⚠️ Antes de empezar …
Nos gusta la estadística, la matemática, la programación y trabajamos como científicos de datos 🤖, sin embargo, no somos expertos en el tema 🤷🏻. Estamos en un proceso constante de aprendizaje, siéntanse libres de plantear o comentar cualquier idea o sugerencia que consideren 📫 . Simplemente compartimos algo que con “suerte” les pueda servir 🙌🏻🙌🏻🙌🏻.
¿De que hablaremos en este post? 🔎
📌 El objetivo es mostrar la implementación de modelos de machine learning sobre datos de series de tiempo👌🏻, tomamos como ejemplo las series de Flujo vehicular por unidades de peaje AUSA en la Ciudad Autónoma de Buenos Aires 🚗 y del Estimador Mensual de Actividad Económica (EMAE) sectorial de Argentina ⚙️.
👉🏻 El mayor énfasis está puesto en mostrar el abanico de posibilidades que ofrece modeltime1 📦, desarrollado porMatt Dancho 👏🏻. Dicho paquete permimte modelar series de tiempo siguiendo la filosofía de tidymodels2 📦.Por lo tanto, se pasarán por alto algunas consideraciones técnicas propias de estas series. Puntualmente mostraremos de manera sencilla y didáctica (en la medida de lo posible 🤣) las siguientes aplicaciones:
Análisis de series de tiempo (descomposición, estacionalidad y autocorrelación).
Detección de anomalías en series de tiempo.
Ingeniería de variables en series de tiempo.
👉🏻 Ajuste de un modelo a una serie individual.
👉🏻 Ajuste de múltiples modelos a una serie individual.
👉🏻 Ajuste de múltiples modelos a múltiples series.
Selección del mejor modelo.
📝 Se comenzará ajustando un modelo a una serie de tiempo. Luego, se ajustarán múltiples modelos a esa misma serie, seleccionando el modelo que mejor se ajuste. Finalmente, se ajustarán múltiples modelos a múltiples series🙌🏻. El siguiente diagrama describe el esquema de análisis del artículo:
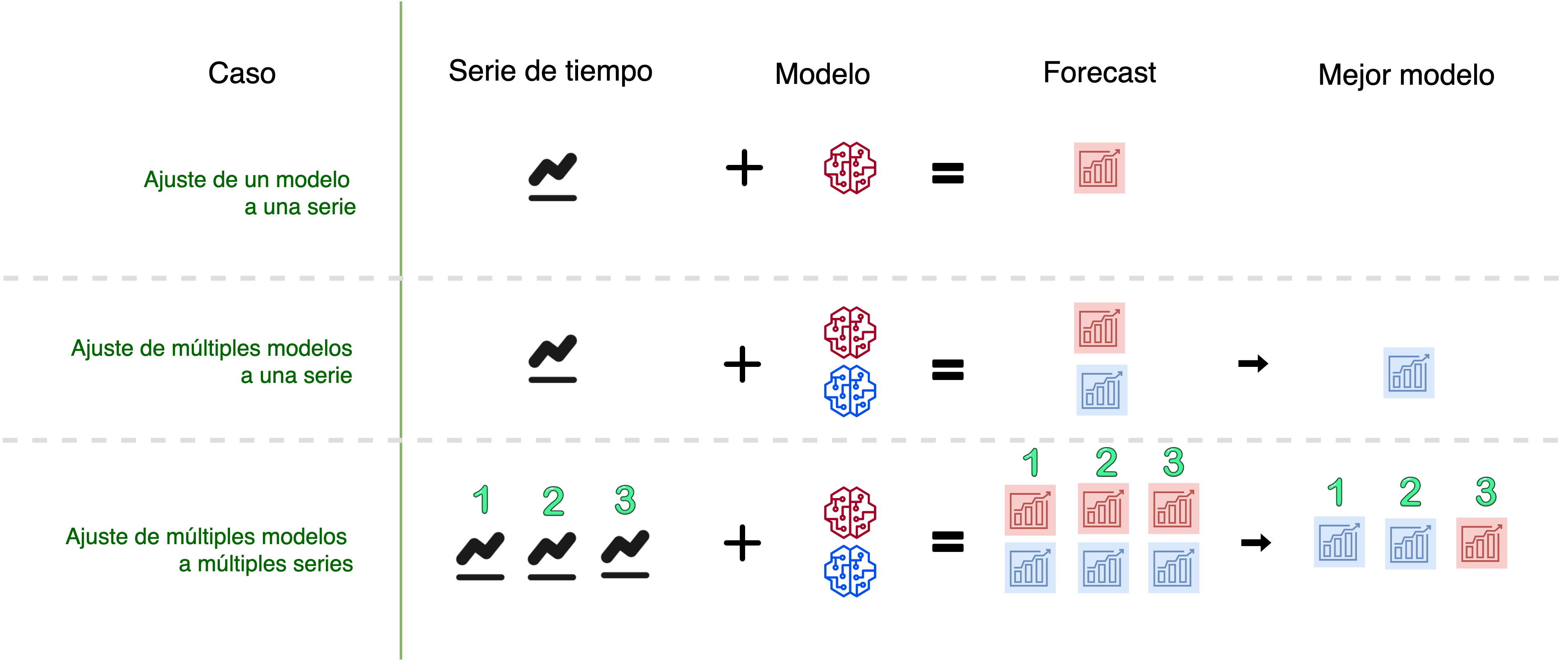
📌 Al momento de generar predicciones, el ejercicio propuesto es el siguiente: predecir cómo hubiera sido la evolución de la serie de no haber existido pandemia, realizando la posterior comparación con los datos observados.

👉🏻 Para estudiar en detalle todas las funcionalidades y casos de uso del framework, se recomienda consultar la Website de modeltime.
❗Bonus track: Creamos algunas funciones propias para automatizar ajustes, predicciones y evaluaciones de múltiples modelos en múltiples series 👌🏻. Todas ellas están almacenadas en el paquete sknifedatar3 📦.
Librerías 📚
A continuación, se cargan las librerías utilizadas para elaborar este post.
👉 Fueron creadas algunas funciones para el ajuste y predicción de múltiples series 🙌, también se recopilaron fuentes de datos que posteriormente se transformaron en series de tiempo. Todas estos datasets y funciones se almacenaron en el paquete sknifedatar 📦, A continuación se muestra la sintaxis para su instalación:
devtools::install_github("rafzamb/sknifedatar")
Ajuste de un modelo a una serie individual 📈
Para el primer caso analizaremos datos de Flujo Vehicular por Unidades de Peaje AUSA en la Ciudad Autónoma de Buenos Aires4 🚗 . Vamos a trabajar con datos circulación de vehículos livianos en el peaje Avellaneda. El objetivo de esta primera sección es mostrar una introducción al uso del paquete modeltime.
El flujo de trabajo será el siguiente:
Datos
Modelo
Forecast
Datos 📊
Los siguientes datos corresponden a series de flujo de circulación vehicular 🚙 por día durante el período 2009-2020. Estos datos se encuentran disponibles en el paquete sknifedatar 📦 y pueden utilizarse mediante la siguiente sintaxis.
df_avellaneda <- sknifedatar::data_avellaneda %>%
mutate(date=as.Date(date))
Show code
df_avellaneda %>%
head(5) %>%
gt() %>%
tab_header(title='Flujo vehicular diario',
subtitle='Estación Avellaneda') %>%
tab_footnote(
footnote = "Fuente: GCBA",
locations = cells_column_labels(columns = vars(value)))
| Flujo vehicular diario | |
|---|---|
| Estación Avellaneda | |
| date | value1 |
| 2009-01-01 | 76167 |
| 2009-01-02 | 102293 |
| 2009-01-03 | 81249 |
| 2009-01-04 | 79140 |
| 2009-01-05 | 123039 |
|
1
Fuente: GCBA
|
|
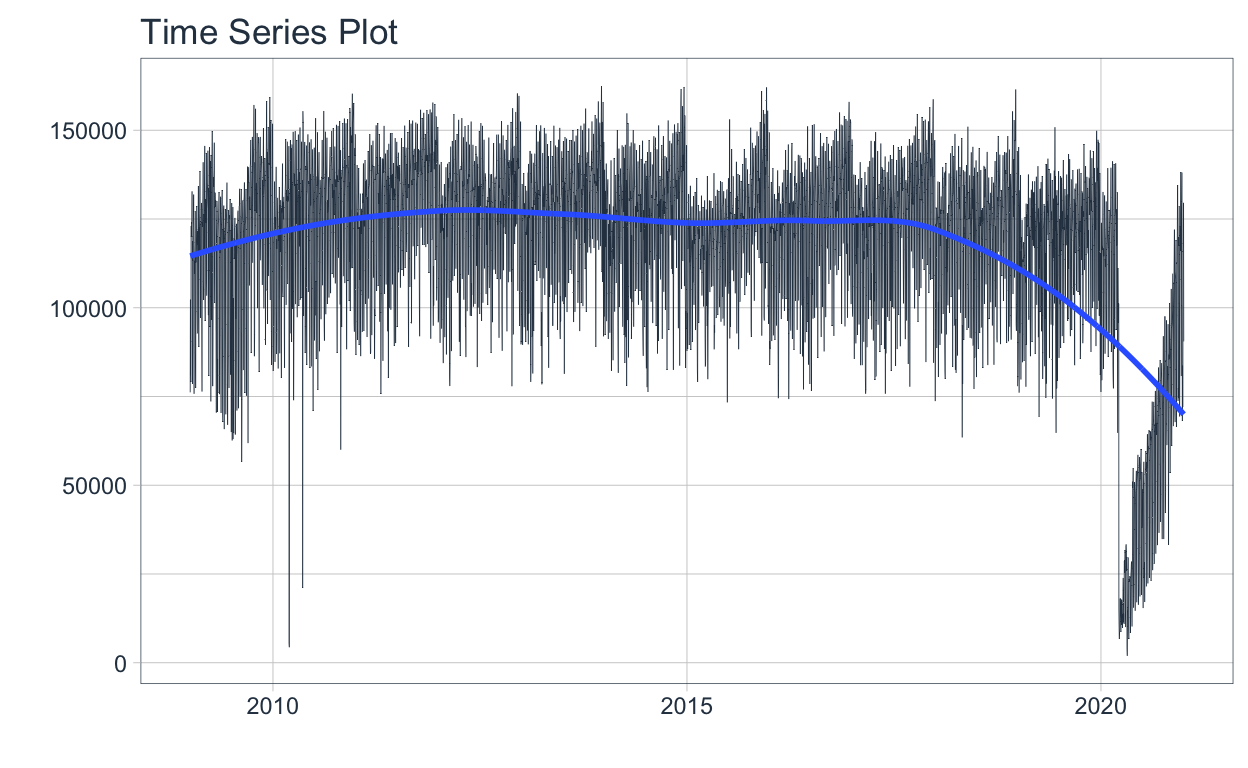
👀 Visualizando estos datos se puede observar las variaciones diarias y una fuerte caída durante la pandemia.
