Aclaraciones
Trabajo realizado para una materia de la facultad. El foco está puesto sobre el uso de los métodos, no los datos en sí. Utilicé datos vinculados a pobreza y condiciones de vida para poder realizar una interpretación de los resultados. Cualquier comentario es bienvenido.
Introducción
La pobreza es un fenómeno multidimensional que excede la insuficiencia monetaria. La pobreza crónica o estructural alude a carencias persistentes que no pueden superarse aun en períodos de alto empleo y mayor prosperidad económica general. Es decir, existe inelasticidad a los beneficios del crecimiento económico o de las políticas inclusivas. Las características de las personas y hogares que viven bajo pobreza crónica son baja educación, bajo capital, baja productividad, entre otras.
En el presente trabajo se analiza la situación Argentina en base a variables que se tienen en cuenta en la medición de pobreza multidimensional. Se incorporan variables correspondientes a educación, características de los hogares, situación laboral, entre otras.
Se plantea un resúmen del marco teórico a considerar para el análisis. Luego, se realiza un análisis estadístico de los datos utilizados. Posteriormente, se utiliza la técnica de análisis de componentes principales para reducir la dimensionalidad, en búsqueda de la mínima cantidad de componentes que expliquen la situación del país. Mediante el método de análisis de conglomerados se agrupan las observaciones con características similares. Se analizan las diferencias entre grupos según sus características. Finalmente, se incluyen comentarios finales y una comparación con la situación en términos de pobreza crónica.
1. Marco teórico
En un trabajo reciente, Gasparini, Gluzmann, and Tornarolli (2019), se propone una metodología para analizar la pobreza crónica en Argentina a nivel departamental, considerando la Encuesta Permanente de Hogares (EPH) y el Censo 2010. La metodología parte de estimar la pobreza por ingresos en base a la EPH. Considerando que la EPH se mide trimestralmente, se cuenta con una evolución de la pobreza. Se analiza el impacto de ciertas variables de la EPH sobre este indicador de pobreza y, dado que dichas variables también están presentes en el Censo 2010, se estima la pobreza crónica departamental utilizando la metodología de Small Area Estimation.
Recientemente se han publicado datos preliminares del Pre Censo de vivienda. Estos datos incluyen una gran cantidad de variables sobre las características de los hogares, con una cobertura más amplia que la EPH.
2. Librerías
Show code
library(tidyverse) # Manipulación de datos y gráficos
library(skimr) # Análisis exploratorio de las variables
library(gt) # Tablas
library(kableExtra) # Tablas
library(corrplot) # Matriz de correlación
library(RColorBrewer) # Paleta de colores
library(psych) # Test de Bartlett
library(tidytext) # Labels en gráficos
library(NbClust) # Número óptimo de clusters (Ward)
library(factoextra) # Número óptimo de clusters (Kmeans)
library(cowplot) # Gráficos múltiples
library(patchwork) # Combinar ggplots
library(rgdal) # Para trabajar con shapefiles
library(sf) # Para trabajar con datos espaciales
library(biscale) # Escala bivariada
library(ggstatsplot) # Gráficos estadísticosShow code
options(scipen=999)
colores <- c('#1B9E77','#7570B3','#D95F02')
xaringanExtra::use_panelset()3. Desarrollo metodológico
3.1 Datos
Se utilizan datos de características de los departamentos incluidos en un informe del CEDLAS, PNUD, ODSA y CIPPEC1, el cual incluye variables de la Encuesta Permanente de Hogares (EPH) y el Censo 2010. Además, se incorporan ciertas variables del Pre Censo de Viviendas (2021)2 publicado por el INDEC.
Show code
df_pobreza_cronica <- df_pobreza_cronica %>%
mutate(p_pea = (PEA/poblacion)*100,
tamaño_hogares = poblacion/n_hogares)
df_precenso_viviendas <- df_precenso_viviendas %>%
# Existen datos faltantes. Son pocos departamentos (baja población).
# Se eliminan para no imputar valores y distorcionar el análisis.
filter(!is.na(ind01)) %>%
# Se seleccionan las variables relevantes, renommbrandolas.
select( nomdepto, nomprov, link, ind01:ind15, area) %>%
rename(total_viviendas = ind01, p_viv_particulares = ind03,
p_viv_colectivas = ind04, p_viv_casa = ind05, p_viv_depto = ind06,
p_viv_pieza_pension = ind10, p_viv_enconstruccion = ind11,
p_viv_finde = ind12, p_viv_nohabitacion = ind13,
p_viv_establecimiento = ind14, p_viv_country = ind08,
p_viv_dificilacceso = ind09, p_viv_callesinnombre = ind15,
p_viv_monoblock = ind07) %>%
# Se arreglan los códigos INDEC para las comunas de CABA.
# Este es el id para cruzar con los datos de pobreza crónica.
mutate(link = dplyr::case_when(nomdepto=='Comuna 1'~2001, nomdepto=='Comuna 2'~2002,
nomdepto=='Comuna 3'~2003, nomdepto=='Comuna 4'~2004, nomdepto=='Comuna 5'~2005,
nomdepto=='Comuna 6'~2006, nomdepto=='Comuna 7'~2007, nomdepto=='Comuna 8'~2008,
nomdepto=='Comuna 9'~2009, nomdepto=='Comuna 10'~2010, nomdepto=='Comuna 11'~2011,
nomdepto=='Comuna 12'~2012, nomdepto=='Comuna 13'~2013, nomdepto=='Comuna 14'~2014,
nomdepto=='Comuna 15'~2015, TRUE ~ as.numeric(link)))
# Se cruzan los datos de pobreza crónica con los datos del precenso de viviendas.
df <- df_pobreza_cronica %>% mutate(LINK_DEPTO=as.integer(LINK_DEPTO)) %>%
inner_join(df_precenso_viviendas %>% rename(LINK_DEPTO=link), by='LINK_DEPTO')
# Se seleccionan las variables sobre las cuales se aplicará PCA
df_pca <- df %>%
select(
# Variables de la base de pobreza crónica:
LINK_DEPTO, p_hac4_hog:p_def_sal2_per, p_pea, tamaño_hogares,
# Variables del precenso de viviendas
p_viv_casa, p_viv_depto,p_viv_enconstruccion,
p_viv_callesinnombre,p_viv_monoblock) %>%
# Se indica que la columna de id de cada departamento sea el índice.
tibble::column_to_rownames(var='LINK_DEPTO')Se cuenta con 13 variables y 458 observaciones, donde cada observación corresponde a un Departamento de Argentina. Se han eliminado los departamentos con menos de 2000 habitantes debido a que los mismos no fueron incluidos en el Pre Censo de Viviendas. Las variables correspondientes al Pre Censo de Viviendas comienzan con ‘p_viv’. Las variables que comienzan con ‘p_’ corresponden a porcentajes sobre el total de la población en cada departamento.
Show code
library(kableExtra)
data <- data.frame(Variable = names(df_pca)) %>%
mutate(Descripción = case_when(
Variable == 'p_urb_per' ~ '% Personas en hogares urbanos',
Variable == 'p_hac4_hog' ~'% Hogares con hacinamiento crítico',
Variable == 'p_casaB_hog' ~'% Hogares en vivienda deficitaria',
Variable == 'p_defclo_hog' ~'% Hogares con déficit de conexión a red',
Variable == 'p_jprimcom_hog' ~'% Hogares con jefe con nivel primario completo',
Variable == 'p_jsecinc_hog' ~'% Hogares con jefes con secundario incompleto',
Variable == 'p_n_noasist' ~'% Niños/as que de entre 6 y 17 años que no asisten a instituciones educativas formales',
Variable == 'p_def_sal2_per' ~'% Personas sin obra social ni prepaga ',
Variable == 'p_pea' ~'% población económicamente activa ',
Variable == 'tamaño_hogares' ~'Tamaño de los hogares (cantidad de hogares sobre población)',
Variable == 'p_viv_casa' ~'% Viviendas particulares tipo casa sobre el total de viviendas particulares. En esta categoría se incluyen las viviendas tipo rancho y casilla',
Variable == 'p_viv_depto' ~'% Viviendas particulares tipo departamento sobre el total de viviendas particulares. Se incluyen los comúnmente denominados de "propiedad horizontal (PH)" y los ubicados en "edificios en altura" de dos o más pisos',
Variable == 'p_viv_enconstruccion' ~'% Viviendas particulares en construcción sobre el total de viviendas particulares',
Variable == 'p_viv_callesinnombre' ~'% entre las viviendas particulares ubicadas en calles sin nombre oficial sobre el total de viviendas particulares',
Variable == 'p_viv_monoblock'~'% Departamentos en edificio de altura o monoblock sobre el total de viviendas tipo departamento',
TRUE ~ 'NA'))
kbl(data, booktabs = T) %>%
kable_styling(full_width = F) %>%
column_spec(1, bold = T, color = 'darkblue') %>%
column_spec(2, width = "30em")| Variable | Descripción |
|---|---|
| p_hac4_hog | % Hogares con hacinamiento crítico |
| p_casaB_hog | % Hogares en vivienda deficitaria |
| p_defclo_hog | % Hogares con déficit de conexión a red |
| p_jprimcom_hog | % Hogares con jefe con nivel primario completo |
| p_jsecinc_hog | % Hogares con jefes con secundario incompleto |
| p_n_noasist | % Niños/as que de entre 6 y 17 años que no asisten a instituciones educativas formales |
| p_def_sal2_per | % Personas sin obra social ni prepaga |
| p_pea | % población económicamente activa |
| tamaño_hogares | Tamaño de los hogares (cantidad de hogares sobre población) |
| p_viv_casa | % Viviendas particulares tipo casa sobre el total de viviendas particulares. En esta categoría se incluyen las viviendas tipo rancho y casilla |
| p_viv_depto | % Viviendas particulares tipo departamento sobre el total de viviendas particulares. Se incluyen los comúnmente denominados de “propiedad horizontal (PH)” y los ubicados en “edificios en altura” de dos o más pisos |
| p_viv_enconstruccion | % Viviendas particulares en construcción sobre el total de viviendas particulares |
| p_viv_callesinnombre | % entre las viviendas particulares ubicadas en calles sin nombre oficial sobre el total de viviendas particulares |
| p_viv_monoblock | % Departamentos en edificio de altura o monoblock sobre el total de viviendas tipo departamento |
3.2 Análisis exploratorio
Se presenta un breve análisis de las variables métricas. Exceptuando el tamaño de los hogares, todas las variables tienen la misma unidad de medida (porcentaje). Sin embargo, se observan diferencias significativas en la distribución de cada variable, siendo esto una justificación de la necesidad de estandarización.
Show code
skim(df_pca) %>% rename(Variable = skim_variable) %>%
select(-complete_rate, -n_missing, -numeric.hist, -skim_type) %>%
mutate(across(where(is.numeric),round, 2)) %>%
rename(Promedio = numeric.mean, `Desvío estándar`=numeric.sd,
p0=numeric.p0,p25=numeric.p25, Mediana=numeric.p50,
p75=numeric.p75, p100=numeric.p100) %>%
gt() %>% tab_header(title = md('**Características departamentales (Argentina)**'),
subtitle = 'Distribución de las variables' ) %>%
opt_align_table_header('left')| Características departamentales (Argentina) | |||||||
| Distribución de las variables | |||||||
| Variable | Promedio | Desvío estándar | p0 | p25 | Mediana | p75 | p100 |
|---|---|---|---|---|---|---|---|
| p_hac4_hog | 4.87 | 3.51 | 0.21 | 2.41 | 4.08 | 6.53 | 38.77 |
| p_casaB_hog | 24.91 | 19.89 | 1.29 | 9.70 | 17.24 | 35.48 | 95.82 |
| p_defclo_hog | 62.44 | 29.60 | 0.47 | 39.59 | 61.72 | 91.71 | 100.00 |
| p_jprimcom_hog | 57.92 | 14.37 | 6.84 | 51.09 | 60.21 | 67.37 | 88.84 |
| p_jsecinc_hog | 70.44 | 12.72 | 11.65 | 65.36 | 72.76 | 78.30 | 93.19 |
| p_n_noasist | 6.84 | 2.95 | 1.46 | 4.93 | 6.28 | 8.02 | 23.88 |
| p_def_sal2_per | 42.50 | 14.24 | 6.93 | 31.54 | 40.80 | 51.34 | 85.32 |
| p_pea | 45.39 | 7.49 | 20.17 | 39.99 | 47.60 | 50.23 | 65.11 |
| tamaño_hogares | 3.38 | 0.46 | 2.05 | 3.01 | 3.38 | 3.70 | 4.88 |
| p_viv_casa | 79.46 | 17.24 | 0.50 | 74.10 | 84.80 | 90.47 | 99.90 |
| p_viv_depto | 16.20 | 16.41 | 0.00 | 5.40 | 11.20 | 20.80 | 97.60 |
| p_viv_enconstruccion | 1.74 | 1.27 | 0.00 | 0.90 | 1.60 | 2.30 | 7.90 |
| p_viv_callesinnombre | 13.20 | 15.25 | 0.00 | 2.20 | 6.20 | 20.45 | 100.00 |
| p_viv_monoblock | 18.15 | 23.45 | 0.00 | 0.00 | 7.20 | 26.20 | 100.00 |
Show code
df_pca %>% pivot_longer(cols = c(names(df_pca))) %>%
mutate(color=ifelse(str_detect(name,'p_viv'),'Pre Censo','Pobreza Crónica')) %>%
ggplot(aes(x=value, fill=color))+
geom_histogram(bins=25,color='white')+
facet_wrap(~name, scales='free')+theme_minimal()+
scale_fill_manual(values=c(colores[1],colores[2]))+
labs(x='Valor',y='Frecuencia',title='Distribuciones')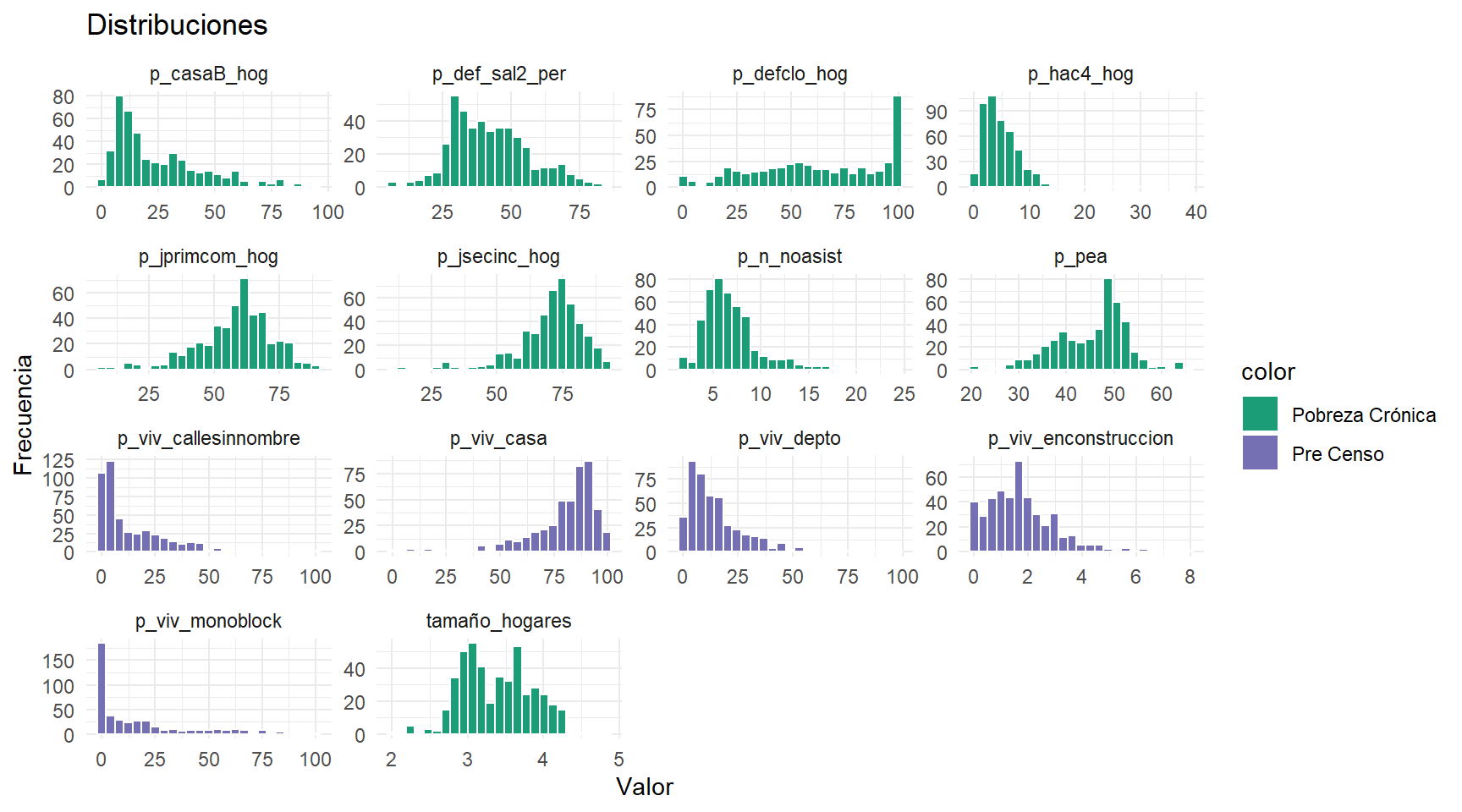
Se genera la matriz de correlación (R). Las correlaciones que contienen una cruz no son estadísticamente significativas considerando un nivel de significatividad del 5%.
