar. Este post se enfoca en el uso de {markovchain} 📦1, el paquete R más popular para cadenas de Markov.
Algunas configuraciones adicionales:
Show code
theme_set(theme_minimal())
options(scipen=999)2. Data
Se obtienen los datos correspondientes a salarios de egresados universitarios en Argentina. Mediante el cruce de datos de graduados universitarios entre 2016 y 2018, se obtiene la situación de empleo de cada persona. Estos datos permiten analizar la inserción ocupacional en Noviembre de 2019, 2020 y 2021 para cada uno de los graduados en el período 2016-2018.
Show code
# Librerías ---------------------------------------------------------------
library(readr)
library(readxl)
library(dplyr)
# Datos raw ---------------------------------------------------------------
df <- read_csv('https://cdn.produccion.gob.ar/cdn-cep/araucano/base_araucano.csv')
# Diccionario de parametrías:
path <- "01_data/diccionario.xlsx"
sheetnames <- excel_sheets(path)
for(i in 1:length(sheetnames)) {
assign(sheetnames[i],read_excel(path,sheet = i))
}
cod_letra <- cod_letra %>%
janitor::clean_names()
# Datos limpios -----------------------------------------------------------
df_clean <- df %>%
left_join(cod_rama) %>%
left_join(cod_genero) %>%
left_join(cod_disciplina) %>%
left_join(cod_gestion) %>%
left_join(cod_letra) %>%
left_join(cod_region) %>%
left_join(cod_tamaño) %>%
left_join(cod_titulo) %>%
select(id, anio, anioegreso, salario, genero, anionac,
rama, disciplina, tipo_titulo,
region, tamaño, actividad = letra_1) %>%
arrange(id, anio)
# Save --------------------------------------------------------------------
df_clean %>% write.csv('01_data/df_clean.csv', row.names=FALSE)df <- read_csv('01_data/df_clean.csv')3. Análisis exploratorio de los datos
Para el entendimiento de los datos del Sistema Araucano, se recomienda leer el siguiente hilo de twitter ✨. A continuación se presenta una descripción de las variables incluidas en los datos a analizar.
| Name | df %>% sample_n(10000) |
| Number of rows | 10000 |
| Number of columns | 12 |
| _______________________ | |
| Column type frequency: | |
| character | 7 |
| numeric | 5 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| genero | 0 | 1.00 | 5 | 5 | 0 | 2 | 0 |
| rama | 0 | 1.00 | 8 | 20 | 0 | 6 | 0 |
| disciplina | 0 | 1.00 | 5 | 59 | 0 | 37 | 0 |
| tipo_titulo | 0 | 1.00 | 8 | 30 | 0 | 4 | 0 |
| region | 0 | 1.00 | 3 | 56 | 0 | 7 | 0 |
| tamaño | 4159 | 0.58 | 26 | 28 | 0 | 4 | 0 |
| actividad | 4162 | 0.58 | 9 | 99 | 0 | 19 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| id | 0 | 1.00 | 135403.34 | 79433.12 | 30.00 | 66699.75 | 136012.00 | 204375.5 | 273414 | ▇▇▇▇▇ |
| anio | 0 | 1.00 | 2020.00 | 0.82 | 2019.00 | 2019.00 | 2020.00 | 2021.0 | 2021 | ▇▁▇▁▇ |
| anioegreso | 0 | 1.00 | 2017.13 | 0.80 | 2016.00 | 2016.00 | 2017.00 | 2018.0 | 2018 | ▅▁▇▁▇ |
| salario | 4159 | 0.58 | 103218.73 | 146398.61 | 0.01 | 46515.71 | 76442.96 | 126998.5 | 8444075 | ▇▁▁▁▁ |
| anionac | 14 | 1.00 | 1986.53 | 8.02 | 1942.00 | 1984.00 | 1989.00 | 1992.0 | 1999 | ▁▁▁▅▇ |
4. Definición de segmentos
Tal como se observa, existe información de salarios registrados para los años 2019, 2020 y 2021. Cada individuo aparece en el dataframe 3 veces (una observación por año).