df_avellaneda %>%
plot_time_series(.date_var = date,
.value = value,
.interactive = FALSE,
.line_size = 0.15)
Modelo 🚀

A continuación se ajustará un modelo sobre estos datos, realizando previamente una partición temporal de la serie en train y test. Finalmente 🧙 se proyectará qué hubiera pasado en caso de no haber existido pandemia.
Partición en train y test
🔹Primero se realiza un filtro para considerar sólo datos previos al 2020 (considerando 2020 como un año atípico). Luego, mediante la función initial_time_split() ✂️ se genera una partición temporal de los datos 📆, siendo los últimos meses los datos de evaluación. Utilizando un umbral del 80%, 3213 observaciones (días) corresponden al dataset de entrenamiento y 804 al de evaluación.
df_avellaneda_model <- df_avellaneda %>%
filter(date<'2020-01-01')
splits_transporte <- initial_time_split(
data = df_avellaneda_model,
prop = 0.8)
splits_transporte
<Analysis/Assess/Total>
<3213/804/4017>
Modelo prophet
🔹 Se define la especificación del modelo a utilizar. En este caso, se utiliza el modelo Prophet, un modelo muy conocido desarrollado por Facebook .
prophet_reg(mode='regression')
PROPHET Regression Model Specification (regression)🔹 Se define el algoritmo desde el cuál se utiliza el modelo:
prophet_reg(mode='regression') %>%
set_engine('prophet')
PROPHET Regression Model Specification (regression)
Computational engine: prophet 🔹 Se ajusta el modelo a los datos de entrenamiento. Se agrega un fit al modelo luego del “%>%” , especificando la data para ajustar y las variables a predecir: “value ~ date” significa que la variable dependiente es value (cantidad de vehículos) y la independiente “~” es date (fecha).
m_prophet_transporte <-prophet_reg(mode='regression') %>%
set_engine('prophet') %>%
fit(value~date, data = training(splits_transporte))
m_prophet_transporte
parsnip model object
Fit time: 2s
PROPHET Model
- growth: 'linear'
- n.changepoints: 25
- changepoint.range: 0.8
- yearly.seasonality: 'auto'
- weekly.seasonality: 'auto'
- daily.seasonality: 'auto'
- seasonality.mode: 'additive'
- changepoint.prior.scale: 0.05
- seasonality.prior.scale: 10
- holidays.prior.scale: 10
- logistic_cap: NULL
- logistic_floor: NULL
- extra_regressors: 0Forecast
🔹 Utilizando el modelo ajustado, se procede a generar predicciones 🔮 sobre la partición de evaluación para posteriormente compararlas con los valores observados. Esto permite generar intervalos de confianza para las proyecciones y también obtener métricas de evaluación del modelo.
calibrate_transporte <- m_prophet_transporte %>%
modeltime_table() %>%
modeltime_calibrate(new_data=testing(splits_transporte))
calibrate_transporte
# Modeltime Table
# A tibble: 1 x 5
.model_id .model .model_desc .type .calibration_data
<int> <list> <chr> <chr> <list>
1 1 <fit[+]> PROPHET Test <tibble [804 × 4]>🔹 Se utiliza la función modeltime_forecast() para proyectar la serie. Se deben indicar los datos actuales ‘actual_data’, que son los datos observados.
Algunas cuestiones a tener en cuenta:
Si se quiere realizar una proyección en datos futuros 🔮 se debe utilizar ‘h’ indicando cuántos períodos se quiere proyectar.
‘new_data’ permite pasar un dataframe para el cual se quiere predecir el valor.En este caso utilizaremos esta última opción dado que no estamos intentando proyectar al futuro ☝️.
La opción ‘new_data’ también sirve el caso en que el modelo se base en datos externos (clima 🌦️ por ejemplo). Si se entrena un modelo de serie de tiempo con una variable que no sea una transformación de la fecha 📅, necesariamente luego se debe indicar el forecast de clima para que el modelo haga la predicción.
forecast_transporte <- calibrate_transporte %>%
modeltime_forecast(
new_data = testing(splits_transporte),
actual_data = df_avellaneda_model
)
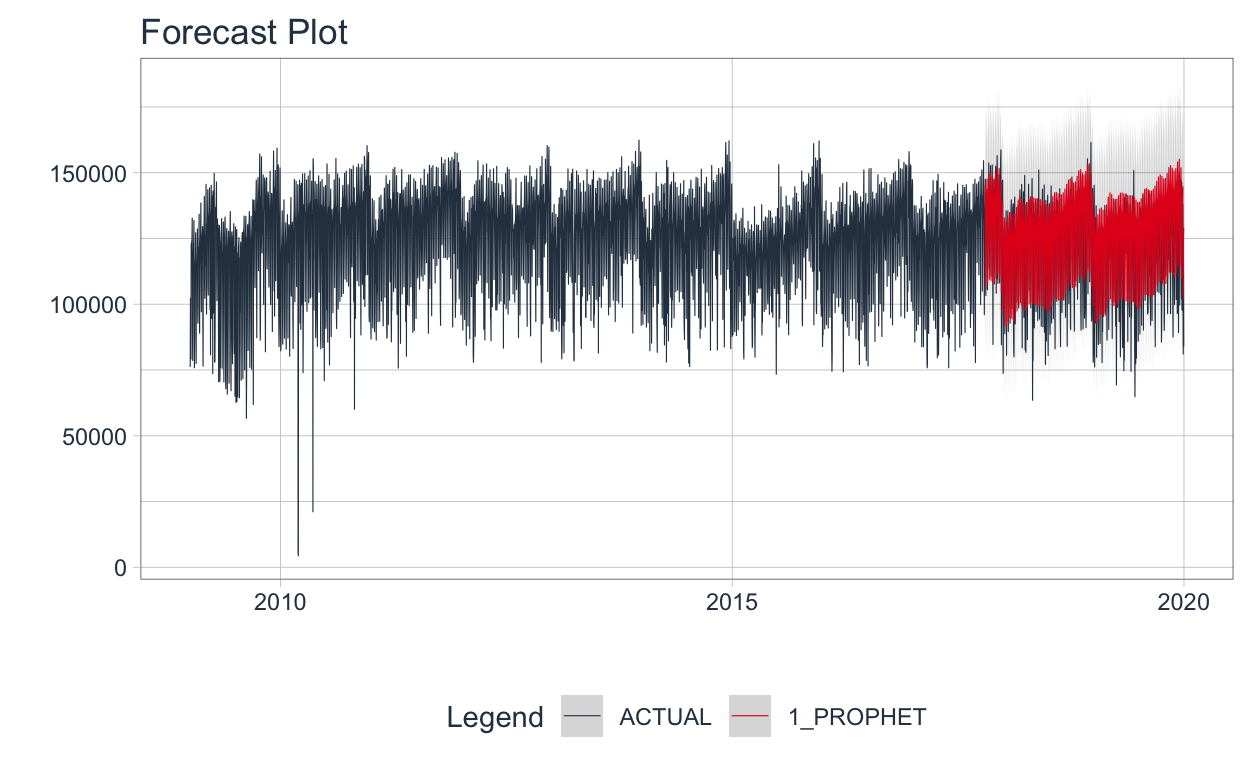
🔹 Para visualizar las proyecciones, se utiliza la función plot_modeltime_forecast.
forecast_transporte %>%
plot_modeltime_forecast(
.legend_max_width = 30,
.interactive = FALSE,
.conf_interval_alpha = 0.2,
.line_size=0.2
)
Con la función modeltime_accuracy() se pueden visualizar las métricas de este modelo 🧪. En las secciones posteriores se pueden encontrar más detalles sobre estas métricas de evaluación.
calibrate_transporte %>%
modeltime_accuracy() %>%
gt() %>% tab_header('Métricas de evaluación')
| Métricas de evaluación | ||||||||
|---|---|---|---|---|---|---|---|---|
| .model_id | .model_desc | .type | mae | mape | mase | smape | rmse | rsq |
| 1 | PROPHET | Test | 10221.62 | 9.599925 | 0.6529679 | 8.682989 | 15050.78 | 0.4347735 |
Ingeniería de variables 🛠️
🔹 La creación de variables es uno de los aspectos fundamentales en modelos series de tiempo. A través del paquete recipes5 📦 podemos realizar una gran variedad de transformaciones en forma simple y organizada. Este es uno de los principales paquetes incluidos en tidymodels.
A continuación se muestran algunos ejemplos de cómo funciona este paquete.