Show code
# Matriz de correlaciones de Pearson
R <- df_pca %>% cor()
# Cálculo de los p-valores de las correlaciones:
pvalues <- cor.mtest(df_pca, conf.level = .95)
R %>% corrplot(method = 'circle', type = "lower", tl.cex = 0.5,
order = "hclust", p.mat =pvalues$p, insig = "pch", tl.col='black',
col = c('#762a83','#9970ab','#c2a5cf','#e7d4e8',
'#d9f0d3','#a6dba0','#5aae61','#1b7837'))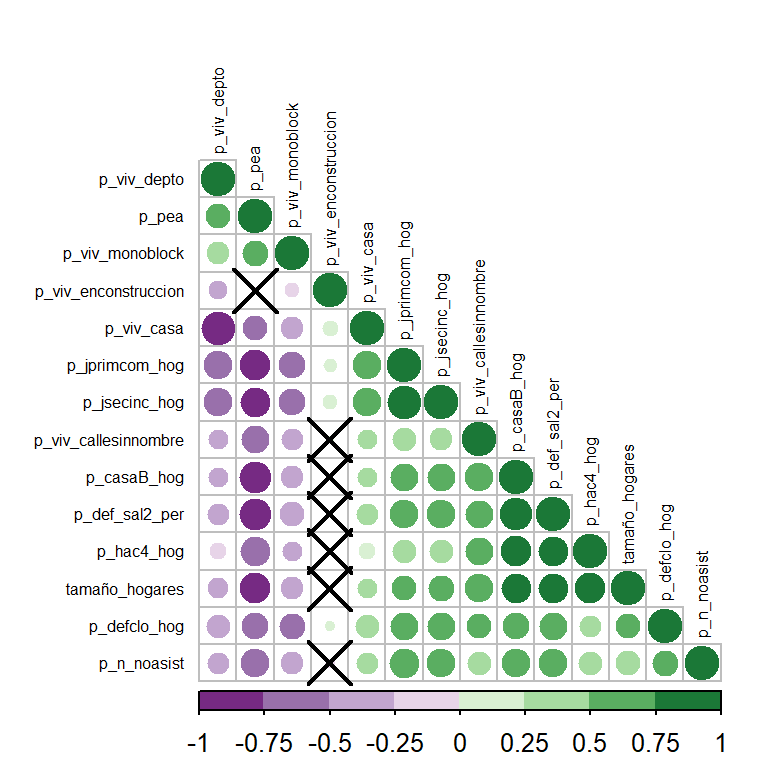
El Test de Bartlett verifica si la matriz de correlación definida anteriormente se diferencia significativamente de la matriz identidad. Realizar Análisis de Componentes Principales no tendría sentido ante la inexistencia de correlación entre las variables.
Show code
R %>% cortest.bartlett(n = nrow(df_pca), diag = TRUE)$chisq
[1] 7974.966
$p.value
[1] 0
$df
[1] 91En este caso, es posible rechazar la hipótesis nula en favor de la hipótesis alternativa de existencia de correlación entre las variables.
4. Análisis de componentes principales
El análisis de componentes principales tiene como objetivo representar la información de N observaciones y P variables en un número menor de variables construidas como una combinación lineal de las variables originales. Este método permite la interpretación de un gran número de variables a través de componentes no correlacionados entre sí.
Matemáticamente, el primer componente se escribe como la combinación lineal de las variables que captura la mayor variabilidad posible de los datos. Las siguientes componentes deben explicar la mayor variabilidad posible restante que no haya sido explicada por las componentes anteriores. Es decir:
\(Z_{1}=ϕ_{11}X_{1}+ϕ_{21}X_{2}+...+ϕ_{p1}X_{p}\)
Siendo \(Z_{1}\) el primer componente principal, construido como una combinación lineal de las variables {\(X_{1},X_{2},...,X_p\)}, donde \(ϕ_{11}, ϕ_{11}, …, ϕ_{1p}\) son las cargas factoriales (loadings) de dicho componente. Las cargas factoriales pueden interpretarse como el peso que tiene cada variable en cada componente y, por lo tanto, permiten entender qué tipo de información recoge cada uno.
A continuación aplica el método a los datos presentados en la Sección 3.1. Previo a la aplicación del método, se centran y escalan los datos para evitar que se tomen más relevancia a las variables con valores mayores (mayor varianza).
4.1 Variabilidad explicada
Se presenta la variabilidad explicada por los primeros componentes principales. El primer componente explica un porcentaje considerable (57%).
Show code
data.frame(Métrica = c('SD','% Varianza','% Varianza acumulada')) %>%
bind_cols(summary(pca)$importance %>% data.frame() %>%
select(PC1:PC10)) %>%
mutate(across(where(is.numeric),~round(.,2))) %>% gt() %>%
tab_header(title=md('**Variabilidad explicada por cada componente**'),
subtitle='Primeros 10 componentes') %>%
opt_align_table_header('left')| Variabilidad explicada por cada componente | ||||||||||
| Primeros 10 componentes | ||||||||||
| Métrica | PC1 | PC2 | PC3 | PC4 | PC5 | PC6 | PC7 | PC8 | PC9 | PC10 |
|---|---|---|---|---|---|---|---|---|---|---|
| SD | 2.84 | 1.40 | 0.99 | 0.86 | 0.76 | 0.67 | 0.62 | 0.48 | 0.46 | 0.43 |
| % Varianza | 0.57 | 0.14 | 0.07 | 0.05 | 0.04 | 0.03 | 0.03 | 0.02 | 0.02 | 0.01 |
| % Varianza acumulada | 0.57 | 0.72 | 0.79 | 0.84 | 0.88 | 0.91 | 0.94 | 0.96 | 0.97 | 0.98 |
4.2 Número óptimo de componentes
Visualmente es notable la diferencia entre el porcentaje de variabilidad que explica el primer componente contra el resto. El segundo componente también aporta cierta variabilidad, sin embargo, el tercero no aporta tanto.
Show code
summary(pca)$importance %>%
data.frame() %>%
tibble::rownames_to_column('var') %>%
pivot_longer(-var) %>% filter(var=='Proportion of Variance') %>%
ggplot(aes(x=reorder(name,-value),y=value, group=1))+
geom_point(color=colores[1], size=5)+
geom_line(color=colores[1], size=2)+
theme_minimal()+
labs(x='Componente', y='% de varianza acumulada',
title='Varianza acumulada por componente principal')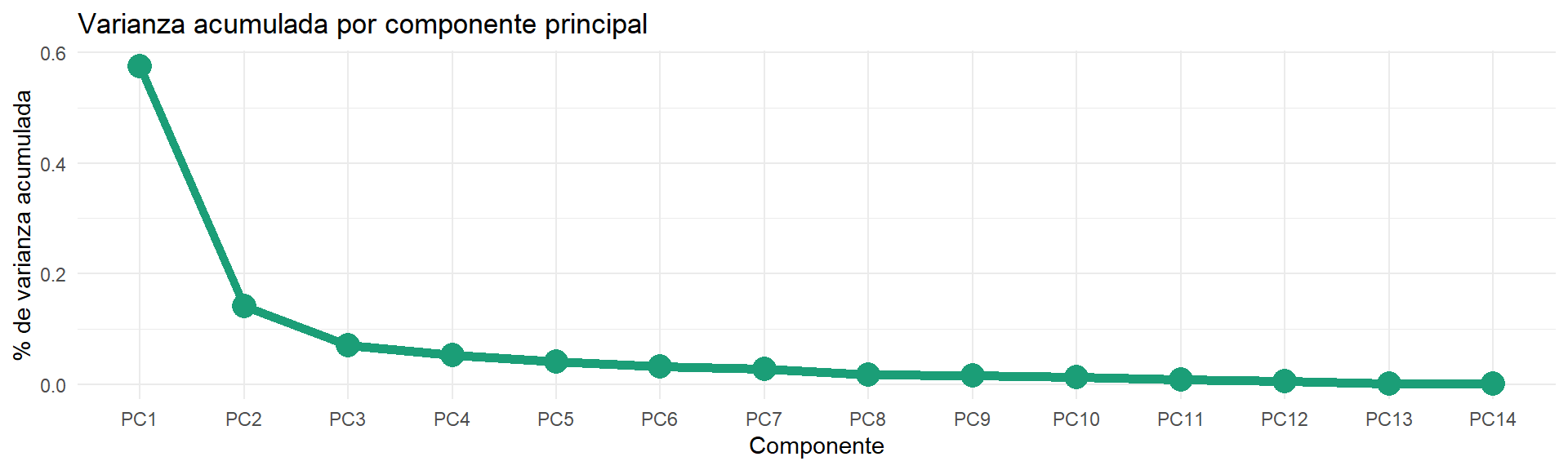
Mediante el método de Horn’s Parallel Analysis se seleccionan 2 componentes, según los autovalores ajustados mayores a 1.
Show code
paran::paran(df_pca, graph=FALSE, status=FALSE, all=FALSE)
Using eigendecomposition of correlation matrix.
Results of Horn's Parallel Analysis for component retention
420 iterations, using the mean estimate
--------------------------------------------------
Component Adjusted Unadjusted Estimated
Eigenvalue Eigenvalue Bias
--------------------------------------------------
1 7.746562 8.049282 0.302720
2 1.739612 1.971024 0.231411
--------------------------------------------------
Adjusted eigenvalues > 1 indicate dimensions to retain.
(2 components retained)4.3 Cargas factoriales
La correlación de cada variable con un componente principal permite entender qué representa cada componente. La carga factorial de la variable j en el componente h, \(L_{jh}\) está dada por:
\(L_{jh} = \frac{Cov(X_{j}, Z_h)}{Var(X_j)^\frac{1}{2}Var(Z_h)^\frac{1}{2}}\)
En este caso, se visualizan los primeros 4 componentes, donde el signo de las cargas de cada variable en cada componente mantienen lo observado en la matriz de correlación.
Show code
pca$rotation %>% data.frame() %>%
tibble::rownames_to_column(var='variable') %>%
pivot_longer(cols = -variable) %>%
filter(name %in% c('PC1','PC2','PC3','PC4')) %>%
group_by(name) %>%
slice_max(abs(value), n=5) %>%
ungroup() %>%
mutate(color=case_when(
variable %in% c('PEA','poblacion','n_hogares')~'Cantidad total',
stringr::str_detect(variable, 'p_viv_')~'Precenso de vivienda',
TRUE ~'Data CEDLAS')) %>%
ggplot(aes(x=reorder_within(variable,abs(value), name),
y=value, fill=as.factor(color)))+
geom_col(alpha=0.8)+
coord_flip()+
scale_x_reordered()+
scale_fill_manual(values=c(colores[1],colores[2]))+
facet_wrap(~name, scales='free')+ theme_minimal()+
labs(x='Variable',y='Carga factorial',
title='Componentes principales según carga factorial por variable',
subtitle='Primeros 4 componentes',
fill = 'Tipo de variable')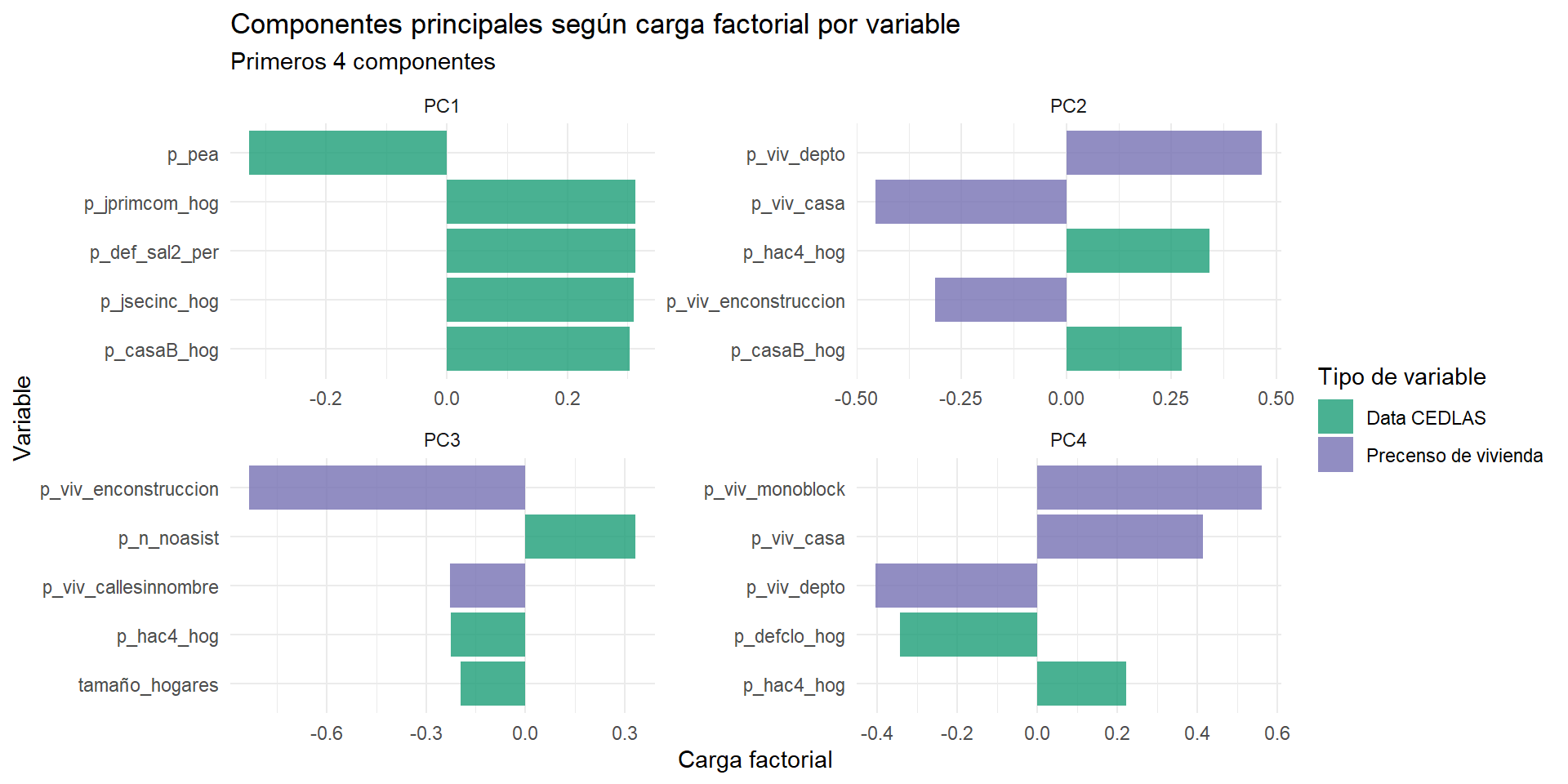
El primer componente incluye variables de la base de pobreza crónica (principalmente vinculadas a indicadores de pobreza). Este componente representa los indicadores de pobreza en términos de actividad (seguridad social y empleo), educación (primaria y secundaria del jefe de hogar, asistencia escolar). La variable que más influye es el porcentaje de población económicamente activa sobre la población total. Esta variable influye negativamente sobre el componente mientras que el resto de las variables lo hacen con signo contrario. Es esperable este resultado, ya que a mayor cantidad de personas en situación económicamente activa, el resto de los indicadores tiene sentido que se reduzcan.
En relación al segundo componente, el mismo sí incluye variables del Pre Censo de Viviendas. El porcentaje de viviendas que son departamentos y casas son las variables que más influyen, con signos opuestos, lo cual es esperable. La tercera variable más influyente es el indicador de hacinamiento en los hogares, seguido por el indicador de cantidad de viviendas en construcción. Los signos de las cargas para cada una de las variables en este componente parecieran indicar que el mismo representa hacinamiento o concentración de población.
Los componentes 3 y 4 se visualizan pero no son tenidos en cuenta dado que no explican un porcentaje considerable de variabilidad.
4.4 Departamentos según PCA
Proyectando los departamentos en el plano de los dos componentes seleccionados, se observa una diferencia entre los puntos de las comunas de la Ciudad Autónoma de Buenos Aires contra el resto de los departamentos del país. En términos del componente 2, las comunas de CABA presentan un valor superior al resto. Esto probablemente esté capturando la vida en la ciudad, donde gran cantidad de personas viven en departamentos. Por otro lado, en términos del componente 1 son las zonas con menores valores, indicando que la población en CABA presenta mejores condiciones en según actividad y educación.