Se toma una muestra aleatoria de individuos egresados en 2018. La muestra permite realizar el procesamiento de los datos de forma más rápida.
➡️ Se busca estimar la probabilidad de transición entre segmentos de salario. Para ello, se definen 4 segmentos de salario:
🔸 Sin empleo registrado: individuos no registrados en Noviembre del año en cuestión.
🔸 Salario bajo: individuos con salario bajo en relación al resto de los individuos con salario registrado ese año.
🔸 Salario medio: individuos con salario medio en relación al resto de los individuos con salario registrado ese año.
🔸 Salario alto: individuos con salario alto en relación al resto de los individuos con salario registrado ese año.
La decisión de considerar los segmentos en términos relativos al resto de los individuos en cada año permite simplificar el análisis para analizar cambios entre segmentos.
df_markov <- df %>%
filter(id %in% ids) %>%
group_by(anio) %>%
mutate(
segmento_bin = cut_number(salario, n = 3, dig.lab = 7),
segmento = cut_number(
salario,
n = 3,
labels = c('salario_bajo',
'salario_medio',
'salario_alto')
)
) %>%
mutate(segmento = factor(
forcats::fct_explicit_na(segmento, 'sin_empleo_registrado'),
levels = c(
'sin_empleo_registrado',
'salario_bajo',
'salario_medio',
'salario_alto'
)
)) %>%
ungroup() %>%
select(id, anio, salario, segmento, segmento_bin) A continuación se presentan los datos correspondientes a 3 individuos aleatorios, con sus respectivos estados (2019, 2020 y 2021). Notar que en el primer caso, el salario comienza siendo alto en relación al resto de los salarios. Sin embargo, en 2021 pasa a ser medio en comparación al resto. Entre 2020 y 2021 su salario en pesos aumentó pero en términos relativos redujo su posición en el ranking salarial.
El segundo individuo arranca en 2019 sin empleo registrado. EN 2020 registra un salario alto y en 2021 su salario pasa a ser bajo en términos relativos. Por otro lado, el tercer individuo comienza el 2019 con un salario alto y luego deja de tener salarios registrados.
Show code
df_markov %>%
filter(id %in% c(52626, 210311, 234946)) %>%
gt() %>%
tab_header('Muestra de 3 individuos') %>%
opt_align_table_header('left')| Muestra de 3 individuos | ||||
| id | anio | salario | segmento | segmento_bin |
|---|---|---|---|---|
| 52626 | 2019 | 78086.83 | salario_alto | (66843.29,3167481] |
| 52626 | 2020 | 95589.99 | salario_alto | (92620.03,9518290] |
| 52626 | 2021 | 146394.27 | salario_medio | (90000,151751] |
| 210311 | 2019 | NA | sin_empleo_registrado | NA |
| 210311 | 2020 | 143800.00 | salario_alto | (92620.03,9518290] |
| 210311 | 2021 | 8470.07 | salario_bajo | [0.01,90000] |
| 234946 | 2019 | 78248.07 | salario_alto | (66843.29,3167481] |
| 234946 | 2020 | NA | sin_empleo_registrado | NA |
| 234946 | 2021 | NA | sin_empleo_registrado | NA |
Detrás de los cambios de situación salarial pueden existir un sinfin de explicaciones. El objetivo de este post no es encontrar estas causas, sino aplicar el concepto de cadenas de markov a estas transciones.
Se observa la cantidad de observaciones por año y por segmento. Cada uno de los segmentos fue definido de forma tal que los cortes en salarios generen 3 bins con igual cantidad de observaciones por año.