- 🌮 Receta para predecir el valor en función de la fecha:
Se añade un paso para obtener mes, trimestre y año como variables, utilizando step_date(). Luego, otro paso (step_lag()) nos permite generar un rezago de la variable a predecir (value), tomando el valor un día antes de la fecha en cuestión.
Show code
receta_transporte %>%
prep() %>% juice() %>% head(3) %>% gt() %>%
tab_header('Datos luego de añadir variables de fecha y 1 rezago')
| Datos luego de añadir variables de fecha y 1 rezago | |||||
|---|---|---|---|---|---|
| date | value | date_month | date_quarter | date_year | lag_1_value |
| 2009-01-01 | 76167 | Jan | 1 | 2009 | NA |
| 2009-01-02 | 102293 | Jan | 1 | 2009 | 76167 |
| 2009-01-03 | 81249 | Jan | 1 | 2009 | 102293 |
❗En el caso anterior el primer valor de lag_1_value es nulo debido a que no hay observaciones anteriores a esa fecha para buscar el valor anterior. Por esta razón, se puede incorporar un nuevo paso (step_ts_impute()) para imputar valores nulos en series temporales:
receta_transporte <- receta_transporte %>%
step_ts_impute(all_numeric(), period=365)
Show code
receta_transporte %>%
prep() %>% juice() %>% head(3) %>% gt() %>%
tab_header('Datos luego de imputar de valores nulos en series temporales')
| Datos luego de imputar de valores nulos en series temporales | |||||
|---|---|---|---|---|---|
| date | value | date_month | date_quarter | date_year | lag_1_value |
| 2009-01-01 | 76167 | Jan | 1 | 2009 | 111802.9 |
| 2009-01-02 | 102293 | Jan | 1 | 2009 | 76167.0 |
| 2009-01-03 | 81249 | Jan | 1 | 2009 | 102293.0 |
La forma de utilizar esta receta en un modelo es la siguiente:
Se genera un workflow ♾.
Se añade la receta 🍳.
Se añade el modelo 🤖.
Se entrena 💪.
🔹Esto proviene del framework tidymodels y tiene la ventaja de que permite predecir con datos en formato original 🙌🏼, de forma tal que antes de realizar la predicción se aplica la receta de transformación de variables.
m_prophet_boost_transporte <- workflow() %>%
add_recipe(receta_transporte) %>%
add_model(
prophet_boost(mode='regression') %>%
set_engine("prophet_xgboost")
)
m_prophet_boost_transporte <- m_prophet_boost_transporte %>%
fit(data = training(splits_transporte))
A continuación se muestran las métricas de evaluación 🧪 y puede observarse que el modelo performó mejor que el caso anterior.
m_prophet_boost_transporte %>%
modeltime_table() %>%
modeltime_calibrate(new_data=testing(splits_transporte)) %>%
modeltime_accuracy()
| Métricas de evaluación | ||||||||
|---|---|---|---|---|---|---|---|---|
| .model_id | .model_desc | .type | mae | mape | mase | smape | rmse | rsq |
| 1 | PROPHET W/ XGBOOST ERRORS | Test | 10187.52 | 9.485983 | 0.6507899 | 8.63824 | 14957.91 | 0.4453926 |
👉🏼 Existen muchas otras opciones para generar transformaciones de variables temporales. Para más información sobre trabajar con recetas en series de tiempo: Preprocessing & feature engineering operations for use with recipes and the tidymodels ecosystem.
🔹 Recetas de transformaciones a utilizar en el caso de análisis:
Primero se genera una receta y luego se añaden ciertos pasos adicionales en una segunda receta para que todas las variables queden como numéricas, dado que ciertos modelos requieren que las variables sean numéricas.
🍲 Receta 1: para modelos en los cuales no es necesario que todos los datos sean numéricos
| date | value | date_year | date_half | date_quarter | date_month.lbl | date_day | date_wday.lbl | date_mday | date_qday | date_yday | date_mweek | date_week | date_week2 | date_week3 | date_week4 | date_mday7 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2009-01-01 | 76167 | 2009 | 1 | 1 | January | 1 | Thursday | 1 | 1 | 1 | 5 | 1 | 1 | 1 | 1 | 1 |
| 2009-01-02 | 102293 | 2009 | 1 | 1 | January | 2 | Friday | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 |
🍝 Receta 2: Para modelos en los cuales es necesario que todos los datos sean numéricos)
receta_transporte_2 <- receta_transporte_1 %>%
step_mutate(date = as.numeric(date)) %>%
step_normalize(all_numeric(), -all_outcomes()) %>%
step_dummy(date_month.lbl, date_wday.lbl)
| date | value | date_year | date_half | date_quarter | date_day | date_mday | date_qday | date_yday | date_mweek | date_week | date_week2 | date_week3 | date_week4 | date_mday7 | date_month.lbl_01 | date_month.lbl_02 | date_month.lbl_03 | date_month.lbl_04 | date_month.lbl_05 | date_month.lbl_06 | date_month.lbl_07 | date_month.lbl_08 | date_month.lbl_09 | date_month.lbl_10 | date_month.lbl_11 | date_wday.lbl_1 | date_wday.lbl_2 | date_wday.lbl_3 | date_wday.lbl_4 | date_wday.lbl_5 | date_wday.lbl_6 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| -1.731242 | 76167 | -1.539649 | -0.9847107 | -1.332328 | -1.670219 | -1.670219 | -1.700307 | -1.714879 | 1.446190 | -1.686226 | 0.9958071 | -0.004995668 | -0.4465044 | -1.413055 | -0.4599331 | 0.5018282 | -0.4599331 | 0.3687669 | -0.2616083 | 0.1641974 | -0.09047913 | 0.04307668 | -0.01721256 | 0.005456097 | -0.001190618 | 0.1889822 | -0.3273268 | -0.4082483 | 0.0805823 | 0.5455447 | 0.4934638 |
| -1.730164 | 102293 | -1.539649 | -0.9847107 | -1.332328 | -1.556526 | -1.556526 | -1.662473 | -1.705286 | -1.583877 | -1.686226 | 0.9958071 | -0.004995668 | -0.4465044 | -1.413055 | -0.4599331 | 0.5018282 | -0.4599331 | 0.3687669 | -0.2616083 | 0.1641974 | -0.09047913 | 0.04307668 | -0.01721256 | 0.005456097 | -0.001190618 | 0.3779645 | 0.0000000 | -0.4082483 | -0.5640761 | -0.4364358 | -0.1973855 |
Múltiples modelos en una serie de tiempo 🌀

Para la especificación de los modelos que se van a entrenar, se puede utilizar un addin de parsnip 🙌 que permite generar la especificación de cada modelo de manera sencilla:
parsnip::parsnip_addin()
Modelos
🔹 Se definen y entrenan los modelos 🚀 a utilizar.
# Modelo Auto-ARIMA
m_autoarima_transporte = arima_reg() %>%
set_engine('auto_arima') %>%
fit(value~date, data=training(splits_transporte))
# Modelo exponential smoothing
m_exp_smoothing_transporte = exp_smoothing() %>%
set_engine('ets') %>%
fit(value~date, data=training(splits_transporte))
# Modelo prophet boosted
m_prophet_boost_transporte <- workflow() %>%
add_recipe(receta_transporte_1) %>%
add_model(
prophet_boost(mode='regression') %>%
set_engine("prophet_xgboost")
) %>%
fit(data = training(splits_transporte))
# Modelo NNetar
m_nnetar_transporte <- workflow() %>%
add_recipe(receta_transporte_1) %>%
add_model(
nnetar_reg() %>%
set_engine("nnetar")
) %>%
fit(training(splits_transporte))
# Modelo MARS
m_mars_transporte <- workflow() %>%
add_recipe(receta_transporte_2) %>%
add_model(
mars(mode = "regression") %>%
set_engine("earth")
) %>%
fit(training(splits_transporte))
Entrenamiento
🔹 Para evaluar los modelos en conjunto se utiliza la función modeltime_table() de modeltime que permite incorporar todos los modelos a una tabla.
modelos_transporte <- modeltime_table(
m_autoarima_transporte,
m_exp_smoothing_transporte,
m_prophet_boost_transporte,
m_mars_transporte,
m_nnetar_transporte
)
Evaluación
Se calculan las métricas de performance 🧪 de cada modelo en relación al dataframe de evaluación (según la partición inicial).
🔹MAE: Mean absolute error
🔹MAPE: Mean absolute percentage error
🔹MASE: Mean absolute scaled error
🔹SMAPE: Symmetric mean absolute percentage error
🔹RMSE: Root mean squared error
🔹RSQ: R-Squared
| Métrica | Fórmula |
|---|---|
| MAE | \[{{\frac {\sum _{t=1}^{T}\left|y_{t}-\hat{y}_{t}\right|}{T}}}\] |
| MAPE | \[\frac{\sum _{t=1}^{T}}{T}(\frac{|y_{t}-\hat{y}_{t}|}{y_{t}})*100 \] |
| MASE | \[{\frac{\sum _{t=1}^{T}}{T} \left({\frac {\left|y_{t}-\hat{y}_{t}\right|}{{\frac {1}{T-m}}\sum _{t=m+1}^{T}\left|Y_{t}-Y_{t-m}\right|}}\right)}\] |
| SMAPE | \[{\frac{\sum _{t=1}^{T}}{T}(\frac{2|y{t}−\hat{y}_{t}|}{(|y_{t}|+|\hat{y}_{t}|)})}\] |
| RMSE | \[{(\frac{\sum _{t=1}^{T}}{T}(\hat{y}_{t}-y_{t})^2})^{\frac{1}{2}} \] |
| RSQ | \[{1-{\frac {\sum _{t=1}^{T}\left(y_{T}-\hat{y}_{t}\right)}{\sum _{i=1}^{n}\left(y_{t}-\bar{y}_{t}\right)}}}\] |
En base a estas métricas, se seleccionarán los modelos que mejor performan 🥇.
calibration_table_transporte <- modelos_transporte %>%
modeltime_calibrate(new_data = testing(splits_transporte))
🔹 Se visualiza la tabla con las métricas de error y el r-cuadrado. Los colores más oscuros indican mejor modelo en base a dicha métrica (menos error o mayor r cuadrado). Para esto, se utiliza la función accuracy_table(), que le da formato a la función modeltime_accuracy() utilizada anteriormente.