Show code
var_explicada_PC1 <- summary(pca)$importance[2,1]
var_explicada_PC2 <- summary(pca)$importance[2,2]
# Componentes para cada departamento:
componentes <- as.data.frame(pca$x) %>%
tibble::rownames_to_column('LINK_DEPTO') %>%
mutate(LINK_DEPTO = as.integer(LINK_DEPTO)) %>%
left_join(df %>% dplyr::select(LINK_DEPTO, PROV, DPTO, provincia_GBA),
by='LINK_DEPTO') %>%
mutate(color = case_when(provincia_GBA=='Ciudad de Buenos Aires'~'CABA',
TRUE~'Resto'))
cargas_factoriales <- pca$rotation %>% data.frame() %>%
tibble::rownames_to_column(var='variable')
# Transformación en los valores para que las líneas de las cargas sean visibles:
scaler <- min(max(abs(componentes$PC1)) / max(abs(cargas_factoriales$PC1)),
max(abs(componentes$PC2)) / max(abs(cargas_factoriales$PC2)))
cargas_factoriales[, 2:3] <- cargas_factoriales[, 2:3] * scaler * 0.8
ggplot(componentes, aes(x=PC1,y=PC2, color=color))+
geom_point(alpha = 0.3) + stat_ellipse()+
geom_segment(data = cargas_factoriales, aes(x = 0,y = 0,xend = PC1,yend = PC2),
arrow = arrow(length = unit(0.2, "cm")),color = colores[2], size=1) +
ggrepel::geom_text_repel(data = cargas_factoriales,
aes(x = PC1, y = PC2, label = variable),
color = "black", max.overlaps = 10)+
scale_color_manual(values=c(colores[1],colores[3]))+
theme_minimal() +
theme(legend.position = 'top') +
labs(color='Ubicación', size='Población total',
title='Departamentos según componentes 1 y 2',
subtitle='Diferenciación entre CABA y resto',
x=paste('PC1 (',round(var_explicada_PC1*100,2),'%)'),
y=paste('PC2 (',round(var_explicada_PC2*100,2),'%)'))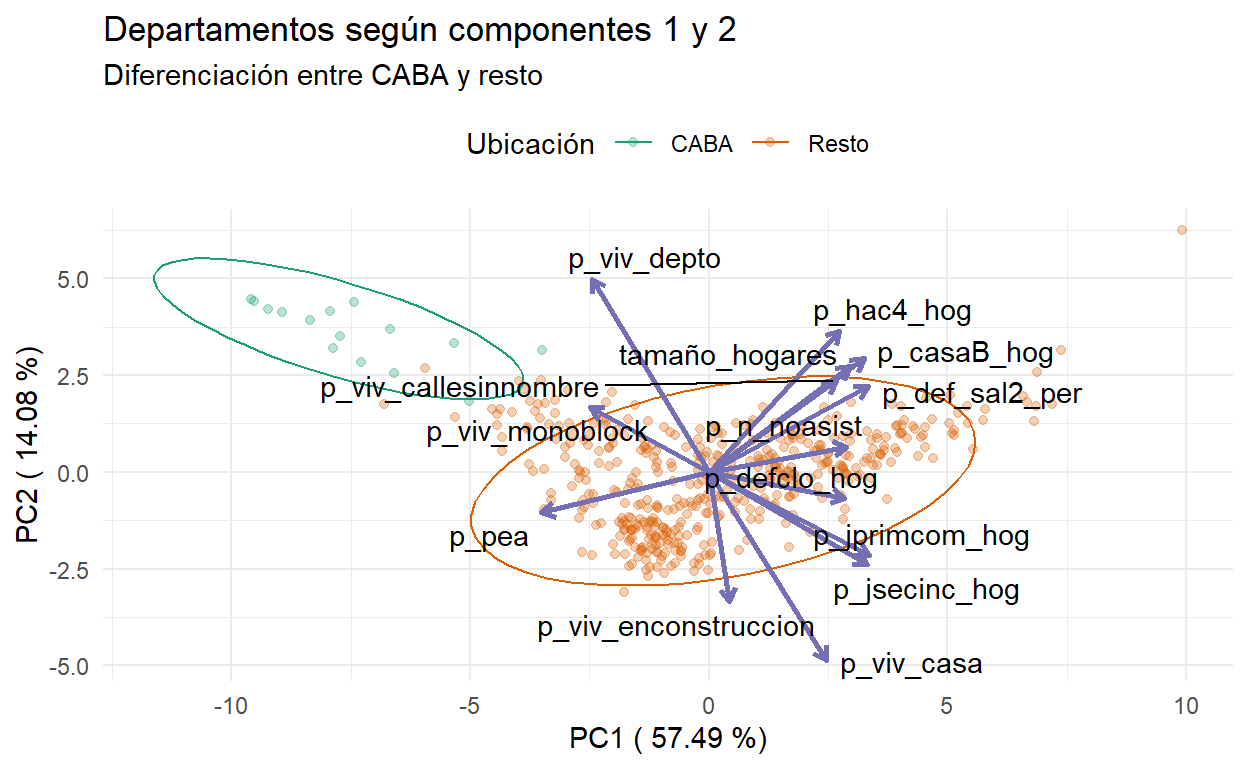
5. Conglomerados
El análisis de conglomerados es un método de aprendizaje no supervisado que tiene por objeto agrupar elementos en grupos homogéneos según características comunes entre ellos.
5.1 Clustering jerárquico de provincias
El método de Ward, o Método de varianza mínima, busca minimizar en cada paso el incremento en la suma de errores cuadrados intra-clusters, E, definida como: \(E = \sum_{k=1}^K E_k = \sum_{n=1}^{N} \sum_{p=1}^P(x_{kn,p} - \bar{x_{k,p}})^2\) , donde k: conglomerado, n: observación, p: variable.
Se parte de todas las posibles combinaciones y se fusiona el par con mínima distancia. Para este caso, se consideran agrupamientos por áreas geográficas (provincias, comunas y conurbano bonaerense), tomando el promedio de cada variable. Esto simplifica el cálculo y posibilita que el cómputo sea rápido.
Show code
df_provs <- df_pca %>%
tibble::rownames_to_column('LINK_DEPTO') %>%
mutate(LINK_DEPTO = as.integer(LINK_DEPTO)) %>%
left_join(df %>% select(LINK_DEPTO, provincia_GBA),
by='LINK_DEPTO') %>%
select(-LINK_DEPTO) %>%
mutate(provincia_GBA = ifelse(
provincia_GBA=='Provincia de Buenos Aires (sin conurbano)',
'Buenos Aires',provincia_GBA)) %>%
group_by(provincia_GBA) %>%
summarise_all(~mean(.))
# Se estandarizan las variables:
scaled_df <- scale(df_provs %>% select(-provincia_GBA),
center = TRUE, scale = TRUE)
# Matriz de distancias
matriz.dis.euclid<-dist(scaled_df,method="euclidean",diag=TRUE)
# Matriz de distancias cuadrada
matriz.dis.euclid2<-(matriz.dis.euclid)^2
# Clustering por el método de Ward
hclust.ward<-hclust(matriz.dis.euclid2,method="ward.D")
# Se selecciona el número óptimo de clusters
# res<-NbClust(scaled_df, distance = "euclidean", min.nc=3,
# max.nc=5, method = "single", index = "alllong")Utilizando las 24 áreas, el dendrograma permite observar qué provincias son más similares. El primer agrupamiento es entre Catamarca y La Rioja. Visualizando los resultados para 3 conglomerados, número óptimo según la mayor cantidad de indicadores, la Ciudad Autónoma de Buenos Aires constituye un cluster.
Show code
plot(hclust.ward, labels=df_provs$provincia_GBA,
main='Dendrograma método de Ward',
xlab='Matriz de distancias al cuadrado', ylab='Distancia', sub='')
rect.hclust(hclust.ward, k = 3, border = colores[3])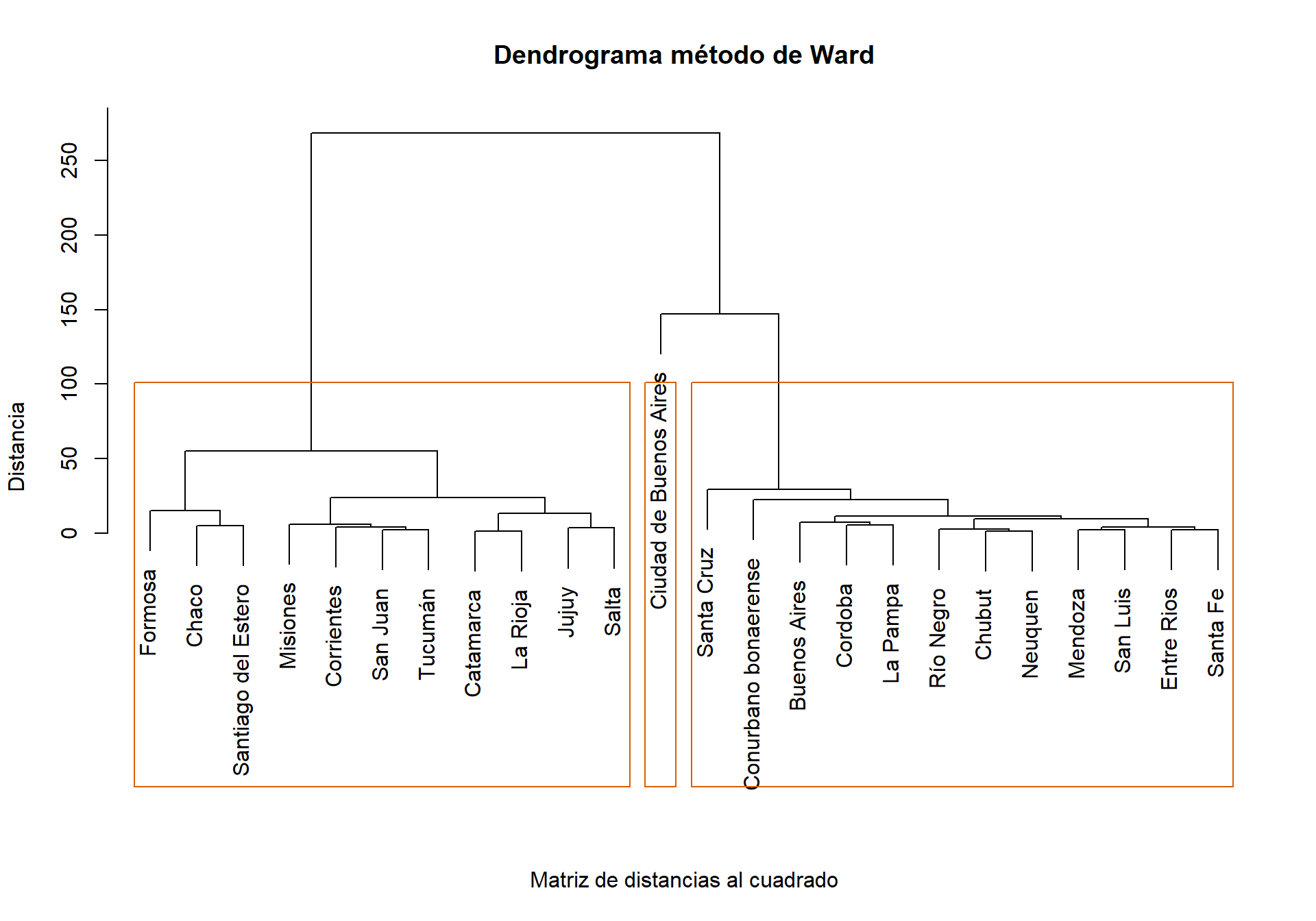
5.2 Conglomerados de departamentos con K-Medias
El método de K-medias agrupa observaciones en K clusters, siendo K un valor determinado a priori. Este algoritmo encuentra, mediante un proceso iterativo, los K agrupamientos con menor variación intra-cluster (homogeneidad entre grupos) y mayor diferenciación del resto (heterogeneidad entre grupos). Se parte de K centroides y se utiliza la distancia euclidea para decidir a qué grupo pertenece cada observación. En cada iteración sólo se permite mover un elemento de un grupo a otro. Dado que es un proceso iterativo, que inicia en ciertos agrupamientos, se utiliza una semilla para reproducibilidad del análisis. Para seleccionar el número óptimo de clusters, se utiliza el método del codo (“elbow method”).
Show code
scaled_df <- scale(df_pca, center = TRUE, scale = TRUE)
fviz_nbclust(x = scaled_df, FUNcluster = kmeans,
linecolor = colores[1],
method = "wss", # Suma de cuadrados
k.max = 10, # Máxima cantidad de clusters
diss = get_dist(scaled_df, method = "euclidean"), nstart = 50,
print.summary = TRUE) +
theme_bw()+
theme(text = element_text(size=8))+
labs(title='Cantidad óptima de conglomerados')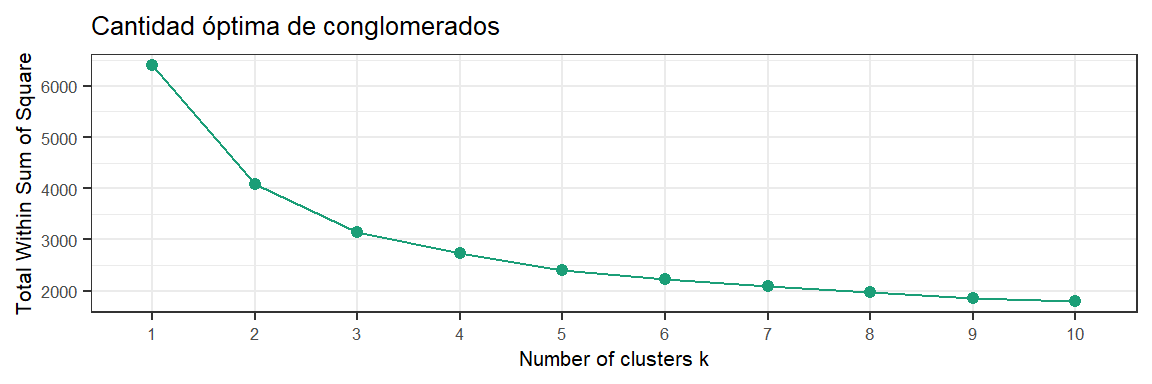
Con K = {3,4,5}, se generan 3 modelos distintos, se proyectan los datos en los 2 componentes principales seleccionados.