Show code
df_markov %>%
group_by(anio, segmento) %>%
summarise(N=n()) %>%
ungroup() %>%
pivot_wider(names_from=anio, values_from=N) %>%
gt() %>%
tab_header(title='Cantidad de individuos por segmento en cada año') %>%
opt_align_table_header('left')| Cantidad de individuos por segmento en cada año | |||
| segmento | 2019 | 2020 | 2021 |
|---|---|---|---|
| sin_empleo_registrado | 4489 | 4361 | 4102 |
| salario_bajo | 1837 | 1890 | 1967 |
| salario_medio | 1837 | 1869 | 1965 |
| salario_alto | 1837 | 1880 | 1966 |
5. Visualización de la transición entre segmentos
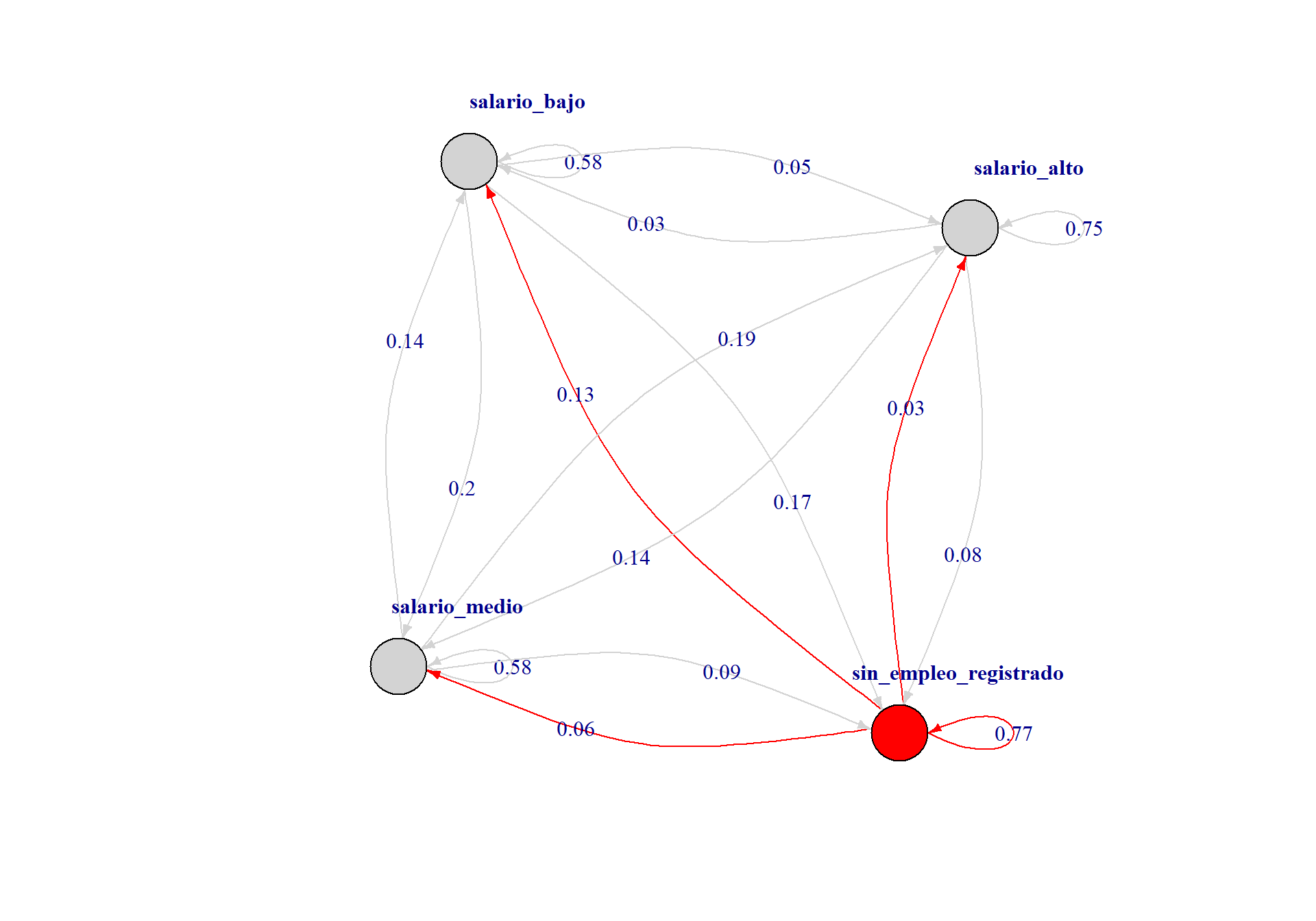
Previo a la construcción de la matriz de transición sobre los 4 segmentos definidos, se visualiza el grafo de la transición de estados entre 2019 y 2021. Utilizando {igraph} 📦2 se genera un grafo dirigido en donde cada nodo (o vértice) representa un estado. El vértice de origen es segmento salarial en 2019 y el de destino al segmento salarial en 2020. Los ejes representan la proporción de individuos que, habiendo iniciado en 2019 en un estado, transicionan a otro estado en 2021.