Show code
accuracy_table <- function(.accuracy,
.subtitle=NULL,
.color1='#c5cde0',
.color2='#6274a3',
.round_num=0.01){
.accuracy %>%
select(-.type) %>%
mutate(across(where(is.numeric), round, 2)) %>%
gt(rowname_col = c(".model_id")) %>%
tab_header(title = 'Evaluación de modelos',
subtitle = .subtitle) %>%
cols_label(`.model_desc` = 'Modelo') %>%
data_color(columns = vars(mae),
colors = scales::col_numeric(
reverse = TRUE,
palette = c('white',.color1, .color2),
domain = c(min(.accuracy$mae)-.round_num,
max(.accuracy$mae)+.round_num)
)) %>%
data_color(columns = vars(mape),
colors = scales::col_numeric(
reverse = TRUE,
palette = c('white',.color1, .color2),
domain = c(min(.accuracy$mape)-.round_num,
max(.accuracy$mape)+.round_num)
)) %>%
data_color(columns = vars(mase),
colors = scales::col_numeric(
reverse = TRUE,
palette = c('white',.color1, .color2 ),
domain = c(min(.accuracy$mase)-.round_num,
max(.accuracy$mase)+.round_num)
)) %>%
data_color(columns = vars(smape),
colors = scales::col_numeric(
reverse = TRUE,
palette = c('white',.color1, .color2),
domain = c(min(.accuracy$smape)-.round_num,
max(.accuracy$smape)+.round_num)
)) %>%
data_color(columns = vars(rmse),
colors = scales::col_numeric(
reverse = TRUE,
palette = c('white',.color1, .color2),
domain = c(min(.accuracy$rmse)-.round_num,
max(.accuracy$rmse)+.round_num)
)) %>%
data_color(columns = vars(rsq),
colors = scales::col_numeric(
reverse = FALSE,
palette = c('white',.color1, .color2),
domain = c(min(.accuracy$rsq)-.round_num,
max(.accuracy$rsq)+.round_num)
))
}
Invocando la función se obtiene la tabla:
accuracy_table(calibration_table_transporte %>%
modeltime_accuracy(),
.subtitle = 'Estación Avellaneda')
| Evaluación de modelos | |||||||
|---|---|---|---|---|---|---|---|
| Estación Avellaneda | |||||||
| Modelo | mae | mape | mase | smape | rmse | rsq | |
| 1 | ARIMA(0,0,1)(0,1,1)[7] WITH DRIFT | 11429.16 | 10.71 | 0.73 | 9.66 | 16142.29 | 0.37 |
| 2 | ETS(M,N,A) | 11800.81 | 11.08 | 0.75 | 9.96 | 16451.81 | 0.39 |
| 3 | PROPHET W/ XGBOOST ERRORS | 10231.29 | 9.54 | 0.65 | 8.71 | 14702.13 | 0.46 |
| 4 | EARTH | 9833.27 | 9.26 | 0.63 | 8.39 | 14624.90 | 0.46 |
| 5 | NNAR(1,1,10)[7] | 9082.91 | 8.58 | 0.58 | 7.86 | 13648.59 | 0.48 |
Forecasting
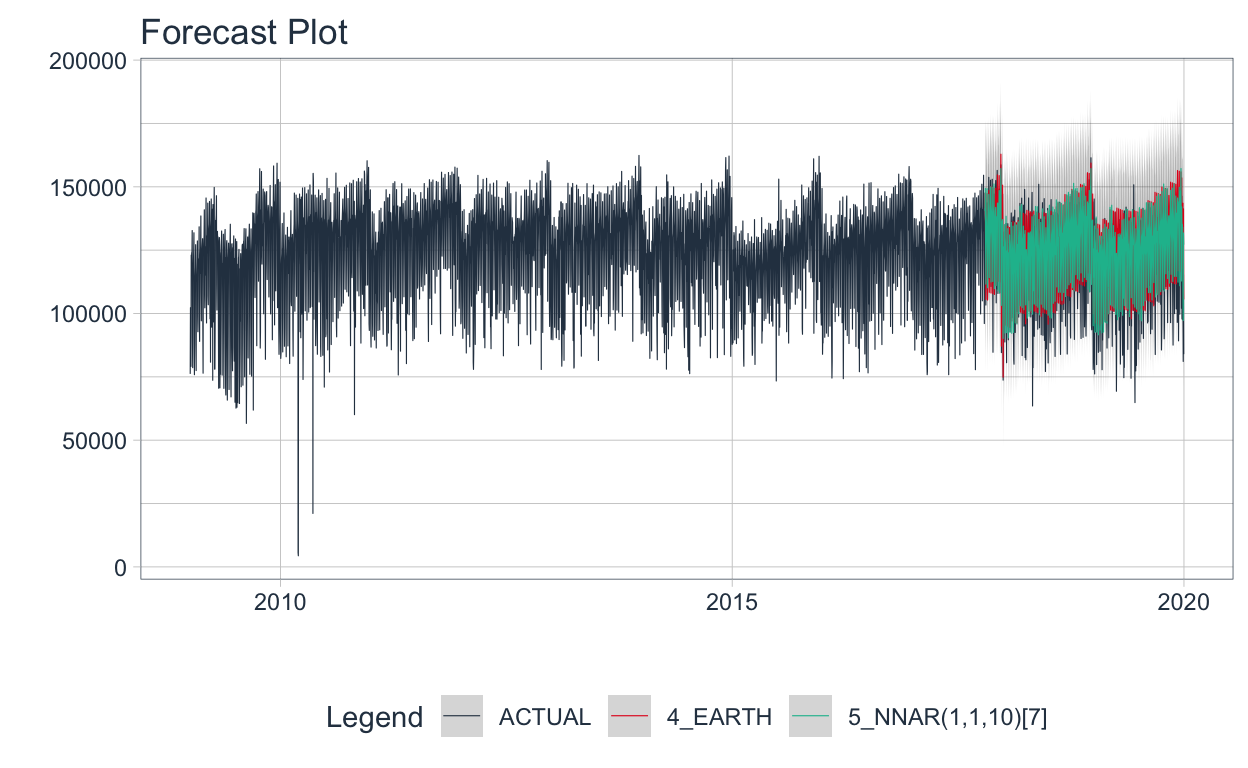
🔹Finalmente se visualizan los valores predichos 🔮 por los modelos que mejor performaron contra los valores observados. Los mejores modelos fueron: NNAR y MARS (Earth). En este caso, el NNAR 🥇 es modelo es el mejor considerado cualquiera de las métricas. Sin embargo, pueden existir casos en donde el mejor modelo en función de cierta métrica no sea el mismo si se considerara otra métrica de evaluación.
forecast_transporte <- calibration_table_transporte %>%
filter(.model_id %in% c(4,5)) %>%
modeltime_forecast(
new_data = testing(splits_transporte),
actual_data = df_avellaneda_model
)
👀 Finalmente se presenta el forecast contra el valor observado en la partición de evaluación.
Visualización de las predicciones
🔹En el período de evaluación podemos observar más claramente qué forecast se ajusta mejor a los datos que el modelo no ha visto para el entrenamiento.