Show code
plot_kmeans <- function(modelo, clusters){
df_pca %>%
bind_cols(cluster=modelo$cluster) %>%
tibble::rownames_to_column('LINK_DEPTO') %>%
mutate(LINK_DEPTO = as.integer(LINK_DEPTO)) %>%
left_join(componentes %>% select(LINK_DEPTO, PROV, DPTO,
provincia_GBA,PC1,PC2),
by='LINK_DEPTO') %>%
ggplot(aes(x=PC1,y=PC2, color=as.factor(cluster)))+
geom_point(size=1.5, alpha = 0.5) +
scale_color_brewer(palette = 'Dark2')+
theme_minimal() +
theme(legend.position = 'top') +
labs(color='Cluster',
title=paste(clusters,'Clusters'),
subtitle='Visualización con PCA',
x=paste('PC1 (',round(var_explicada_PC1*100,2),'%)'),
y=paste('PC2 (',round(var_explicada_PC2*100,2),'%)'))
}
# Se generan 3 alternativas posibles de k=3,4,5
set.seed(42)
modelo_kmeans3 <- kmeans(scaled_df, 3)
p3 <- plot_kmeans(modelo_kmeans3, 3)
set.seed(42)
modelo_kmeans4 <- kmeans(scaled_df, 4)
p4 <- plot_kmeans(modelo_kmeans4, 4)
set.seed(42)
modelo_kmeans5 <- kmeans(scaled_df, 5)
p5 <- plot_kmeans(modelo_kmeans5, 5)
(p3 | p4) / p5 + plot_annotation(
title = 'Clustering k-medias')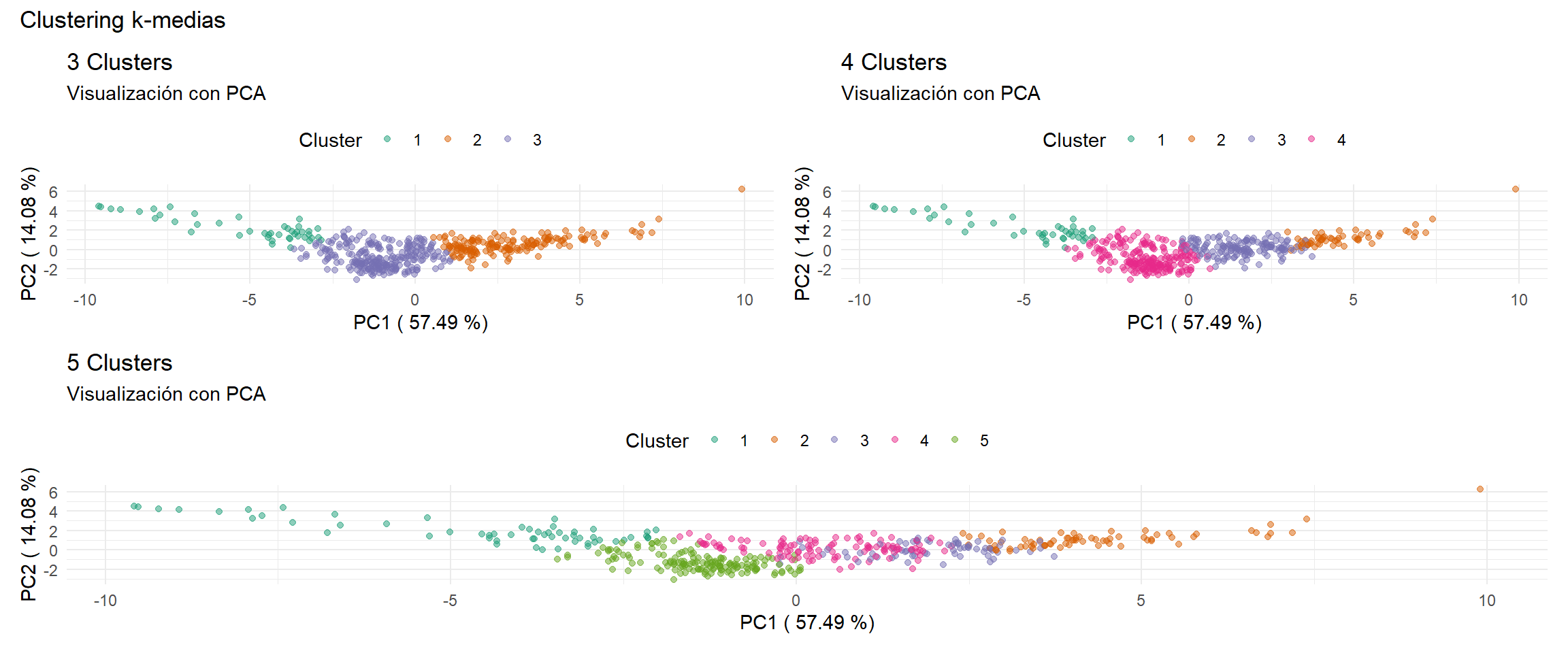
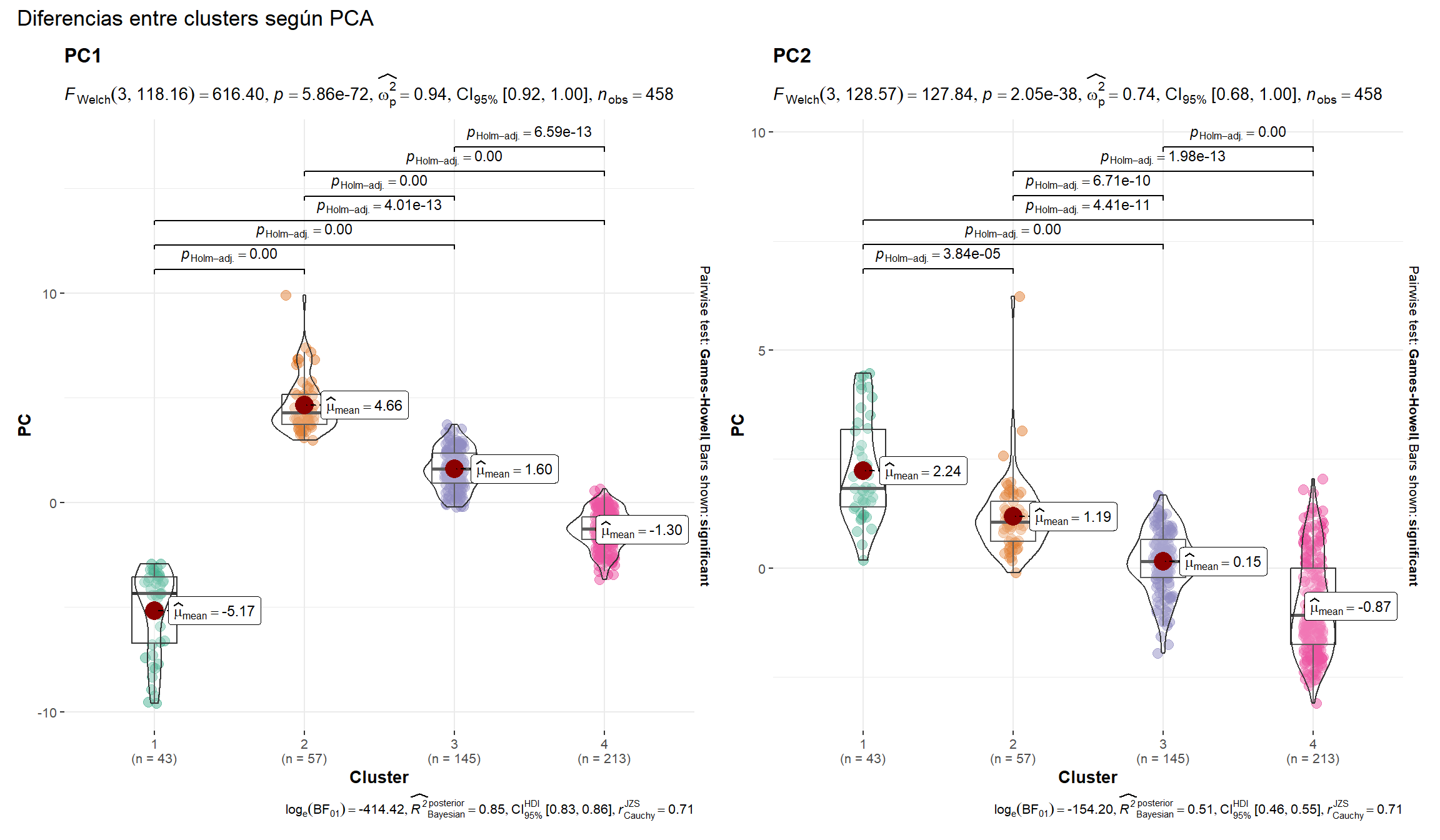
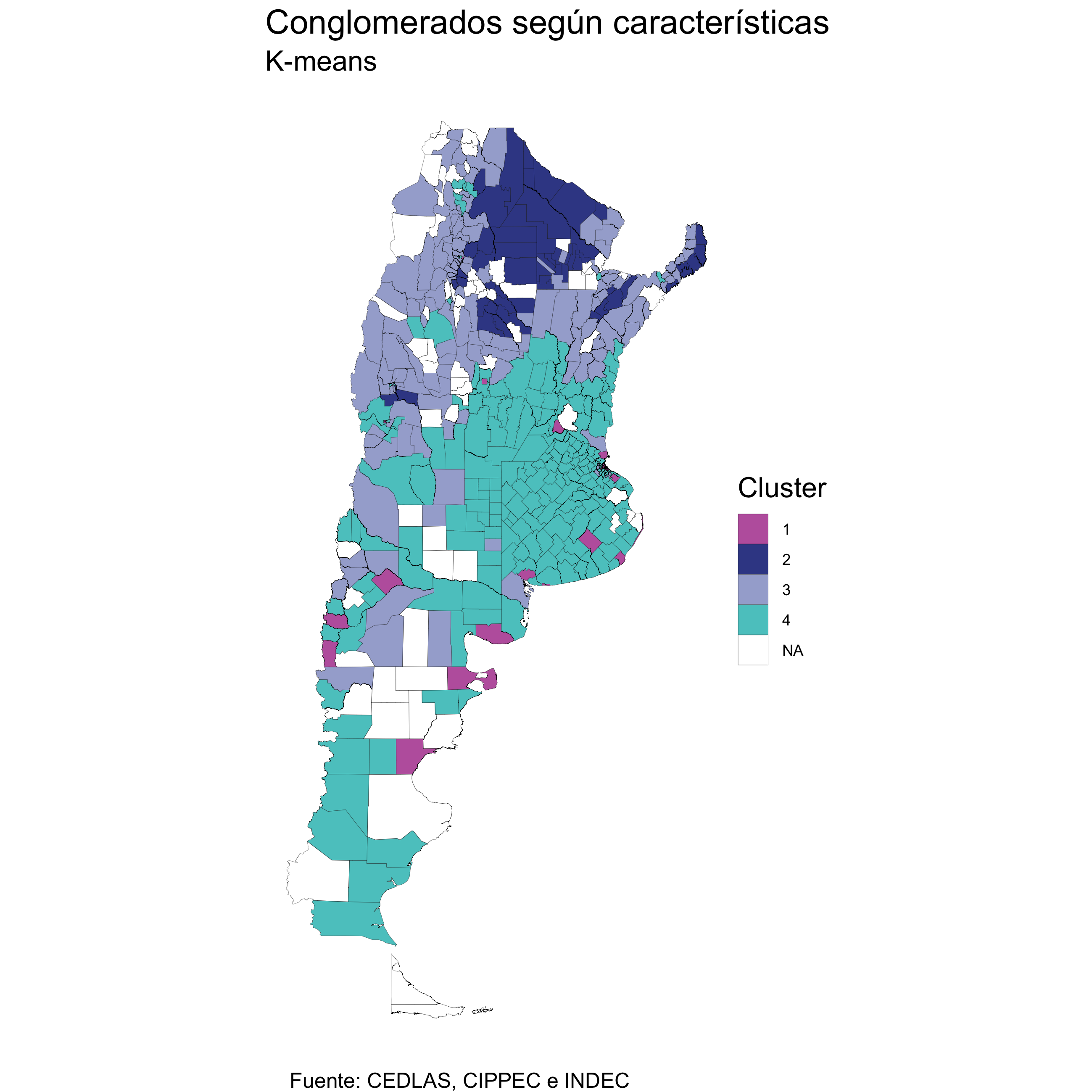
Se seleccionan 4 clusters, visualizando la distribución de las variables según los grupos construidos. Para este análisis se utiliza el paquete {ggstatsplot}, una extensión de ggplot que permite generar gráficos con tests estadísticos. En este caso, la función ggbetweenstats() genera una la representación visual de las diferencias entre clusters según determinada variable.
El cluster 1 es el que incluye a la Ciudad de Buenos Aires. Se observa el promedio y mediana de cada componente en cada cluster, junto con la distribución y la cantidad de observaciones.
La función grouped_ggbetweenstats() implementa el test de Welch para cada una de las variables (en este caso, componente principal 1 y componente principal 2). Dados los p-valores es posible rechazar la hipótesis nula en favor de la alternativa: los segmentos son diferentes en función de los componentes. Además, se incluyen otros tests como el Games-Howell (pairwise_comparisons) con la corrección de Holm para evaluar las diferencias entre cada segmento. En este caso, sólo se incluyen los p-valores para diferencias significativas.
Show code
componentes %>% select(PC1,PC2) %>%
bind_cols(cluster=modelo_kmeans4$cluster) %>%
pivot_longer(-c('cluster')) %>%
grouped_ggbetweenstats(
x = cluster,
y = value,
xlab='Cluster', ylab='PC', k=2L, title.prefix='Variable',
grouping.var = name,
p.adjust.method = "holm",
pairwise.comparisons=TRUE,
bf.message=TRUE,
results.subtitle=TRUE,
plotgrid.args = list(nrow = 1),
annotation.args = list(title = "Diferencias entre clusters según PCA")
)
A continuación se incluyen las diferencias entre clusters según cada una de las variables consideradas, en valores originales (no estandarizados).
Show code
df_pca %>%
bind_cols(cluster=modelo_kmeans4$cluster) %>%
group_by(cluster) %>%
summarise_all(~mean(.)) %>%
pivot_longer(cols=-cluster, names_to = 'Variable') %>%
pivot_wider(names_from=cluster, values_from=value) %>%
mutate(across(where(is.numeric),~round(.,2))) %>%
gt() %>%
tab_header(md('**K-Medias:** Promedios por cluster'),
subtitle='Variables originales') %>%
opt_align_table_header('left') | K-Medias: Promedios por cluster | ||||
| Variables originales | ||||
| Variable | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| p_hac4_hog | 2.40 | 9.95 | 6.40 | 2.96 |
| p_casaB_hog | 7.39 | 63.63 | 33.72 | 12.09 |
| p_defclo_hog | 19.08 | 94.61 | 78.45 | 51.68 |
| p_jprimcom_hog | 29.90 | 77.88 | 63.59 | 54.37 |
| p_jsecinc_hog | 44.04 | 85.90 | 75.88 | 67.93 |
| p_n_noasist | 3.64 | 12.04 | 7.37 | 5.72 |
| p_def_sal2_per | 27.19 | 66.79 | 50.06 | 33.95 |
| p_pea | 56.13 | 33.10 | 41.11 | 49.42 |
| tamaño_hogares | 2.84 | 3.95 | 3.69 | 3.12 |
| p_viv_casa | 40.02 | 88.96 | 83.33 | 82.24 |
| p_viv_depto | 54.77 | 8.85 | 12.00 | 13.25 |
| p_viv_enconstruccion | 0.60 | 1.22 | 2.04 | 1.90 |
| p_viv_callesinnombre | 1.55 | 33.31 | 21.31 | 4.64 |
| p_viv_monoblock | 55.36 | 1.23 | 6.44 | 23.14 |
Show code
automagic_tabs <- function(input_data , panel_name, .output, .layout = NULL, ...){
#Capture extra arguments
list_arguments <- list(...)
.arguments <- names(list_arguments)
.inputs <- list_arguments %>% unlist() %>% unname()
parse_extra_argumnets <- NULL
if(!is.null(.arguments)) parse_extra_argumnets <- purrr::map2(.arguments,.inputs, ~paste(.x,.y, sep = " = ")
) %>% unlist() %>% paste(collapse=" , ")
#Capture name of data
data_name <- match.call()
data_name <- as.list(data_name[-1])$input_data %>% as.character()
#Layaout page
if(is.null(.layout)) .layout <- "l-body"
if(!.layout %in% c("l-body","l-body-outset","l-page","l-screen")) stop('the specified layout does not match those available. c("l-body","l-body-outset","l-page","l-screen")')
layaout_code <- paste0("::: {.",.layout,"}\n::: {.panelset}\n")
#knit code
knit_code <- NULL
for (i in 1:nrow(input_data)) {
#Capture time to diference same chunks
time_acual <- paste0(Sys.time() %>% lubridate::hour() %>% as.character(),
Sys.time() %>% lubridate::minute() %>% as.character(),
Sys.time() %>% lubridate::second() %>% as.character())
knit_code_individual <- paste0(":::{.panel}\n### `r ", data_name,"$",panel_name,"[[",i,
"]]` {.panel-name}\n```{r `r ", i,
time_acual,
"`, echo=FALSE, layout='",.layout,"', ",
parse_extra_argumnets,
"}\n\n ",data_name,"$",.output,"[[",i,
"]] \n\n```\n:::")
knit_code <- c(knit_code, knit_code_individual)
}
#layout code + knit code + close ::: :::
knit_code <- c(layaout_code,knit_code,"\n:::\n:::")
#knirt code
paste(knitr::knit(text = knit_code), collapse = '\n')
}Show code
df_clusters_vars <- df_pca %>%
bind_cols(cluster=modelo_kmeans4$cluster) %>%
rename(tamaño_hogares = tamaño_hogares)
ggbetweenstats_2 = function(var){
p = ggbetweenstats(df_clusters_vars,
x='cluster',
y=!!var)
return(p)
}
plots = data.frame(variable = df_clusters_vars %>%
select(-cluster) %>% names()) %>%
mutate(plot = map(.x=variable, ~ggbetweenstats_2(.x)))Se utiliza la función automagic_tabs() del paquete {sknifedatar} para visualizar diferencias según variables entre conglomerados.Notar que en el caso de p_viv_depto las diferencias entre grupos sólo son significativas entre cada conglomerado y el segmento 1 (para α=0.05).