Notar que la suma de estas proporciones = 1 para cada uno de los estados. Es decir, si un individuo parte de salario bajo puede transicionar a salario medio, alto, sin salario registrado o mantenerse en salario bajo.
g <- df_markov %>%
select(-salario, -segmento_bin) %>%
filter(anio !=2020) %>%
tidyr::pivot_wider(names_from = anio, values_from = segmento) %>%
group_by(`2019`, `2021`) %>%
summarise(freq = n(), .groups = "drop") %>%
group_by(`2019`) %>%
mutate(
freq = round(proportions(freq), 3),
color = case_when(`2019` == 'sin_empleo_registrado' ~ 'red',
TRUE ~ 'lightgrey')
) %>%
graph_from_data_frame(directed=TRUE)Se indica que el color de los vértices del grafo dependa del segmento.
La representación de las transiciones en forma gráfica permite observar rápidamente cómo son las transiciones. En general, alguien que comienza en 2019 en un segmento se mantiene en ese mismo estado en 2021. Sin embargo, existen casos de individuos que transicionan a salarios mejores o peores (en términos relativos al resto de los individuos).
Show code
6. Cadenas de markov
Los datos se encuentran en un formato adecuado para trabajar con cadenas de Markov. Se presenta un ejemplo simple de cadenas de Markov para luego aplicarlo sobre los datos obtenidos.
6.1. Ejemplo simple
Supongamos que se cuenta con datos para 3 individuos, que entre 2019 y 2021 transicionan entre los segmentos A, B y C:
df_temp <- data.frame(
id = c(1, 1, 1, 2, 2, 2, 3, 3, 3),
anio = rep(c(2019, 2020, 2021), 3),
segmento = c('A', 'A', 'B', 'B', 'C', 'C', 'C', 'B', 'C')
)
df_temp id anio segmento
1 1 2019 A
2 1 2020 A
3 1 2021 B
4 2 2019 B
5 2 2020 C
6 2 2021 C
7 3 2019 C
8 3 2020 B
9 3 2021 CLa forma de realizar el análisis a nivel individual es mediante la función split() que genera los estados por los cuales transitó cada uno de los individuos de la muestra.
split(df_temp$segmento, df_temp$id)$`1`
[1] "A" "A" "B"
$`2`
[1] "B" "C" "C"
$`3`
[1] "C" "B" "C"La función markovchainFit() permite estimar la matriz de transición a partir de los datos por individuo.
mc <- markovchainFit(data = split(df_temp$segmento, df_temp$id),
method = 'mle' # 'bootstrap', 'laplacian'
)
mc$estimateMLE Fit
A 3 - dimensional discrete Markov Chain defined by the following states:
A, B, C
The transition matrix (by rows) is defined as follows:
A B C
A 0.5 0.5 0.0
B 0.0 0.0 1.0
C 0.0 0.5 0.5Esta matriz indica la probabilidad de transicionar al siguiente estado, considerando un estado inicial. En este sentido, cada fila representa el estado inicial, con lo cual un usuario que comienza en el estado A tiene 50% de probabilidad de mantenerse en el estado A y 50% de probabilidad de transicionar al estado B.