Visualizar todo el período
Show code
forecast_transporte %>%
plot_modeltime_forecast(
.legend_max_width = 30,
.interactive = FALSE,
.conf_interval_alpha = 0.2,
.line_size=0.2
)
Visualizar solo período de test
Show code
calibration_table_transporte %>%
filter(.model_id %in% c(4,5)) %>%
modeltime_forecast(
new_data = df_avellaneda_model %>%
filter(date >= min(testing(splits_transporte)$date)) %>%
mutate(value = NA),
actual_data = df_avellaneda_model %>%
filter(date >= min(testing(splits_transporte)$date))
) %>%
plot_modeltime_forecast(
.legend_max_width = 30,
.interactive = FALSE,
.conf_interval_alpha = 0.2,
.line_size=0.5
)
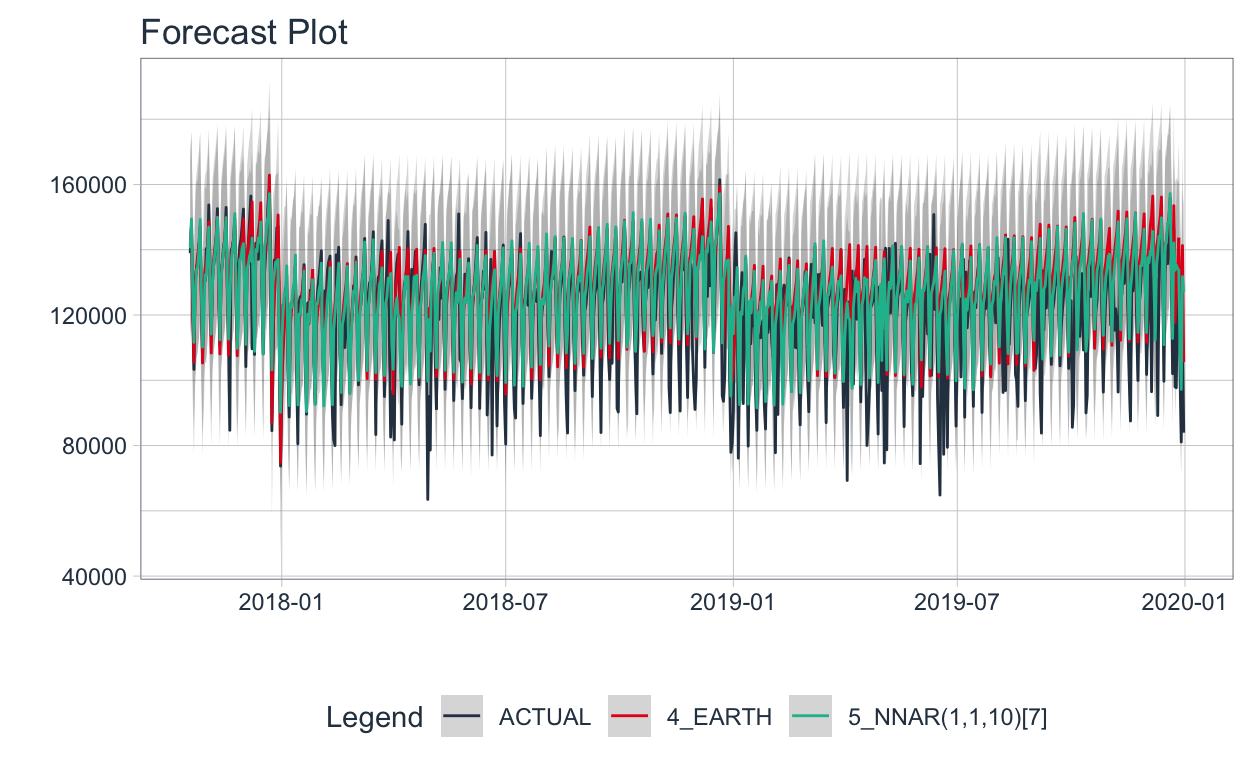
Recalibración del modelo
Se reajusta el modelo NNAR 🚀 para todo el dataframe (2009-2019):
refit_tbl_transporte <- calibration_table_transporte %>%
filter(.model_id %in% c(5)) %>%
modeltime_refit(data = df_avellaneda_model)
🔹Con este modelo es posible realizar el forecast para 2020 🧙 Esto permite entender cómo hubiera sido el flujo vehicular de medios de transporte Livianos en el peaje Avellaneda de no haber existido pandemia.
forecast_transporte <- refit_tbl_transporte %>%
modeltime_forecast(
actual_data = df_avellaneda,
h='1 years'
)
Se visualiza el forecast del mejor modelo.
Show code
forecast_transporte %>%
plot_modeltime_forecast(
.legend_max_width = 30,
.interactive = FALSE,
.conf_interval_alpha = 0.2,
.line_size = 0.2,
)
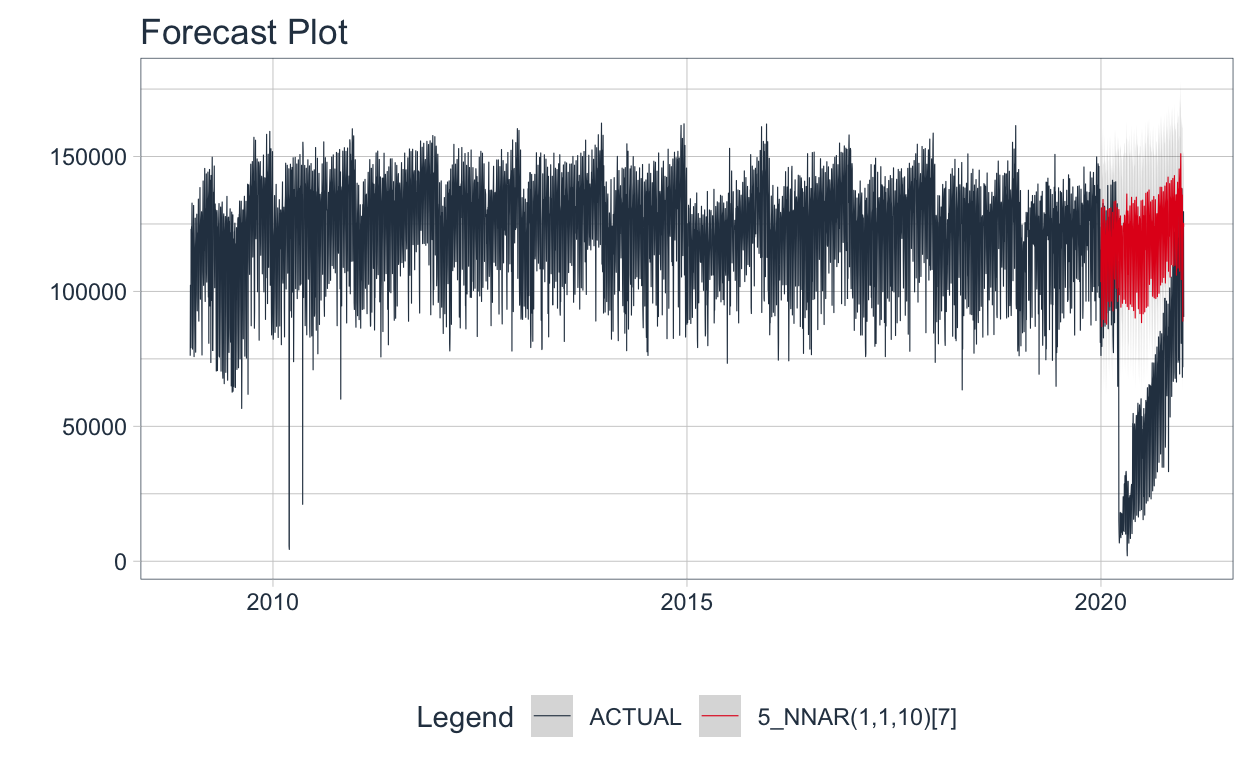
Bien, pero…. ¿Es posible ajustar múltiples modelos a múltiples series de tiempo? 💡

🔹En este punto se quiere analizar la posibilidad de especificar múltiples modelos y ajustarlos a diversas series (series individuales, no datos de panel) 💡 para comprender cuál es el modelo más adecuado para cada serie. Primero se realiza un breve analisis exploratorio del grupo de series a proyectar y luego se procede a entrenar los modelos.
Datos 📊
🔎 El EMAE es un indicador que refleja la evolución mensual de la actividad económica del conjunto de los sectores productivos a nivel nacional para Argentina, además permite anticipar las tasas de variación del producto interno bruto (PIB) trimestral. Para mayor detalle consultardetalles técnicos EMAE.
🔌 Se obtuvieron datos de todas las series de EMAE sectorial, desde Enero 2004 hasta Octubre 2020, mediante la API de Series de Tiempo (Argentina)
🔹 En este caso se entrenan múltiples modelos en múltiples series, intentando comprender por qué ciertos modelos se comportan mejor en cierto tipo de series. Es por ello que se decidió utilizar datos mensuales de EMAE ya que parecía más intuitivo para entender los modelos y observar las diferentes proyecciones.
A continuación se detalla brevemente cómo obtener estos datos:
- ✅ Obtenemos las series correspondientes a EMAE:
Show code
# Dataset con todas las series disponibles:
url <- "https://apis.datos.gob.ar/series/api/dump/series-tiempo-metadatos.csv"
series <- read.csv(url) %>%
# Filtro por series EMAE que llegan hasta Octubre 2020
filter(str_detect(serie_descripcion, "EMAE"),
series$serie_indice_final=='2020-10-01',
distribucion_id=='11.3') %>%
# Transformación en el título de la serie
mutate(serie_titulo = gsub("_"," ", serie_titulo)) %>%
# Selección de variables relevantes
select(serie_id, sector = serie_titulo)
- ✅ Obtenemos los datos correspondientes a estas series:
Show code
df_emae <- data.frame()
for (i in series$serie_id){
# Se leen los datos correspondientes a una de las series
temp = read.csv(url(paste0("https://apis.datos.gob.ar/series/api/series/?ids=",
i,"&limit=5000&&format=csv")))
# Se define el sector correctamente
sector = gsub("_", " ", names(temp)[2])
# Se colocan los nombres del df para la serie
names(temp)=c('date','value')
# Fecha en formato correcto
temp = temp %>% mutate(date=as.Date(date))
# Se unen los datos
df_emae = bind_rows(df_emae,temp)
}
- ✅ Algunas modificaciones en los nombres de los sectores:
Show code
df_emae <- df_emae %>% mutate(
date = as.Date(date),
# Renombramiento de sectores
sector = case_when(
sector=="comercio mayorista minorista reparaciones" ~ "Comercio",
sector=='ensenianza'~"Enseñanza",
sector=='transporte comunicaciones'~'Transporte y comunicaciones',
sector=='servicios sociales salud'~'Servicios sociales/Salud',
sector=='impuestos netos subsidios'~'Impuestos netos',
sector=="intermediacion financiera"~ 'Sector financiero',
sector=='explotacion minas canteras'~'Minería',
sector=='electricidad gas agua'~'Electricidad/Gas/Agua',
sector=='hoteles restaurantes'~'Hoteles/Restaurantes',
sector=='actividades inmobiliarias empresariales alquiler'~'Inmobiliarias',
sector=='otras actividades servicios comunitarias sociales personales'~
'Otras actividades',
sector=='pesca'~'Pesca',
sector=="industria manufacturera"~'Industria manufacturera',
sector=='construccion'~'Construcción',
sector=='admin publica planes seguridad social afiliacion obligatoria'~
'Administración pública',
sector=='agricultura ganaderia caza silvicultura'~
"Agro/Ganadería/Caza/Silvicultura",
TRUE~''
))
🔹 Sin embargo, no es necesario replicar los 3 pasos anteriores para obtener estos mismos datos, ya que se almacenaron en el paquete sknifedatar y se puede acceder a ellos de la siguiente forma:
df_emae <- sknifedatar::emae_series
Show code
df_emae %>% mutate(value=round(value,2)) %>% head(5) %>% gt() %>%
tab_header('Estimador Mensual de Actividad Económica (EMAE)')
| Estimador Mensual de Actividad Económica (EMAE) | ||
|---|---|---|
| date | value | sector |
| 2004-01-01 | 92.07 | Comercio |
| 2004-02-01 | 91.46 | Comercio |
| 2004-03-01 | 109.13 | Comercio |
| 2004-04-01 | 99.42 | Comercio |
| 2004-05-01 | 100.53 | Comercio |
🔹 Primero se realiza un breve análisis exploratorio de los datos para entender mejor las series. Se realiza el análisis filtrando los datos para considerar los meses previos a la pandemia.