p_hac4_hog
Show code
plots$plot[[1]] 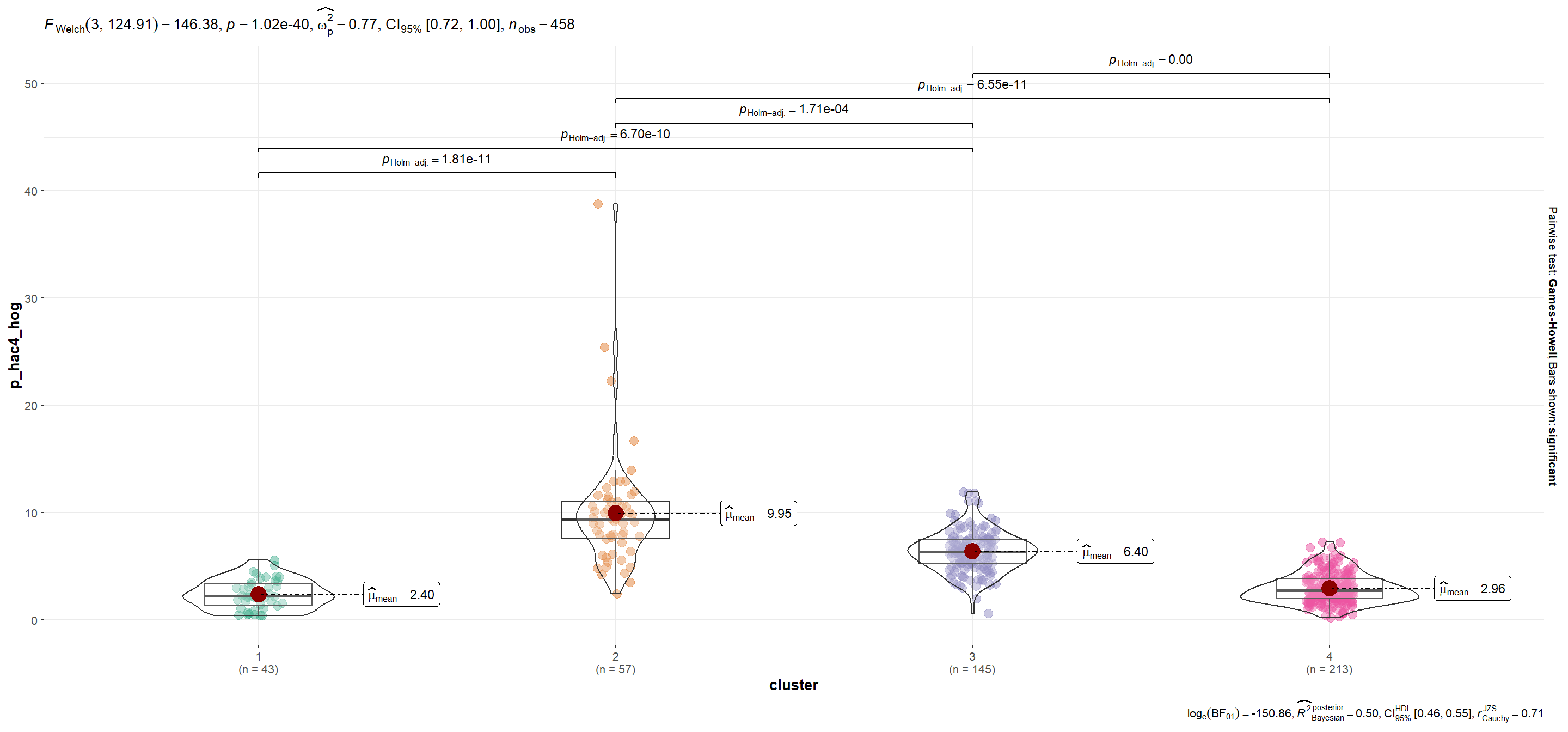
p_casaB_hog
Show code
plots$plot[[2]] 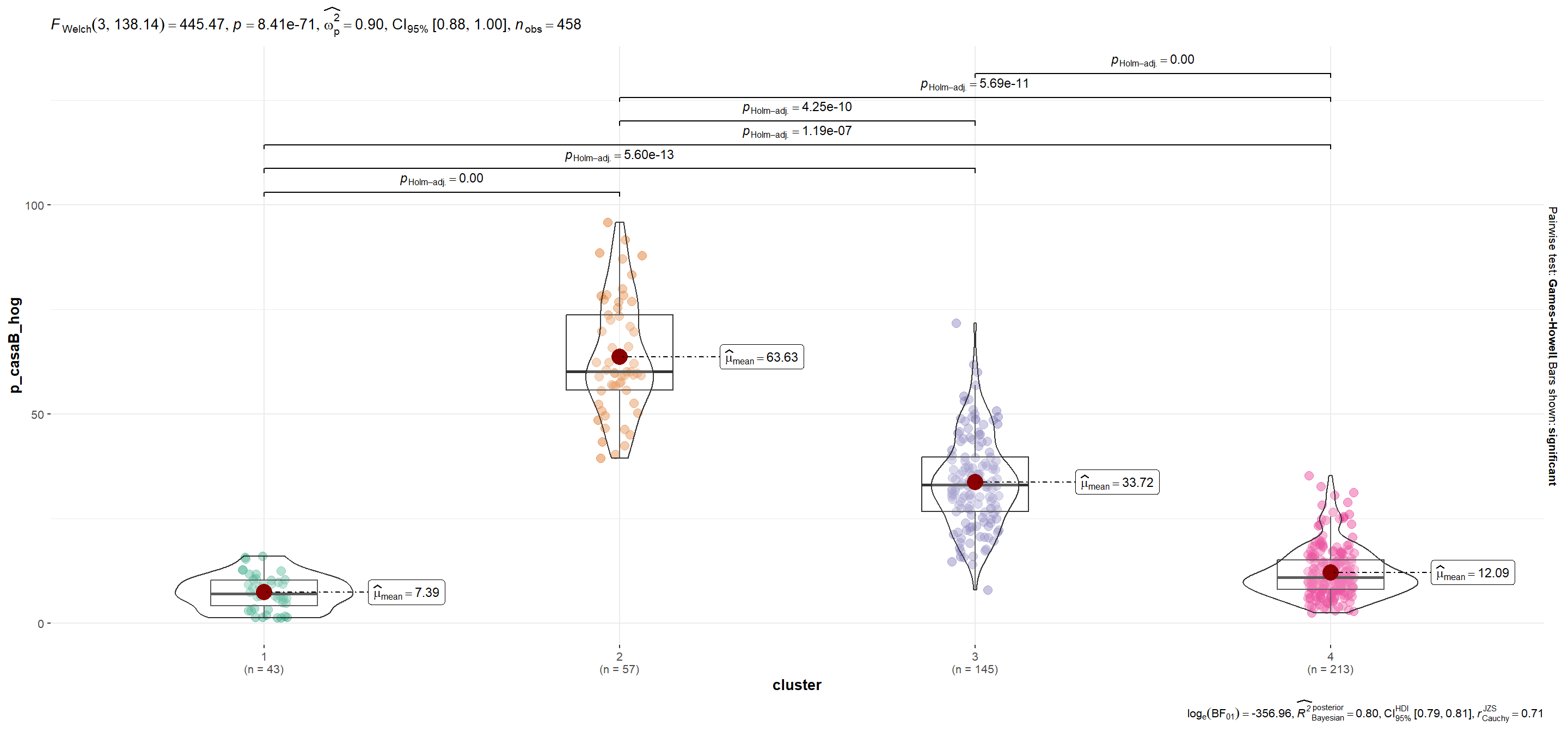
p_defclo_hog
Show code
plots$plot[[3]] 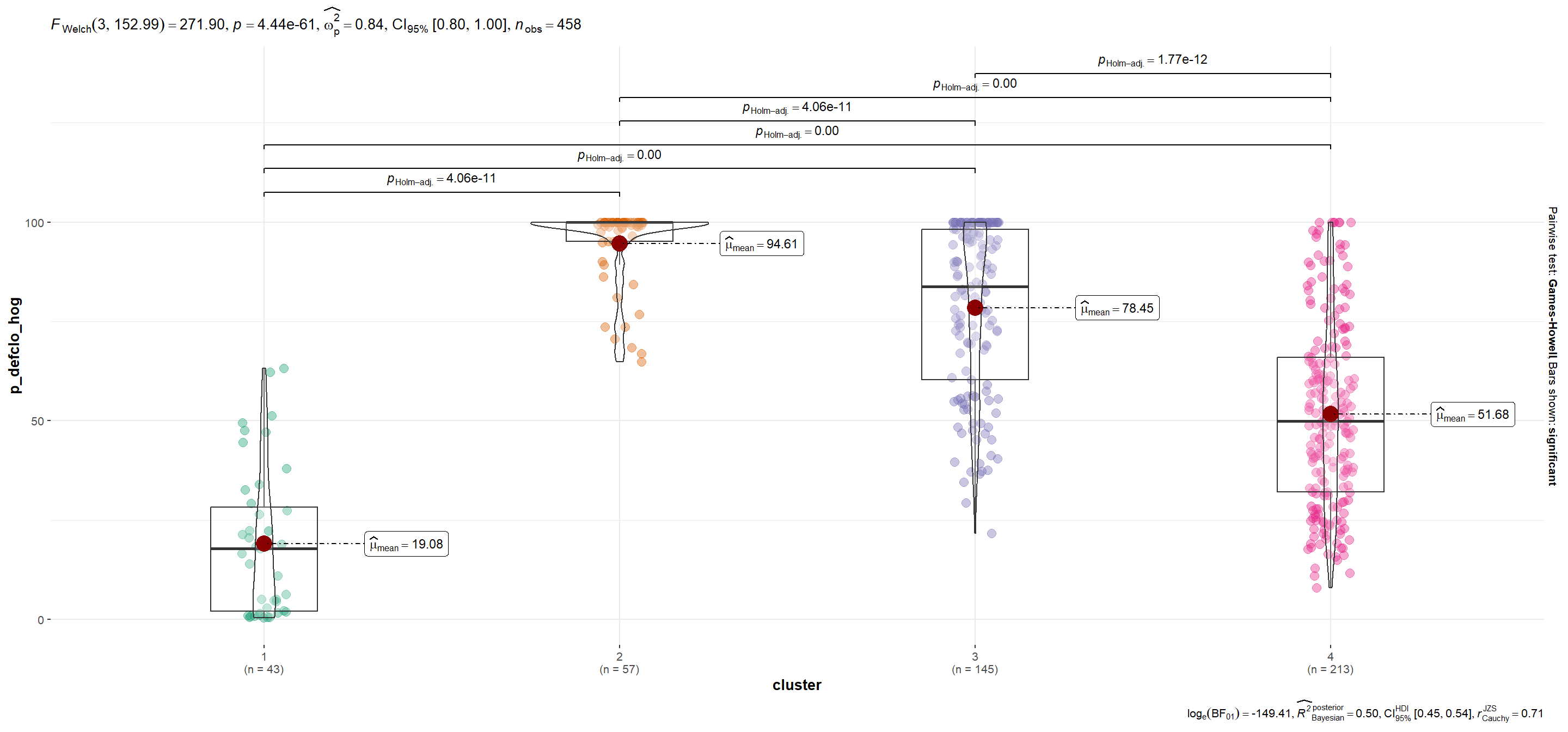
p_jprimcom_hog
Show code
plots$plot[[4]] 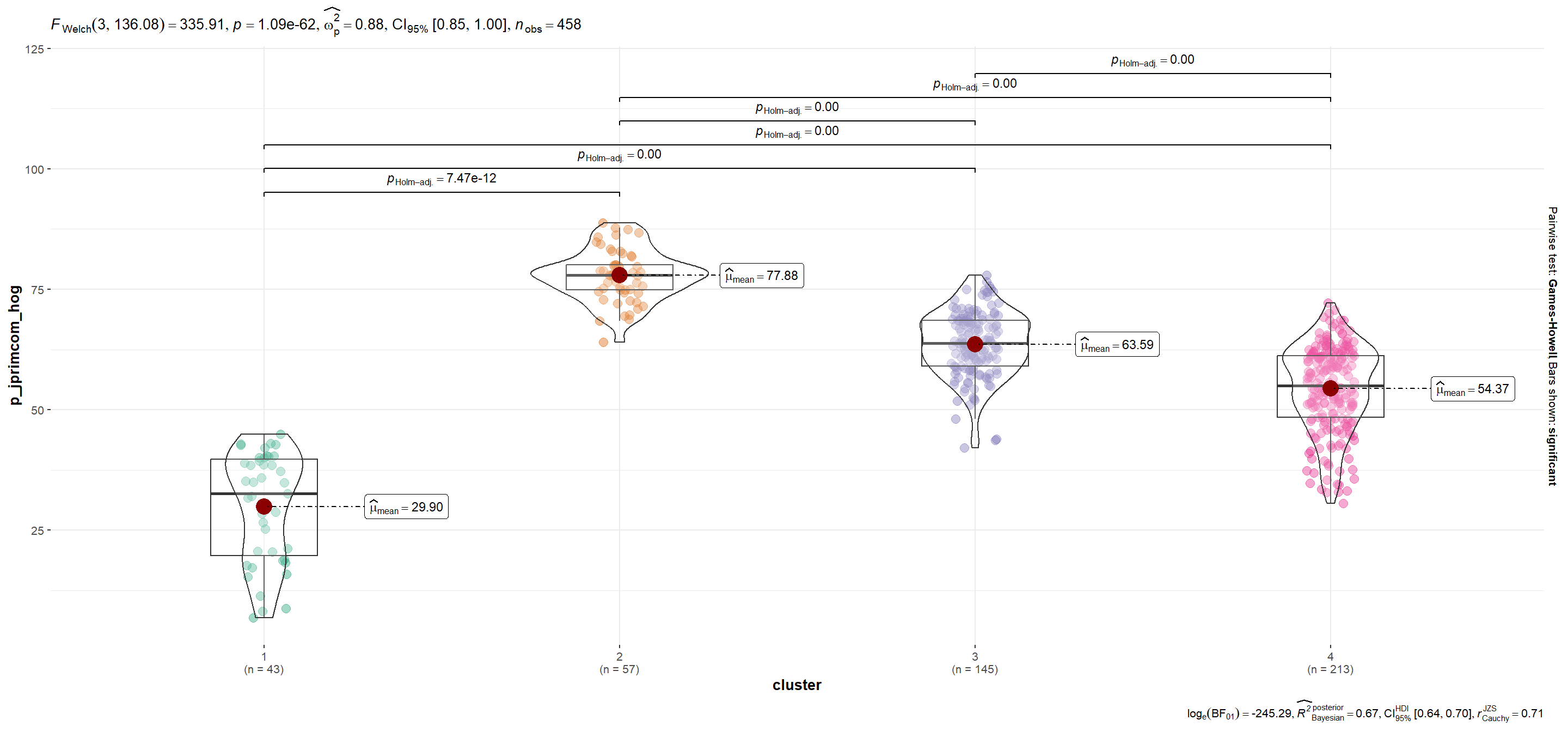
p_jsecinc_hog
Show code
plots$plot[[5]] 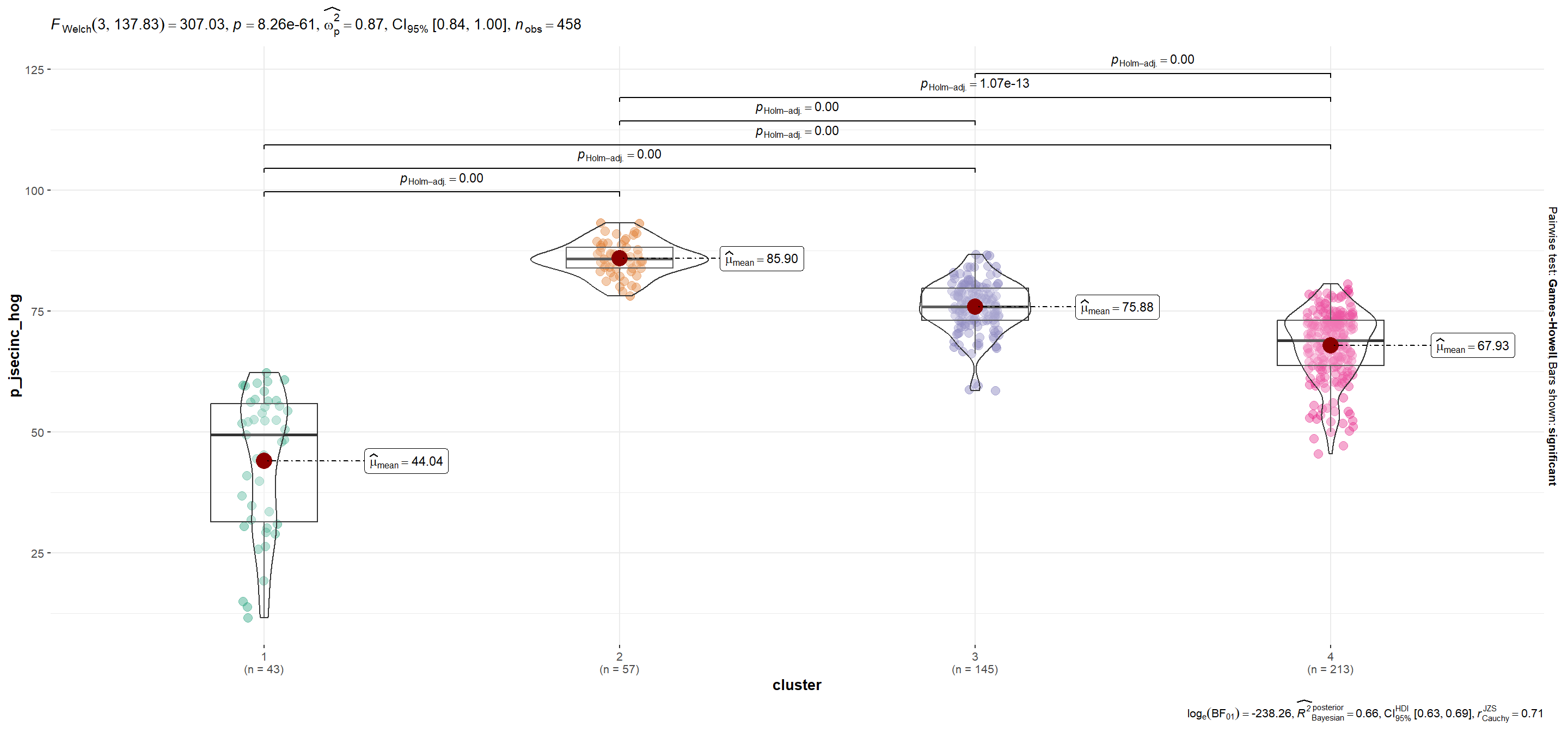
p_n_noasist
Show code
plots$plot[[6]] 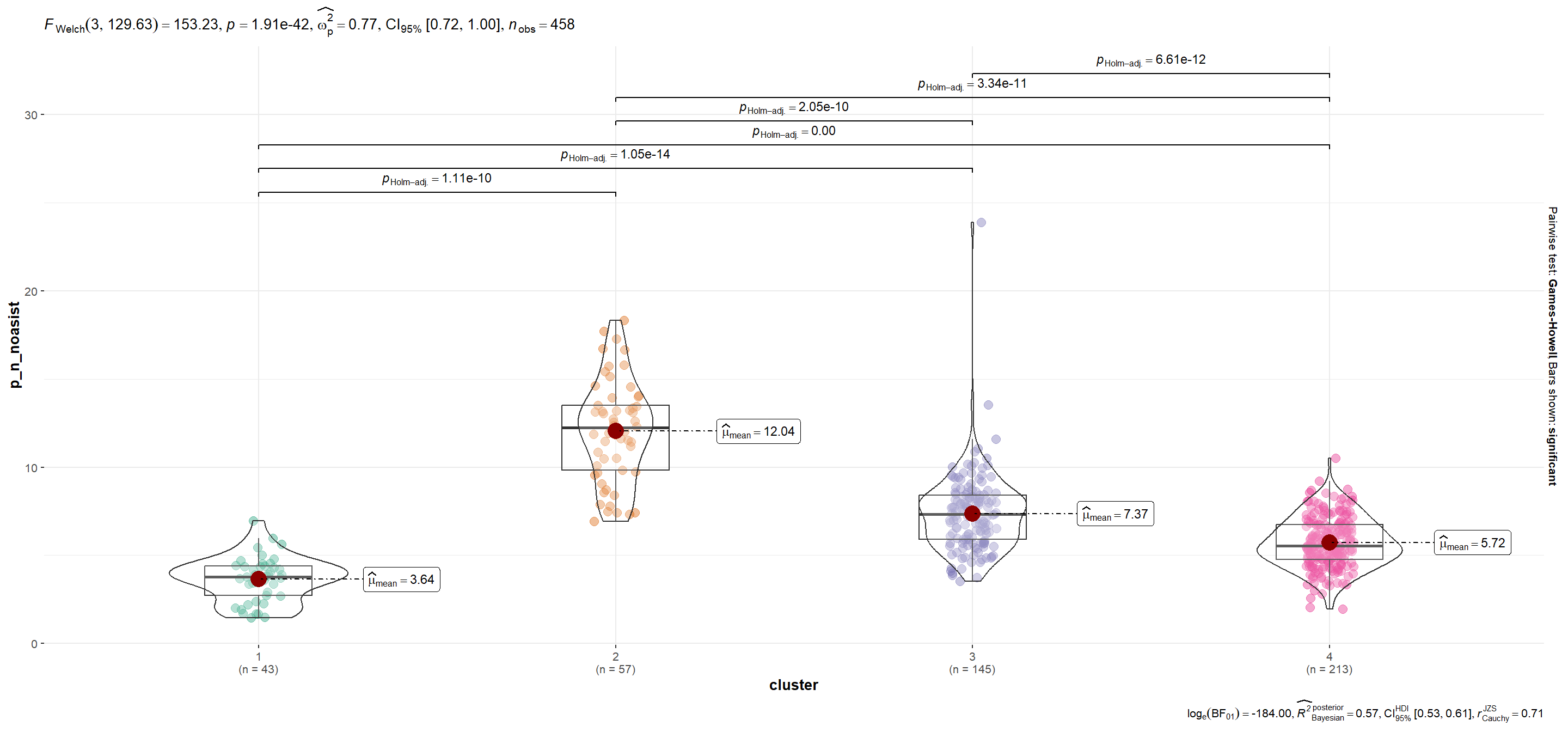