Notar que la probabilidad de que alguien que comience en A transicione a C es 0 en este caso. Esto es así dado que en los datos no se incluyó ninguna observación en donde la se pase de un estado A a C.
6.2. Transición en segmentos de salarios
Para poder realizar el análisis, se busca ajustar la cadena de markov a partir de datos de cada individuo.
$`2`
[1] sin_empleo_registrado sin_empleo_registrado sin_empleo_registrado
4 Levels: sin_empleo_registrado salario_bajo ... salario_alto
$`53`
[1] salario_bajo salario_bajo sin_empleo_registrado
4 Levels: sin_empleo_registrado salario_bajo ... salario_altoA partir de estos datos, se ajusta la cadena de markov. En este caso, utilizando el método MLE (maximum likelihood estimation o estimación de máxima verosimilitud).
mc <- markovchainFit(data = split(df_markov$segmento, df_markov$id),
method = 'mle' # 'bootstrap', 'laplacian'
)Se muestra en forma prolija la matriz de transición entre estados:
Show code
data.frame(mc$estimate@transitionMatrix) %>%
select(all_of(levels(df_markov$segmento))) %>%
rownames_to_column('estado_inicial') %>%
mutate(estado_inicial = factor(estado_inicial,
levels = levels(df_markov$segmento))) %>%
arrange(estado_inicial) %>%
gt(rowname_col = 'estado_inicial') %>%
fmt_number(2:5) %>%
tab_header(title = 'Matriz de transición') %>%
opt_align_table_header('left') | Matriz de transición | ||||
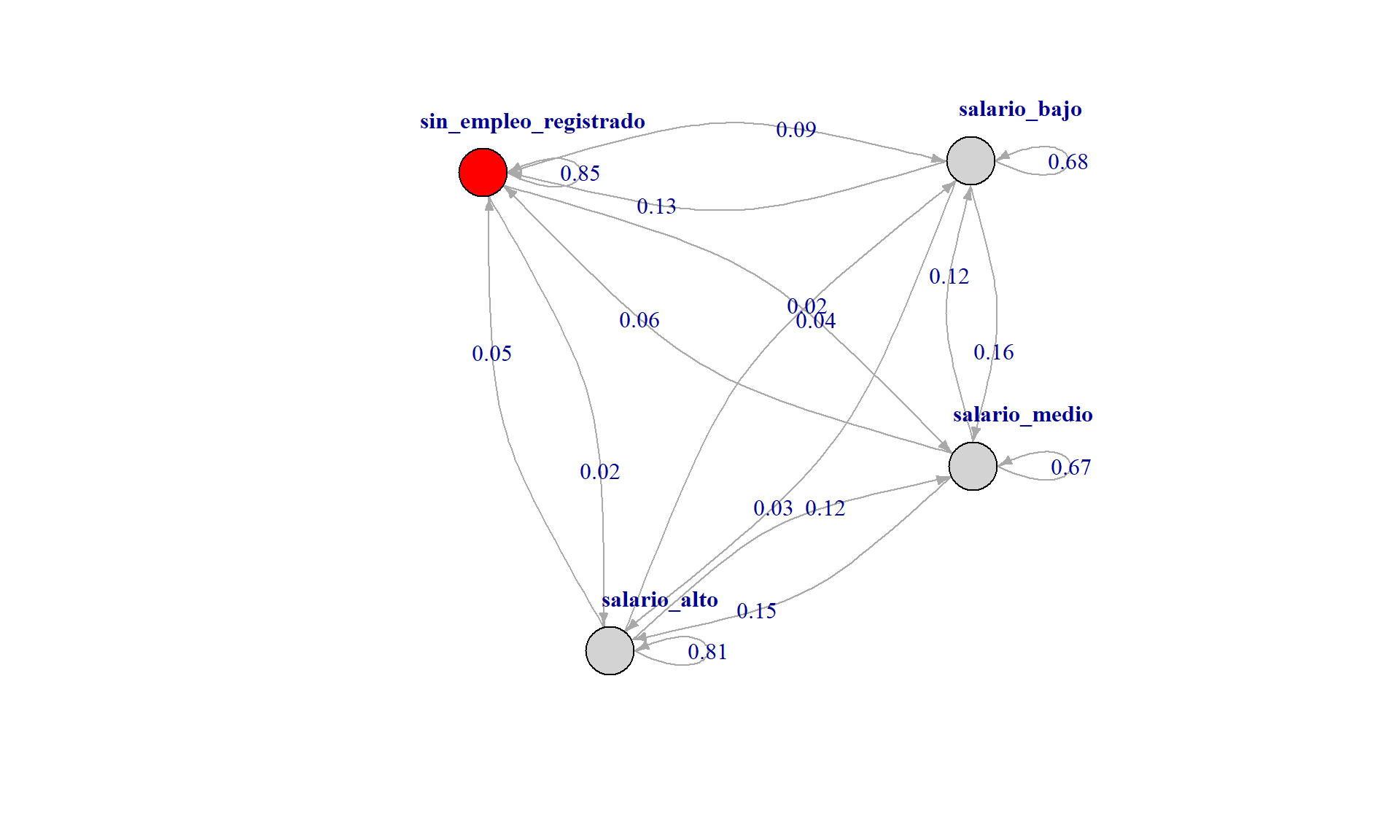
| sin_empleo_registrado | salario_bajo | salario_medio | salario_alto | |
|---|---|---|---|---|
| sin_empleo_registrado | 0.85 | 0.09 | 0.04 | 0.02 |
| salario_bajo | 0.13 | 0.68 | 0.16 | 0.03 |
| salario_medio | 0.06 | 0.12 | 0.67 | 0.15 |
| salario_alto | 0.05 | 0.02 | 0.12 | 0.81 |