FECHA = '2020-02-01' # máxima fecha para partición en train test (último mes pre pandemia)
Las 16 actividades que se consideran tienen distintas características en términos de estacionalidad, tendencia y autocorrelación.
Descomposición de series temporales
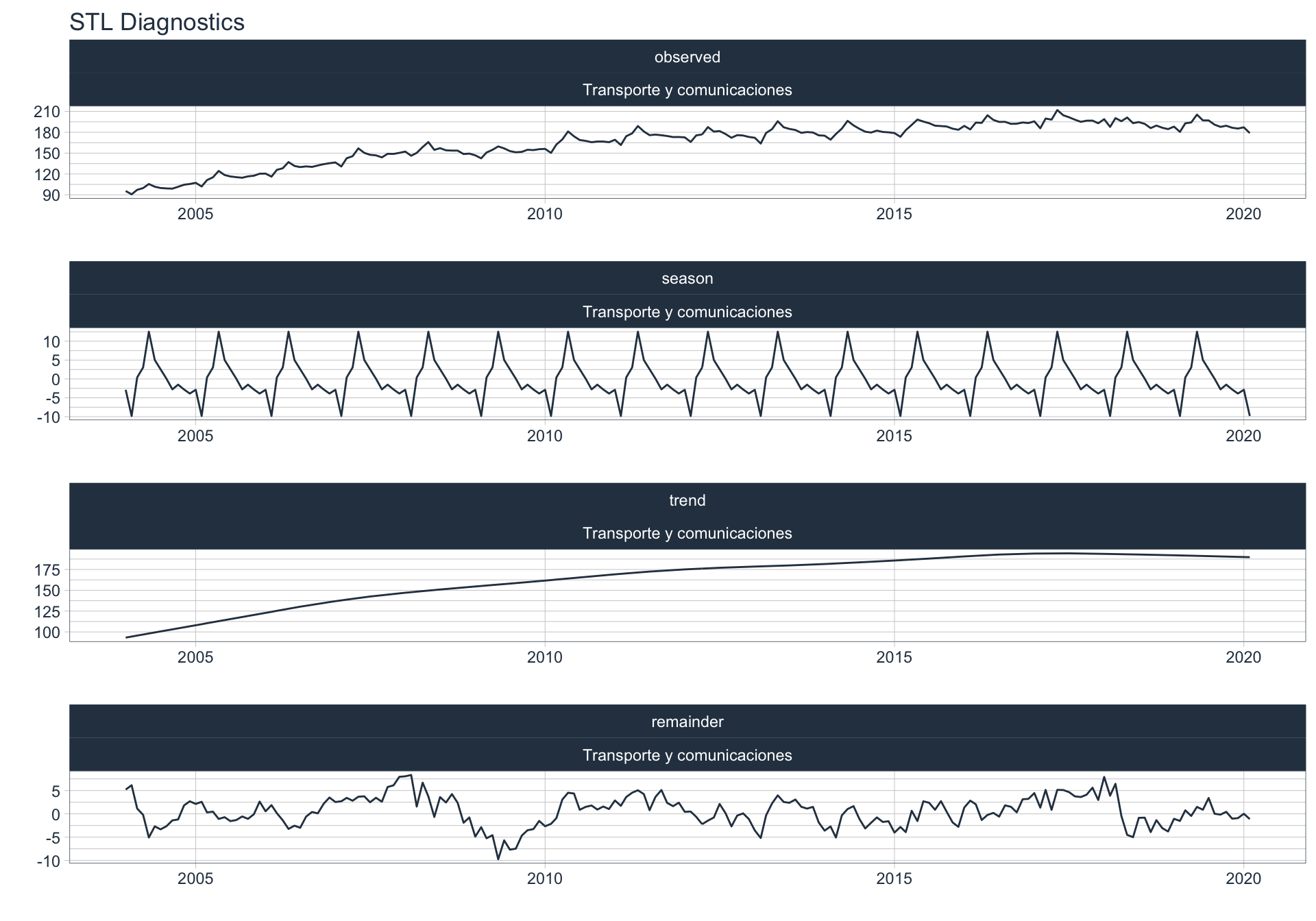
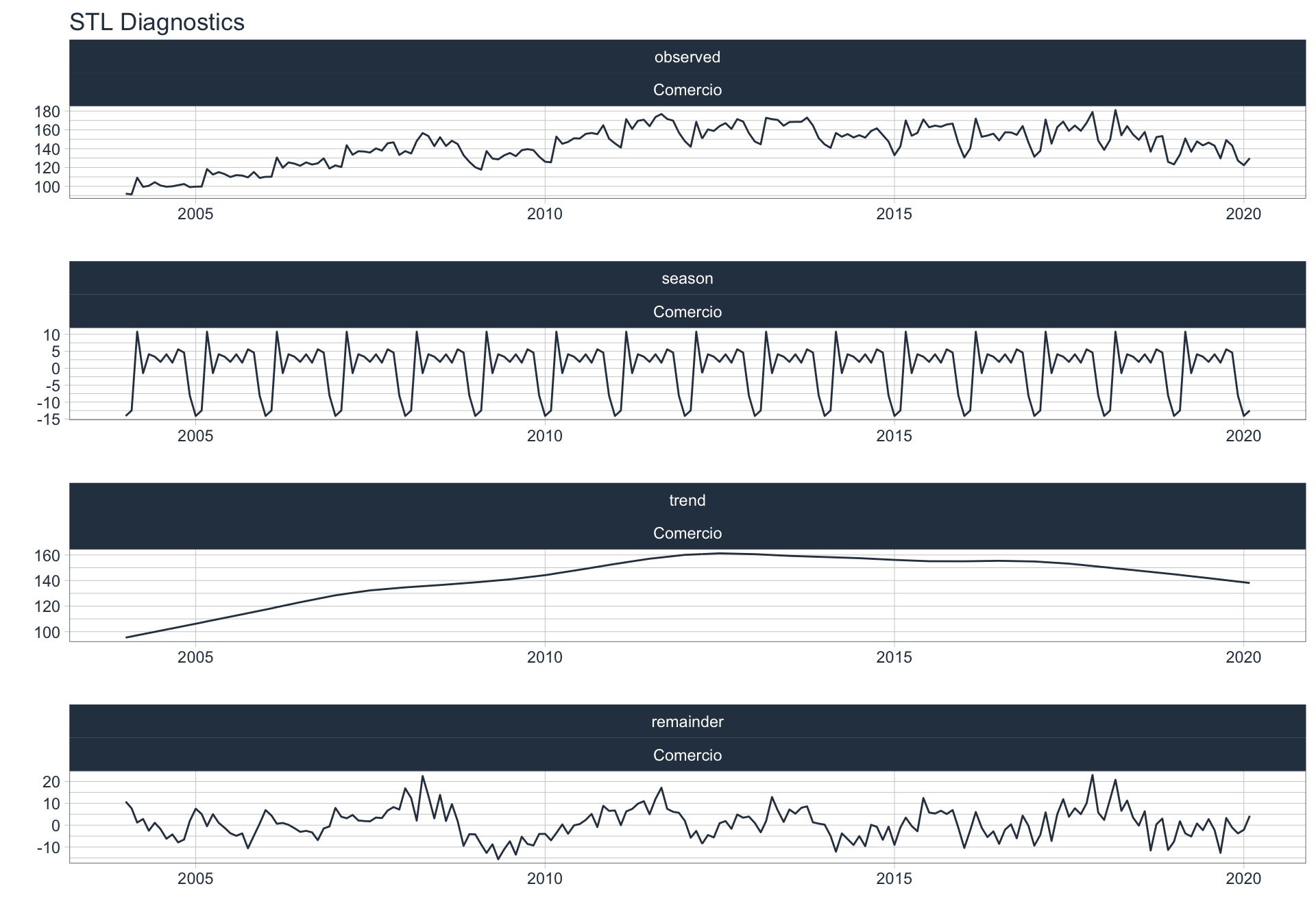
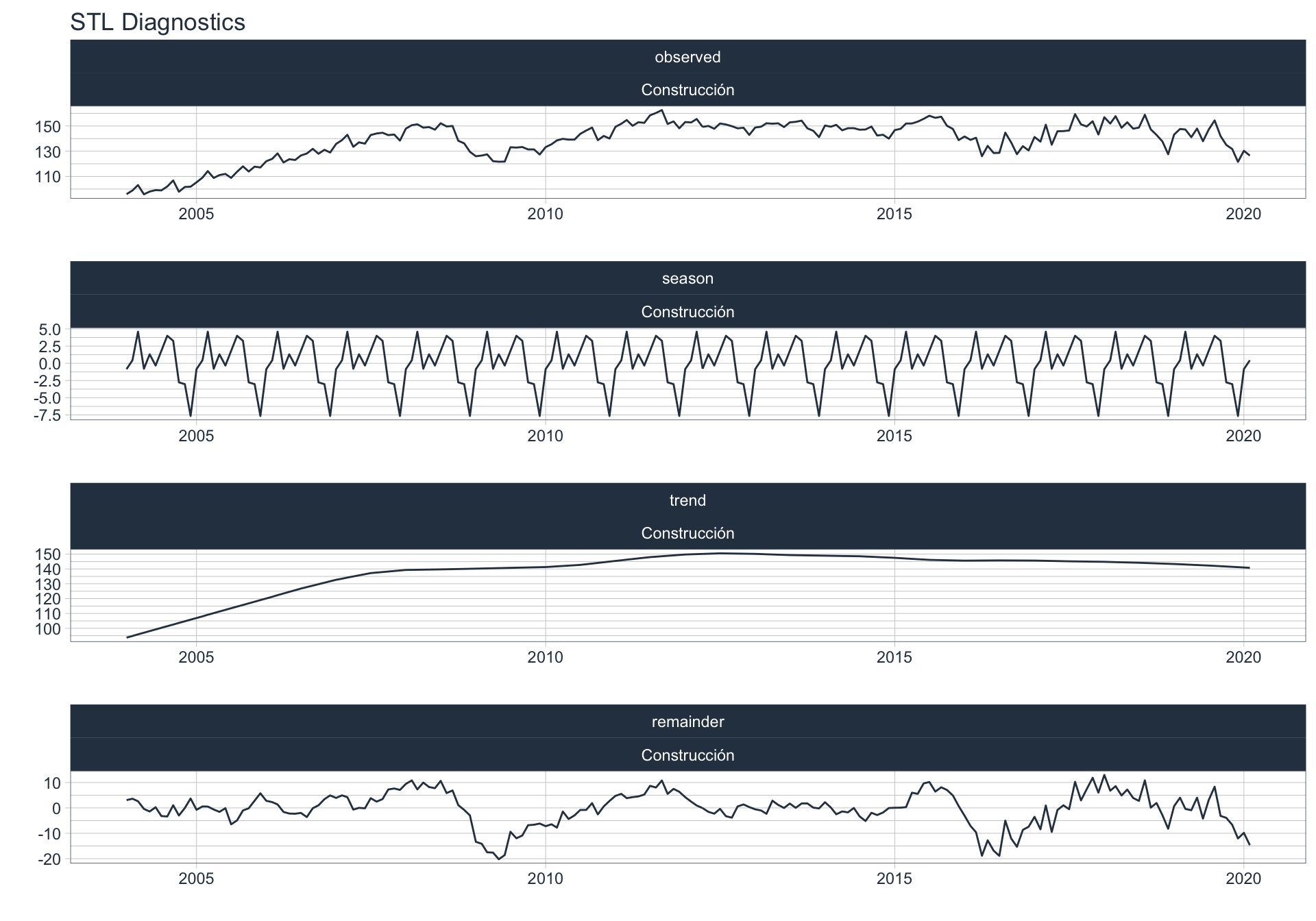
Los siguientes gráficos 📈 muestran la descomposición de cada serie en tendencia, estacionalidad y resto:
\(observed_{t} = season_{t} + trend_{t} + reminder_{t}\)