p_def_sal2_per
Show code
plots$plot[[7]] 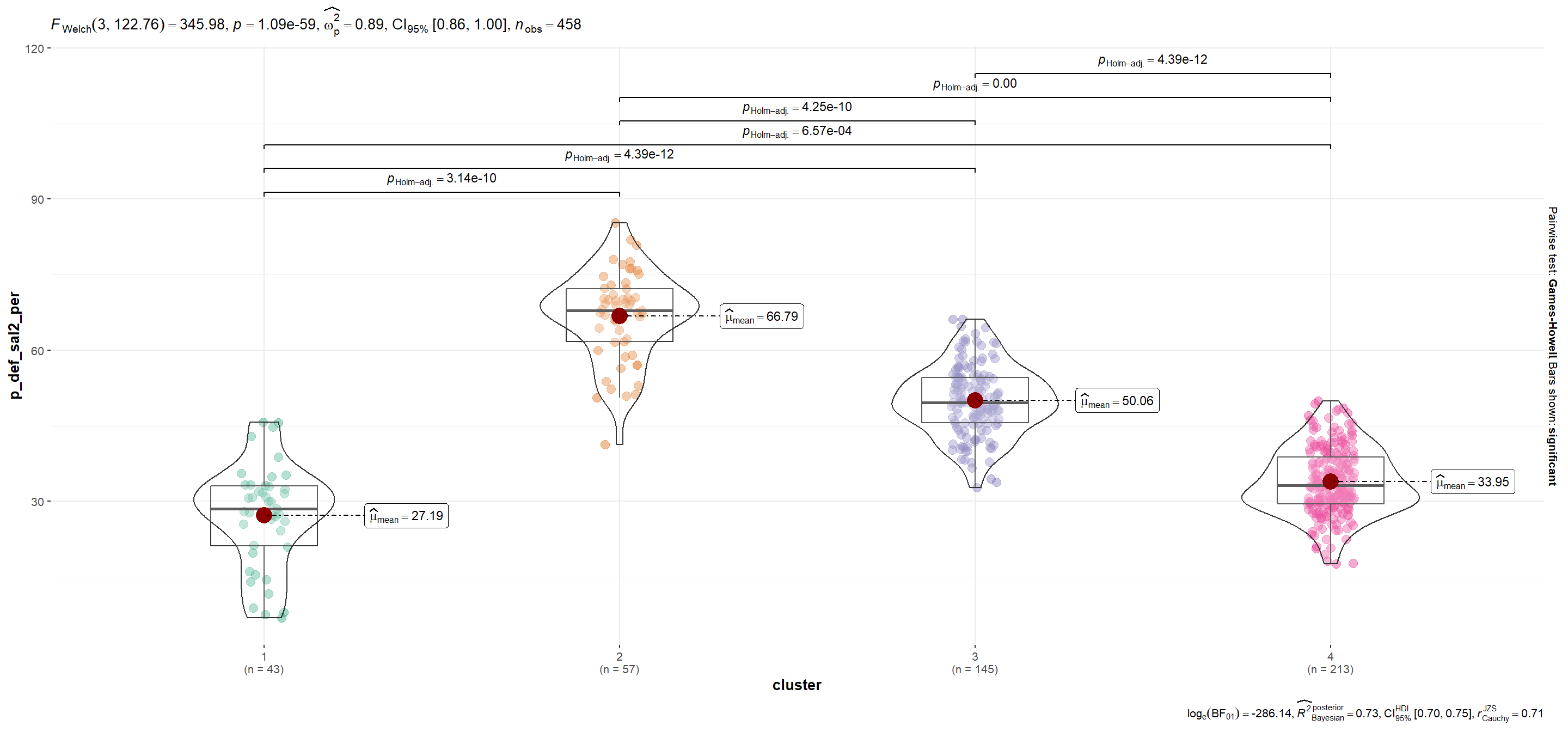
p_pea
Show code
plots$plot[[8]] 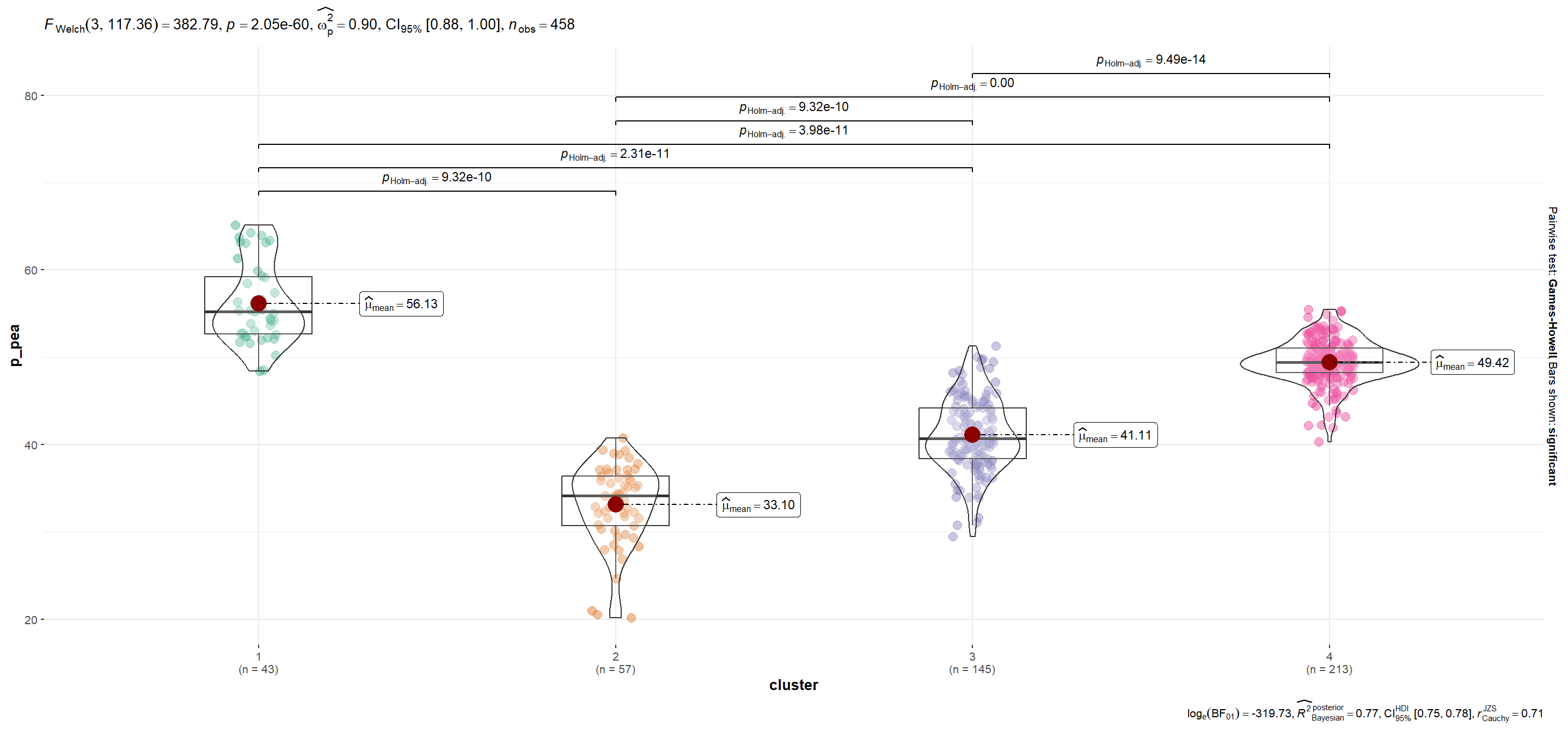
tamaño_hogares
Show code
plots$plot[[9]] 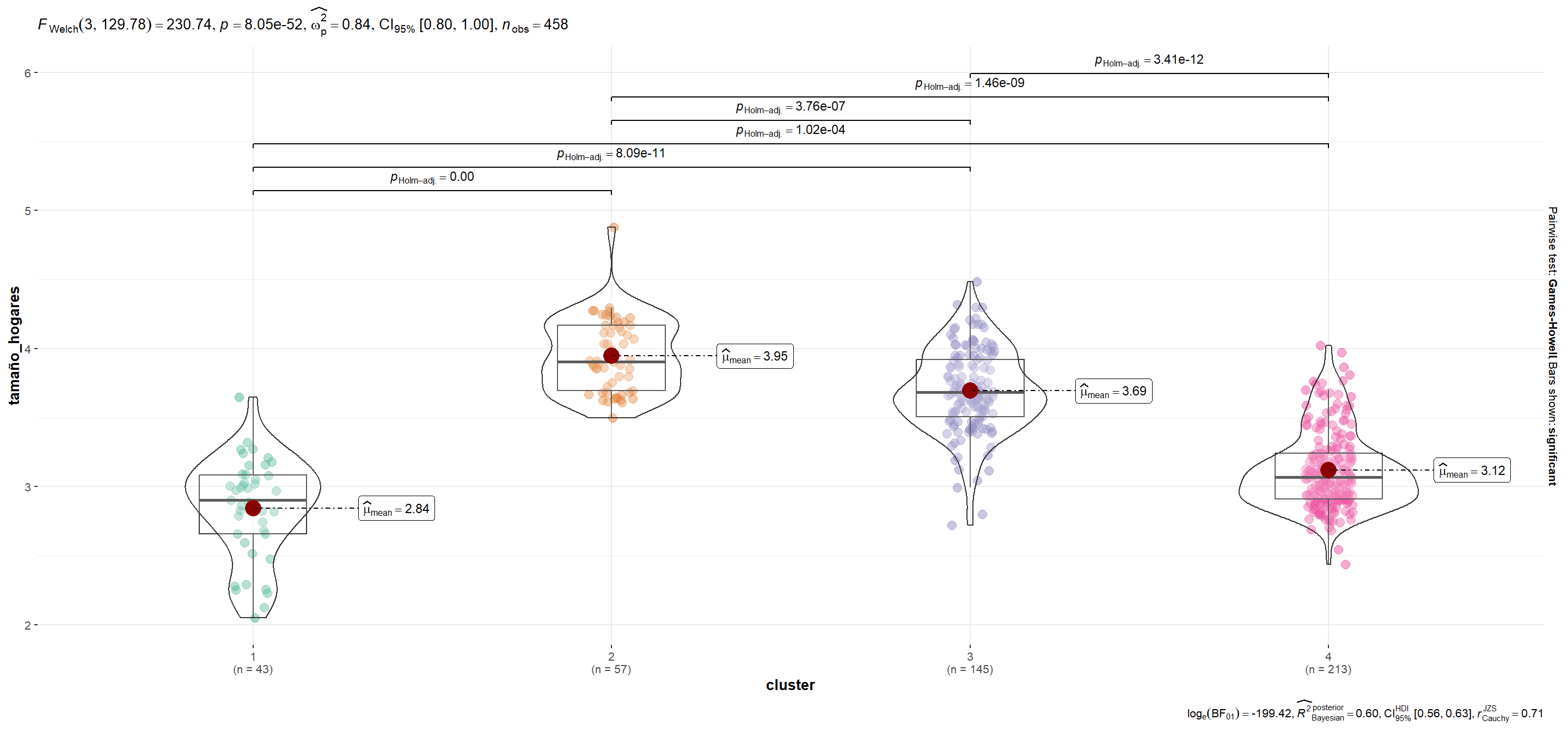
p_viv_casa
Show code
plots$plot[[10]] 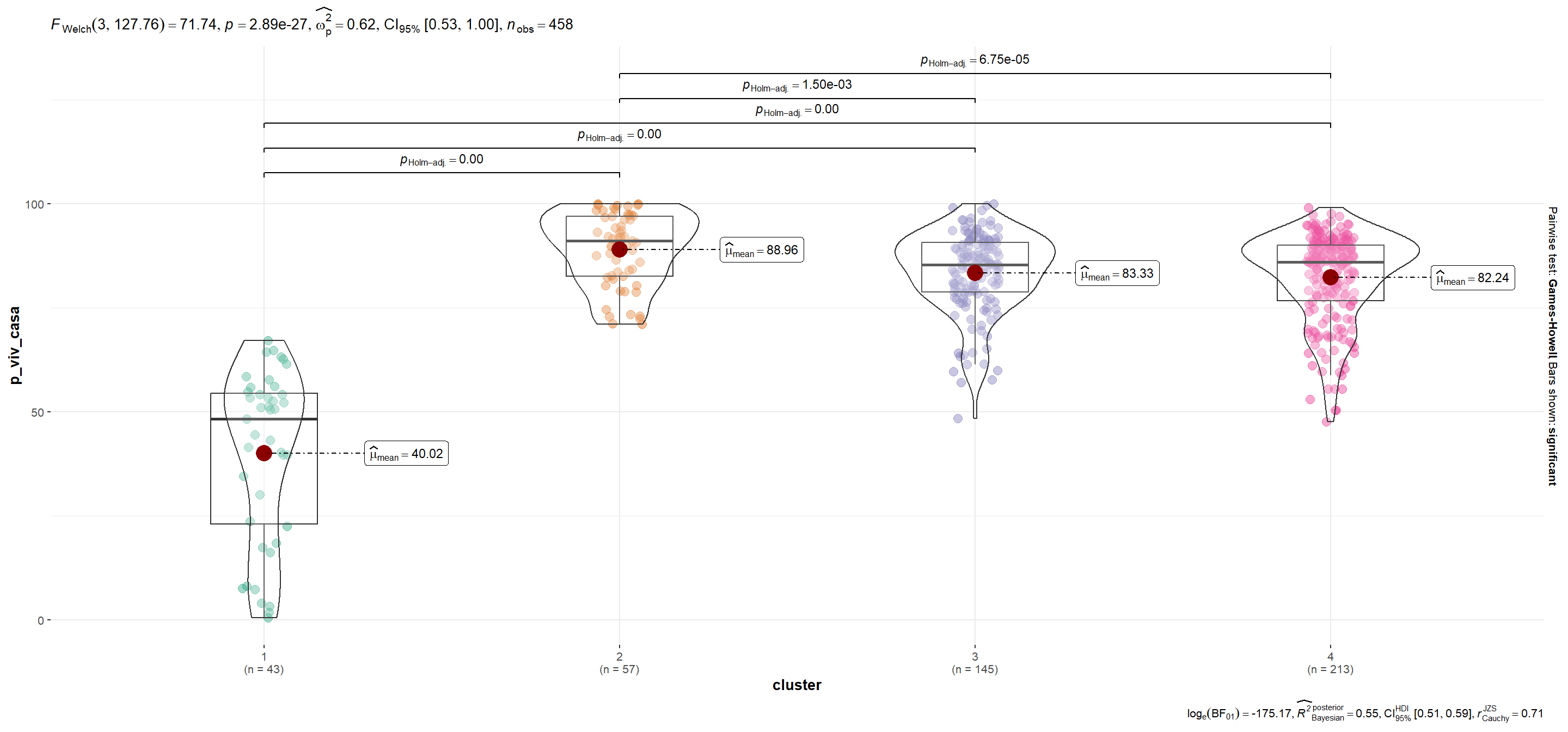
p_viv_depto
Show code
plots$plot[[11]] 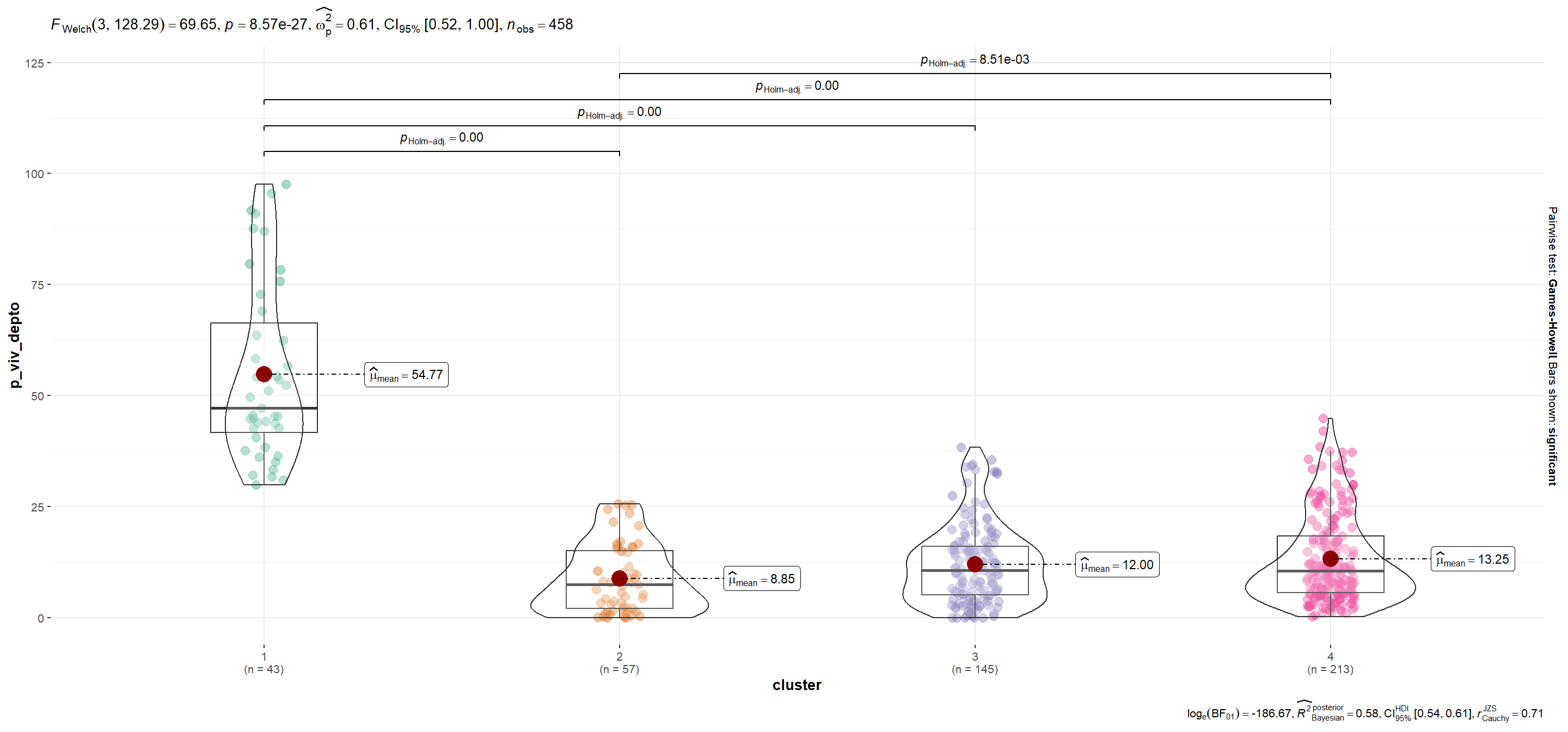
p_viv_enconstruccion
Show code
plots$plot[[12]] 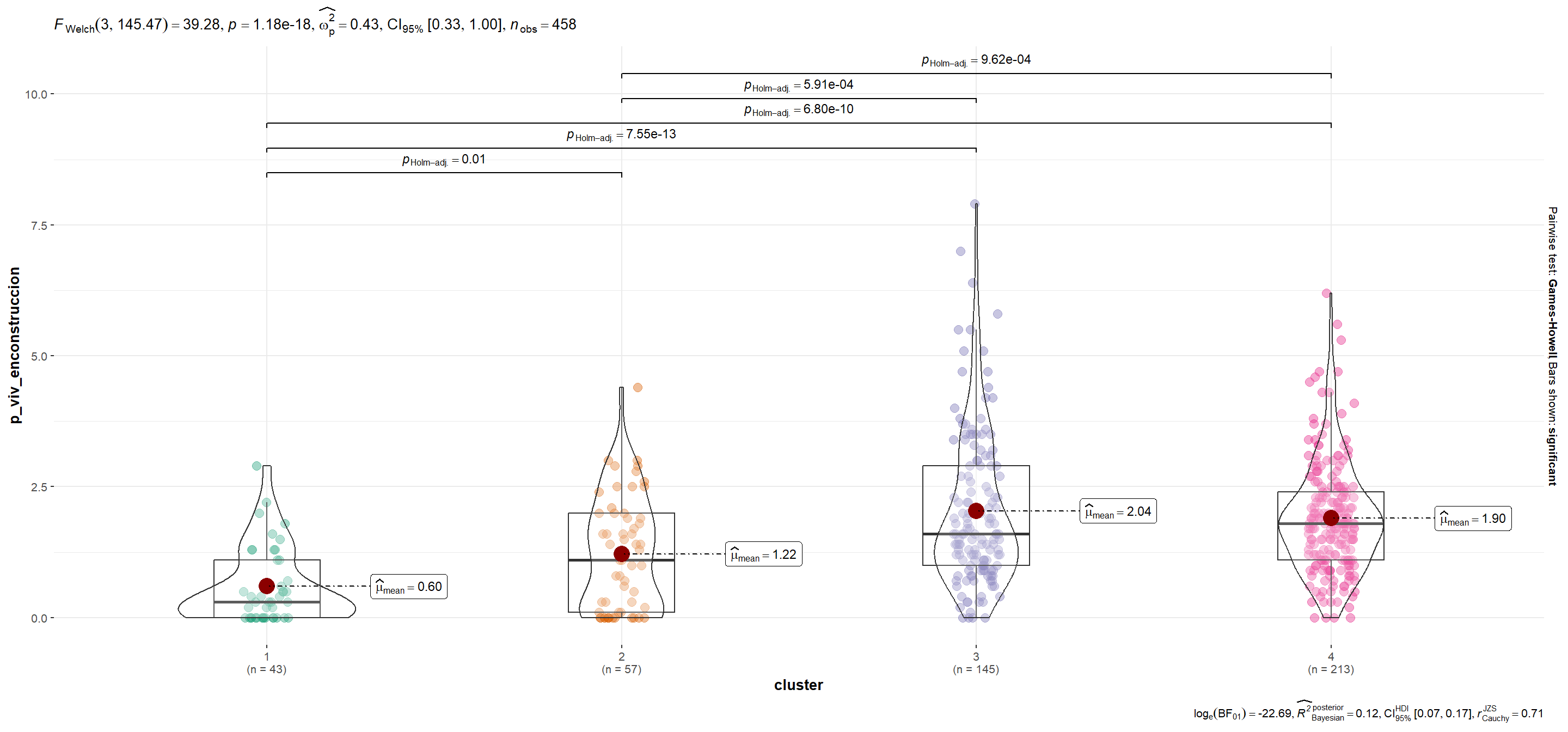