Es posible visualizar la matriz de transición en forma de grafo. Esta matriz es similar a la que se contruyó con {igraph} 📦. Sin embargo, esta matriz considera la transición en 2 pasos (años), mientras que en la visualización inicial se había considerado la generación del grafo a partir de un origen (2019) y destino (2021).
Show code
Probabilidad en 2 años
📝Suponiendo que un individuo parte de un segmento “salario_bajo” en Noviembre 2022, se busca estimar la probabilidad de transicionar al segmento de “salario_alto” en Noviembre 2024.
Una posible alternativa es considerar la matriz de transición inicial y realizar el cálculo manual:
Show code
# Prob de mantenerse en salario bajo en t=1 y pasar a salario alto en t=2
prob_1b = mc$estimate@transitionMatrix %>% data.frame() %>%
filter(row.names(.) == 'salario_bajo') %>% pull(salario_bajo)
prob_2a = mc$estimate@transitionMatrix %>% data.frame() %>%
filter(row.names(.) == 'salario_bajo') %>% pull(salario_alto)
prob_ba = prob_1b * prob_2a
# Prob de pasar a salario medio en t=1 y pasar a salario alto en t=2
prob_1m = mc$estimate@transitionMatrix %>% data.frame() %>%
filter(row.names(.) == 'salario_bajo') %>% pull(salario_medio)
prob_2a = mc$estimate@transitionMatrix %>% data.frame() %>%
filter(row.names(.) == 'salario_medio') %>% pull(salario_alto)
prob_ma = prob_1m * prob_2a
# Prob de pasar a salario alto en t=1 y mantenerse en salario alto en t=2
prob_1a = mc$estimate@transitionMatrix %>% data.frame() %>%
filter(row.names(.) == 'salario_bajo') %>% pull(salario_alto)
prob_2a = mc$estimate@transitionMatrix %>% data.frame() %>%
filter(row.names(.) == 'salario_alto') %>% pull(salario_alto)
prob_aa = prob_1a * prob_2a
round((prob_ba + prob_ma + prob_aa), 2)[1] 0.07Esto es muy tedioso. Una forma más simple es utilizar la matriz de transición al cuadrado (2 años). Esto se denomina probabilidad de transición de n pasos. Notar que en ambos casos se obtiene el mismo resultado.