p_viv_callesinnombre
Show code
plots$plot[[13]] 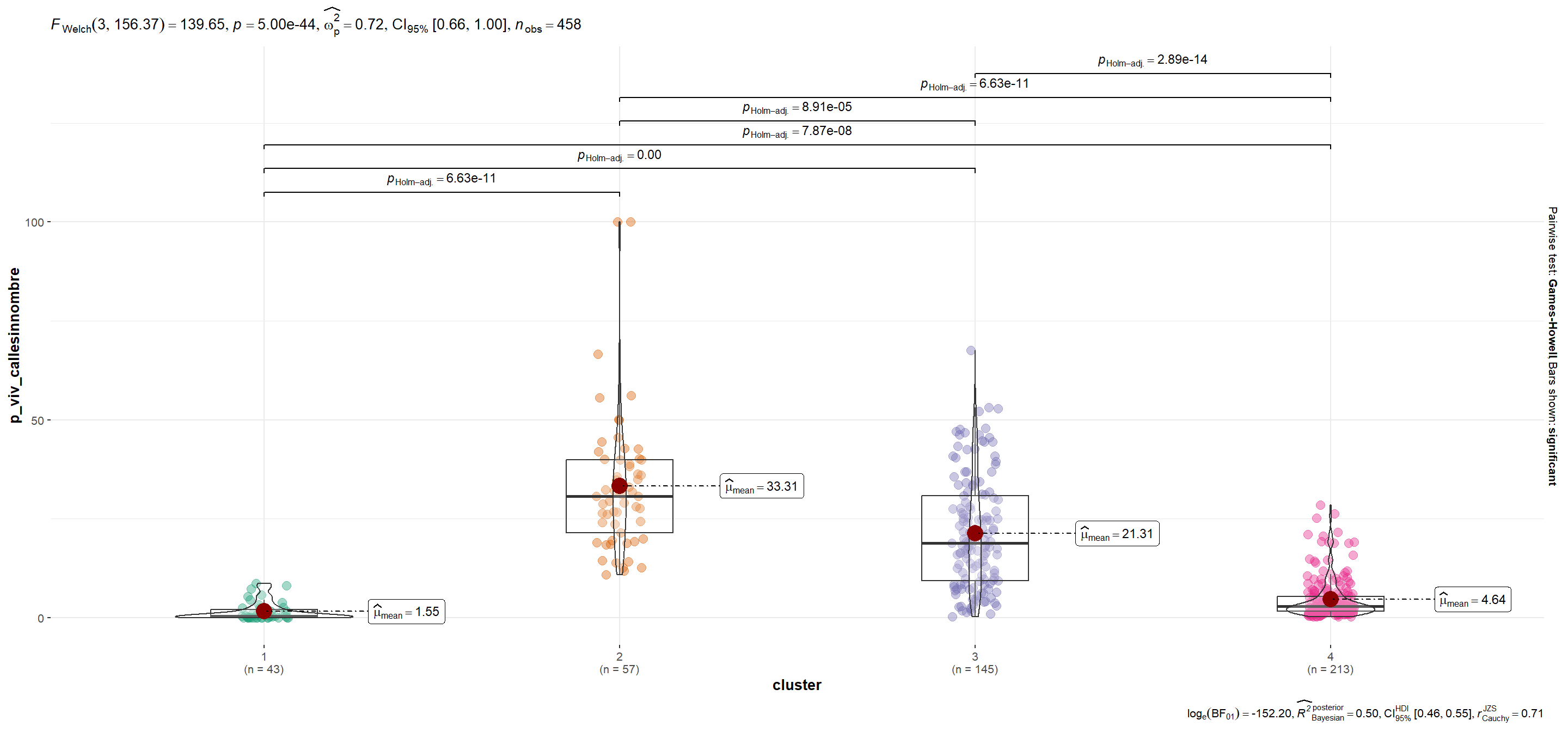
p_viv_monoblock
Show code
plots$plot[[14]] 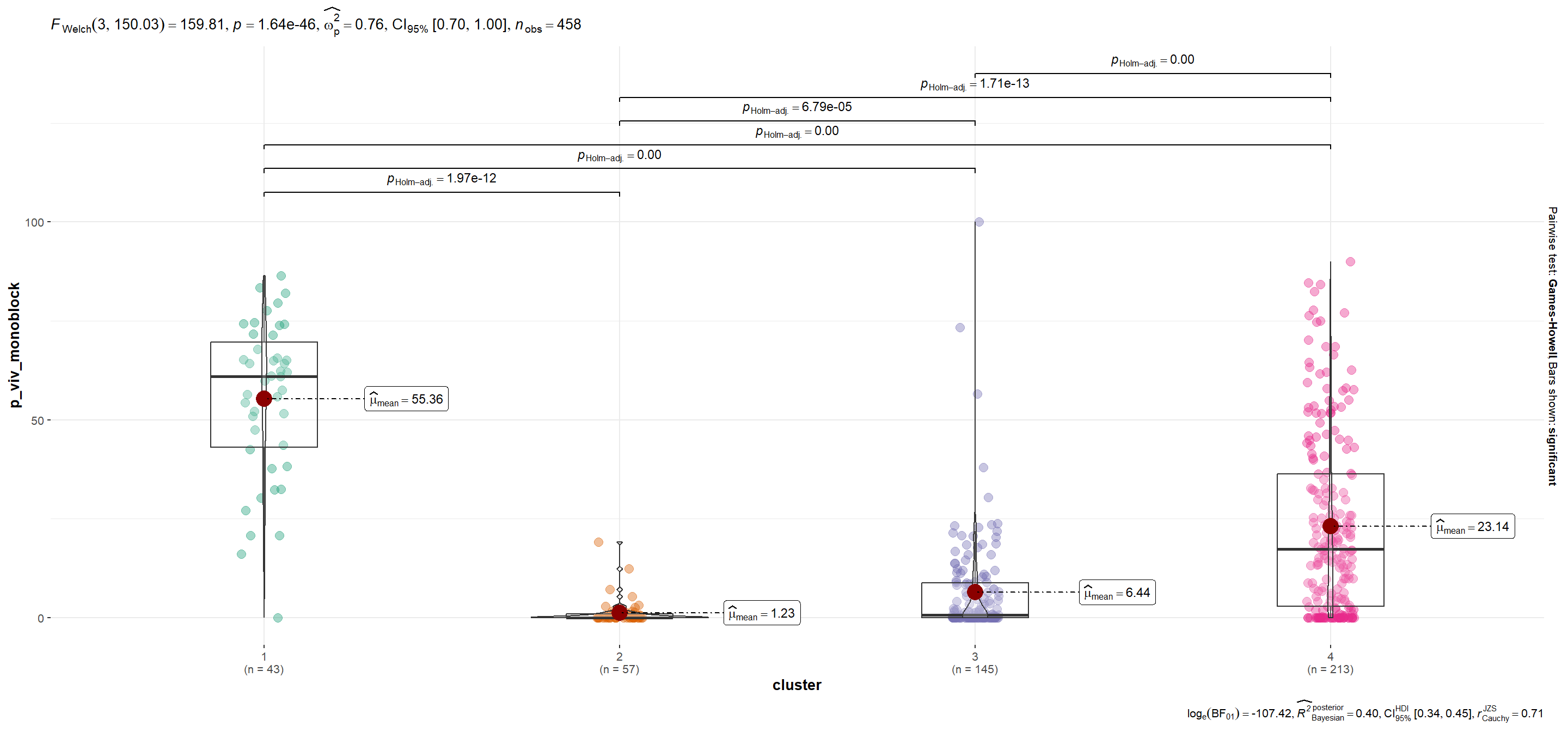
Los conglomerados generados presentan las siguientes características. Al visualizar las distribuciones de las variables se observa que en ciertos casos la media por conglomerado no es tan representativa del agrupamiento. Por ejemplo, en el caso de p_defecto_hog en el cluster 4.