Show code
n = 2
mc_2y <- mc$estimate ^ nShow code
data.frame(mc_2y@transitionMatrix) %>%
select(all_of(levels(df_markov$segmento))) %>%
rownames_to_column('estado_inicial') %>%
mutate(estado_inicial = factor(estado_inicial,
levels = levels(df_markov$segmento))) %>%
arrange(estado_inicial) %>%
gt(rowname_col = 'estado_inicial') %>%
fmt_number(2:5) %>%
tab_style(
style = cell_fill(color = "grey"),
locations = cells_body(columns = salario_alto,
rows = 2)
)| sin_empleo_registrado | salario_bajo | salario_medio | salario_alto | |
|---|---|---|---|---|
| sin_empleo_registrado | 0.75 | 0.14 | 0.07 | 0.04 |
| salario_bajo | 0.22 | 0.49 | 0.22 | 0.07 |
| salario_medio | 0.11 | 0.17 | 0.49 | 0.23 |
| salario_alto | 0.09 | 0.05 | 0.18 | 0.68 |
Comentarios finales
En este post mostraron algunas cuestiones vinculadas a cadenas de markov en R. Se utilizó como ejemplo los datos de salarios de egresados universitarios en Argentina. Dado que el objetivo era indagar sobre aspectos de las cadenas de markov, ciertas cuestiones metodológicas sobre los datos podrían enriquecer muchísimo el análisis. Cualquier comentario, duda o sugerencia es bienvenida!
Contacto ✉
Karina Bartolome, Linkedin, Twitter, Github, Blogpost
SessionInfo()
Show code
sessioninfo::package_info() %>%
filter(attached==TRUE) %>%
select(package, loadedversion, date, source) %>%
gt() %>%
tab_header(title='Paquetes utilizados',
subtitle='Versiones') %>%
opt_align_table_header('left')| Paquetes utilizados | |||
| Versiones | |||
| package | loadedversion | date | source |
|---|---|---|---|
| dplyr | 1.1.1 | 2023-03-22 | CRAN (R 4.2.3) |
| forcats | 1.0.0 | 2023-01-29 | CRAN (R 4.2.3) |
| ggplot2 | 3.4.2 | 2023-04-03 | CRAN (R 4.2.0) |
| gt | 0.9.0 | 2023-03-31 | CRAN (R 4.2.3) |
| igraph | 1.3.2 | 2022-06-13 | CRAN (R 4.2.0) |
| lubridate | 1.9.2 | 2023-02-10 | CRAN (R 4.2.3) |
| markovchain | 0.9.1 | 2023-01-19 | CRAN (R 4.2.3) |
| purrr | 1.0.1 | 2023-01-10 | CRAN (R 4.2.3) |
| readr | 2.1.4 | 2023-02-10 | CRAN (R 4.2.3) |
| skimr | 2.1.4 | 2022-04-15 | CRAN (R 4.2.0) |
| stringr | 1.5.0 | 2022-12-02 | CRAN (R 4.2.3) |
| tibble | 3.2.1 | 2023-03-20 | CRAN (R 4.2.3) |
| tidyr | 1.3.0 | 2023-01-24 | CRAN (R 4.2.3) |
| tidyverse | 2.0.0 | 2023-02-22 | CRAN (R 4.2.3) |