Show code
data <- data.frame(
Cluster = c('Cluster 1', 'Cluster 2', 'Cluster 3', 'Cluster 4'),
Descripción = c(
'Mayor cantidad de departamentos en relación a casas. Con más población económicamente activa. Menores indicadores de pobreza (educación, calidad de los hogares y situación laboral). Incluye las 15 comunas de CABA, además de algunos departamentos del resto del país.',
'Es el cluster con peores condiciones en términos educativos y laborales, mayor porcentaje de hacinamiento y déficit habitacional. Es considerable el bajo porcentaje de población económicamente activa.',
'Elevados porcentajes de hacinamiento y malas condiciones laborales y educativas, aunque el Cluster 2 sigue siendo el cual presenta peores condiciones.',
'Elevado porcentaje de población económicamanete activa (aunque no tan alto como en el Cluster 1). Lo mismo ocurre con las condiciones educativas y laborales.')
)
kbl(data, booktabs = T) %>%
kable_styling(full_width = F) %>%
column_spec(1, bold = T, color = 'darkblue') %>%
column_spec(2, width = "30em")| Cluster | Descripción |
|---|---|
| Cluster 1 | Mayor cantidad de departamentos en relación a casas. Con más población económicamente activa. Menores indicadores de pobreza (educación, calidad de los hogares y situación laboral). Incluye las 15 comunas de CABA, además de algunos departamentos del resto del país. |
| Cluster 2 | Es el cluster con peores condiciones en términos educativos y laborales, mayor porcentaje de hacinamiento y déficit habitacional. Es considerable el bajo porcentaje de población económicamente activa. |
| Cluster 3 | Elevados porcentajes de hacinamiento y malas condiciones laborales y educativas, aunque el Cluster 2 sigue siendo el cual presenta peores condiciones. |
| Cluster 4 | Elevado porcentaje de población económicamanete activa (aunque no tan alto como en el Cluster 1). Lo mismo ocurre con las condiciones educativas y laborales. |
6. Analisis espacial
A continuación se presenta la comparación entre los departamentos representados por los 2 componentes principales y por los 4 conglomerados. En el caso de los componentes, se utiliza una escala bivariada para visualizarlos.
Show code
poligonos <- readOGR("departamentos_indec/pxdptodatosok.shp") %>%
spTransform(CRS("+proj=longlat +datum=WGS84 +no_defs +ellps=WGS84 +towgs84=0,0,0")) %>%
st_as_sf()
# Mapa de departamentos
df_deptos <- poligonos %>%
select(geometry, departamento=departamen,link) %>%
mutate(link=as.numeric(link)) %>%
left_join(componentes %>%
select(link=LINK_DEPTO, PC1, PC2), by='link') %>%
left_join(df_pca %>% bind_cols(cluster=modelo_kmeans4$cluster) %>%
tibble::rownames_to_column('link') %>%
mutate(link=as.numeric(link)), by='link')
data_biscale <- bi_class(df_deptos %>%
filter(!is.na(PC1)) %>% filter(link<94021),
x='PC1',y='PC2', style="quantile",dim=3)
# Mapa con biscale
mapa <- ggplot() +
geom_sf(data = poligonos %>% filter(link<94021),
fill='white', color='black',size=0.05 )+
geom_sf(data = data_biscale, mapping = aes(fill = bi_class),
color = 'black', size = 0.05, show.legend = FALSE) +
bi_scale_fill(pal = "DkBlue", dim = 3) +
labs(title = "Pobreza crónica y precenso de vivienda",
subtitle = "PCA sobre departamentos",
caption = "Fuente: CEDLAS, CIPPEC e INDEC") +
theme_void()+
theme(plot.caption = element_text(hjust = 0.2, size=12),
title=element_text(size=16))
# Legend
legend <- bi_legend(pal="DkBlue", dim=3,xlab="PC1", ylab="PC2", size=12)
ggdraw() + draw_plot(mapa, 0, 0, 1, 1) +
draw_plot(legend, 0.63, 0.05, 0.2, 0.2)
ggsave("plot_PCA.png",
plot=last_plot(), width = 22, height = 22, units = "cm")
df_pobreza <-
poligonos %>% select(geometry, departamento = departamen, link) %>%
mutate(link = as.numeric(link)) %>%
merge(
df_pobreza_cronica %>%
mutate(LINK_DEPTO = as.numeric(LINK_DEPTO)) %>%
select(link = LINK_DEPTO, p_pc_per, p_pc_hog),
by = 'link',
all.x = TRUE,
all.y = FALSE
)
data_biscale <- bi_class(df_pobreza %>% filter(link < 94021),
x='p_pc_per', y='p_pc_hog', style="quantile",dim=3)
# Mapa con escala bivariada: pobreza crónica por hogar/personas
mapa <- ggplot() +
geom_sf(data = poligonos %>% filter(link<94021),
fill='white', color='black',size=0.05 )+
geom_sf(data = data_biscale, mapping = aes(fill = bi_class),
color = "black", size = 0.05, show.legend = FALSE) +
bi_scale_fill(pal = "DkBlue", dim = 3) + theme_void()+
theme(plot.caption = element_text(hjust = 0.2, size=12),
title=element_text(size=16))+
labs(title = "Pobreza crónica por departamentos",
subtitle = "Hogares y población total bajo pobreza crónica(%)",
caption = "Fuente: CEDLAS, CIPPEC e INDEC")
# Legend
legend <- bi_legend(pal = "DkBlue", dim = 3,size = 12,
xlab = "Hogares (%)",
ylab = "Personas (%)")
#+ echo=TRUE, fig.width=10, message=FALSE
ggdraw() +
draw_plot(mapa, 0, 0, 1, 1) +
draw_plot(legend, 0.63, 0.05, 0.2, 0.2)
ggsave("plot_PobrezaCrónica.png",
plot=last_plot(), width = 22, height = 22, units = "cm")
# Mapa con escala bivariada: pobreza crónica por hogar/personas
mapa <- df_deptos %>% filter(link<94021) %>%
ggplot() +
geom_sf(aes(fill = as.factor(cluster)),
color = "black", size = 0.05, show.legend = TRUE) +
scale_fill_manual(values=c('#BE64AC','#3B4994','#A5ADD3','#5AC8C8','grey'))+
theme_void()+
theme(plot.caption = element_text(hjust = 0.2, size=12),
title=element_text(size=16))+
labs(title = "Conglomerados según características",
subtitle = "K-means",
caption = "Fuente: CEDLAS, CIPPEC e INDEC", fill='Cluster')
ggsave("plot_Clusters.png",
plot=last_plot(), width = 22, height = 22, units = "cm")Show code
knitr::include_graphics('images/plot_PCA.png')
knitr::include_graphics('images/plot_Clusters.png')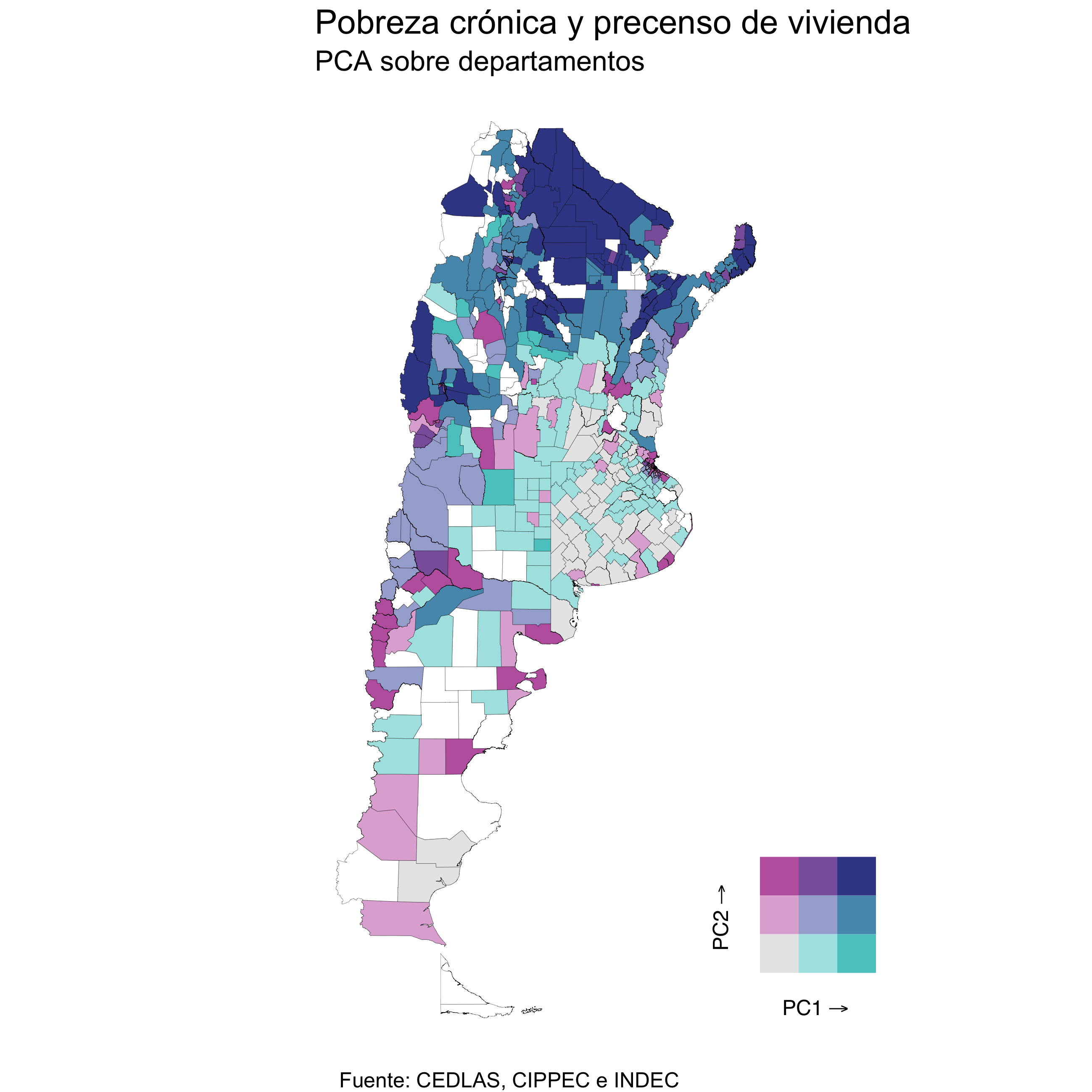
Se incluye la representación de la Argentina en términos de pobreza crónica (% de personas y hogares que viven bajo pobreza crónica). Estas variables no han sido incorporadas en el análisis dado que las mismas se generan en función del resto de las variables (modelo estimado por los autores en la publicación del CEDLAS).
Show code
knitr::include_graphics('images/plot_PobrezaCrónica.png')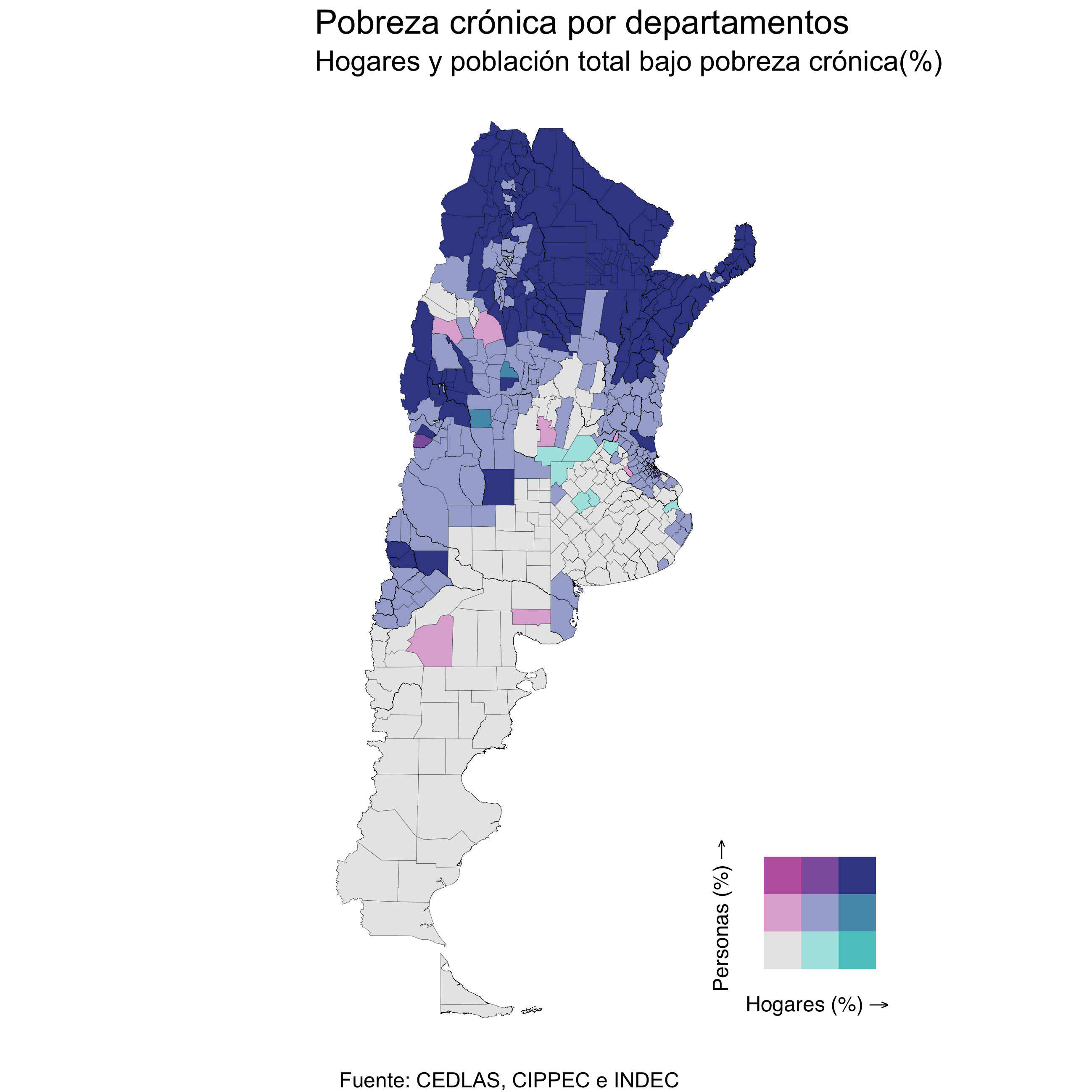
7. Comentarios finales
Se han utilizado dos métodos de análisis multivariado. El análisis de componentes principales permitió reducir la dimensionalidad a 2 componentes. Estos dos componentes fueron interpretados en función de las cargas factoriales y, gracias a los mismos, es posible visualizar los datos en un plano bidimensional.
Por otro lado, se realizó un análisis de conglomerados jerárquico con el objetivo de comprender cómo se van uniendo las provincias en función de sus características. Luego se analizaron conglomerados mediante el método de k-medias, obteniendo 4 grupos similares entre sí y diferentes del resto. Estos agrupamientos se generaron en función de las variables originales estandarizadas y se utilizan los dos componentes para visualizarlos.
Dado que los datos son geográficos, se incorporó un análisis espacial, representando los componentes principales, los conglomerados y las 2 variables de pobreza crónica en un mapa de Argentina.
8. Agradecimientos
El trabajo fue realizado para la materia Métodos de Análisis Multivariado en la Especialización en Métodos Cuantitativos para la Gestión y Análisis de Datos en Organizaciones (UBA). Agradezco a todo el esfuerzo de las profesoras Silvia Vietri y Silvina Del Duca en el dictado de las clases, comentarios y sugerencias sobre el trabajo.