📝 Se dejó un ajuste automático para el cálculo de la frecuencia de estacionalidad para cada serie en función del formato de la variable de fecha. Queda definida una frecuencia de 12 observaciones por año (es decir, se evalúa estacionalidad a lo largo del año).
👀 Notar que algunas series presentan un fuerte componente tendencial como es el caso de Enseñanza. Además, en el caso de Agro se puede ver que los componentes tendencial y estacional difieren en gran magnitud del valor observado (componente restante) en los casos anómalos detectados anteriormente (por ejemplo, Mayo 2009).
Para realizar la descomposición en alguna de las series se utiliza la siguiente sintaxis:
df_emae %>% filter(sector == 'Transporte y comunicaciones', date <= FECHA) %>%
group_by(sector) %>%
plot_stl_diagnostics(
.date_var=date,
.value=value,
.frequency = 'auto',
.trend = 'auto',
.feature_set = c("observed", "season", "trend", "remainder"),
.interactive = FALSE
)
Transporte y comunicaciones
Comercio
Enseñanza
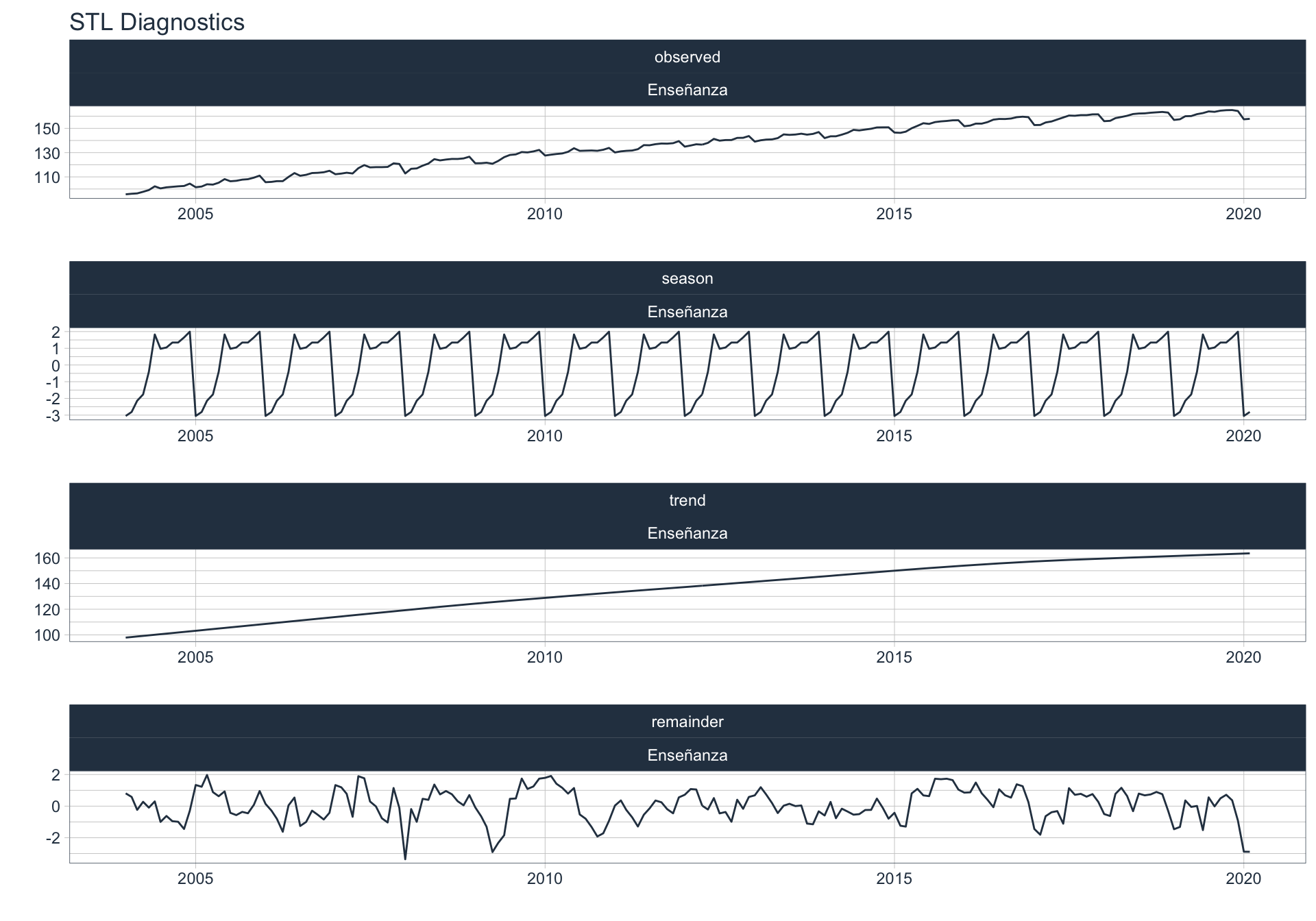
Admin pública
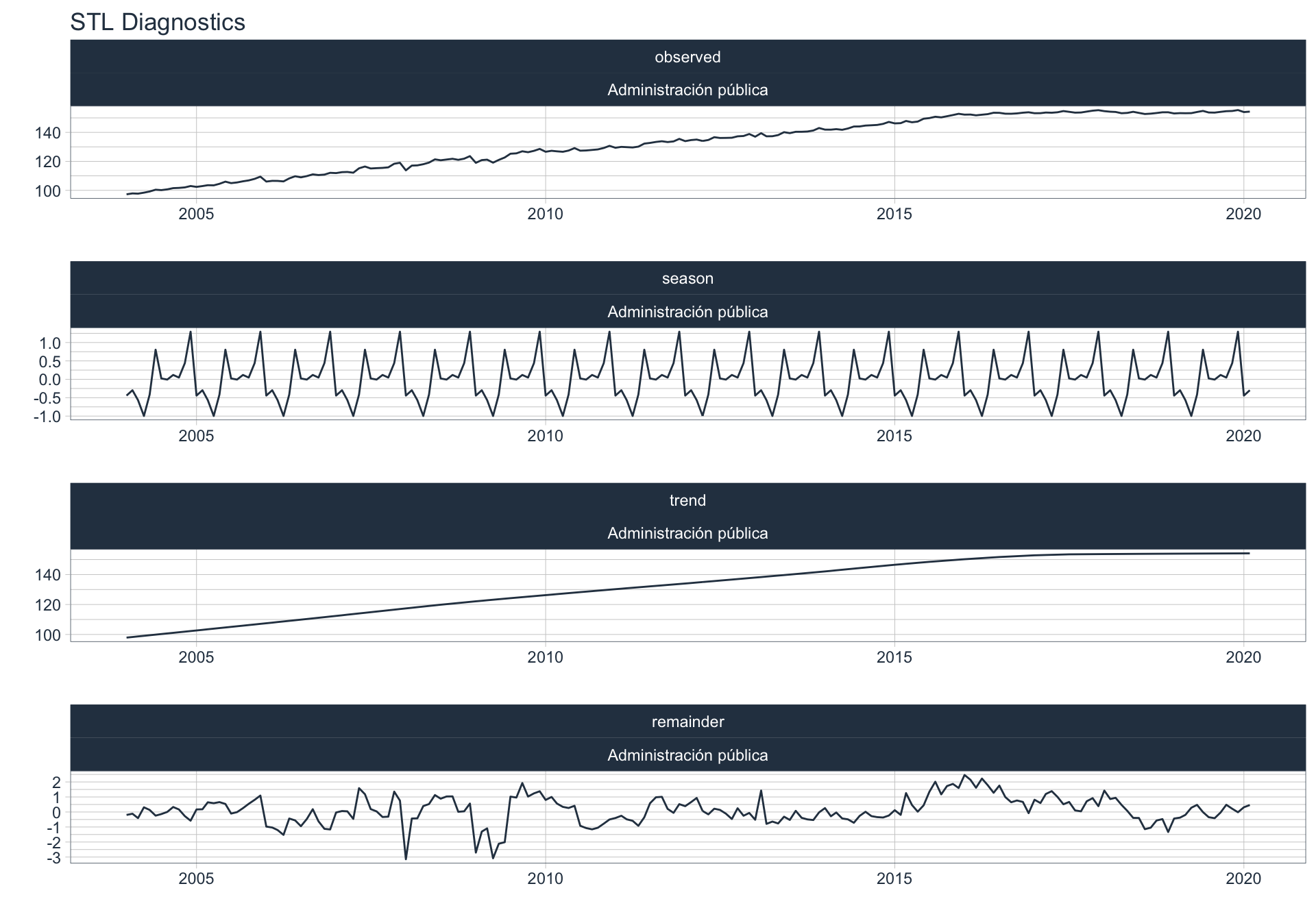
Servicios sociales/Salud
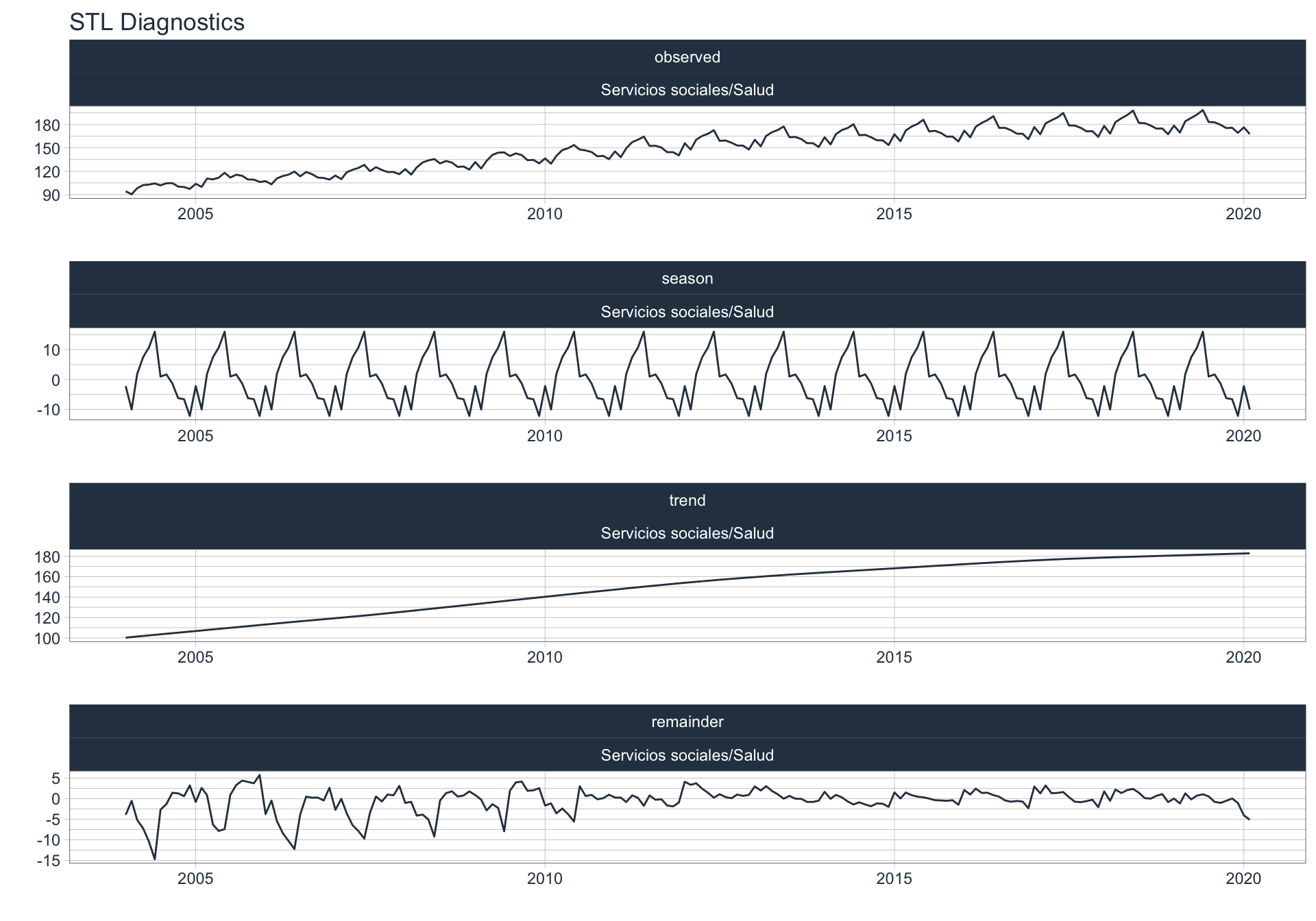
Impuestos netos
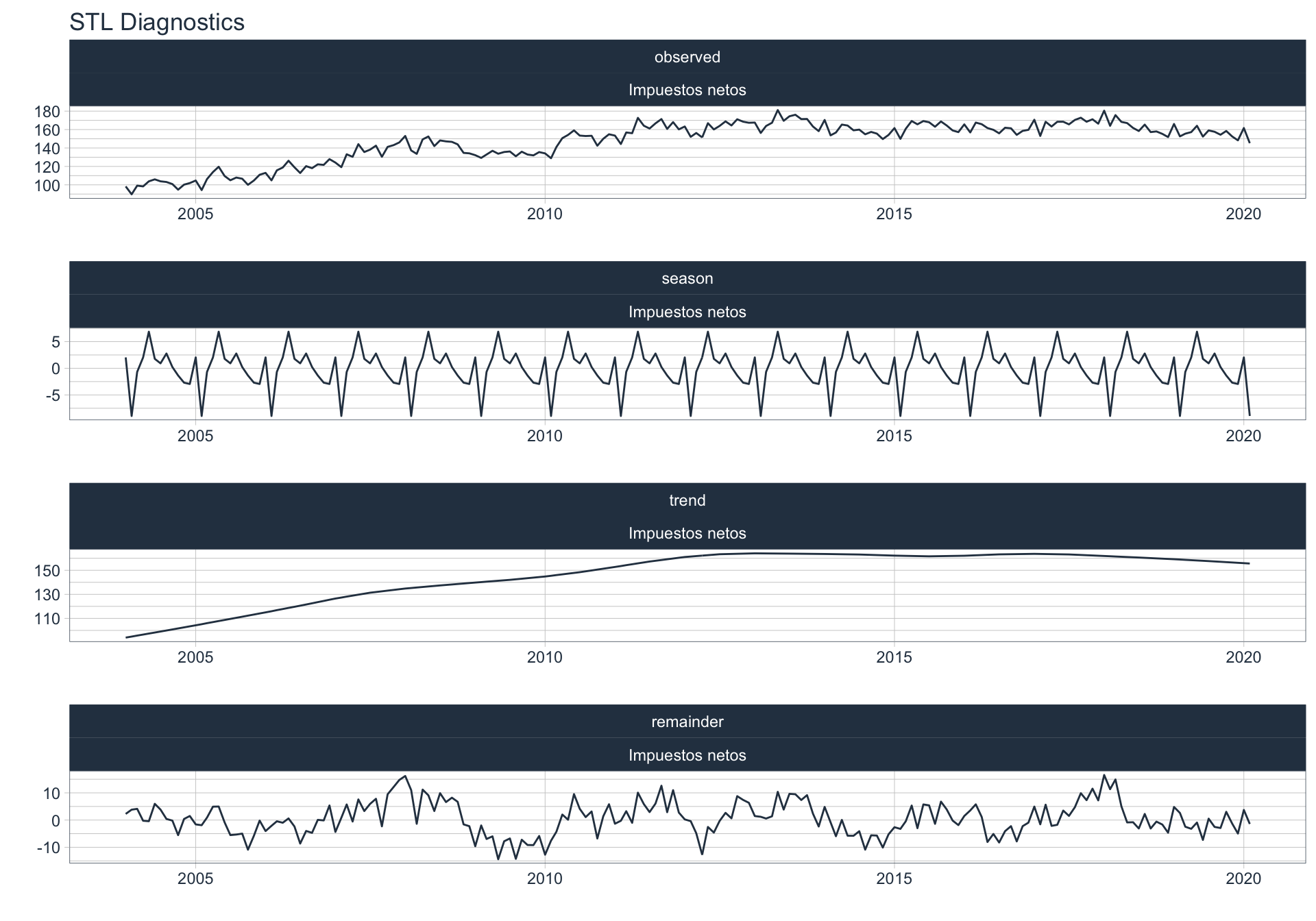
Sector financiero
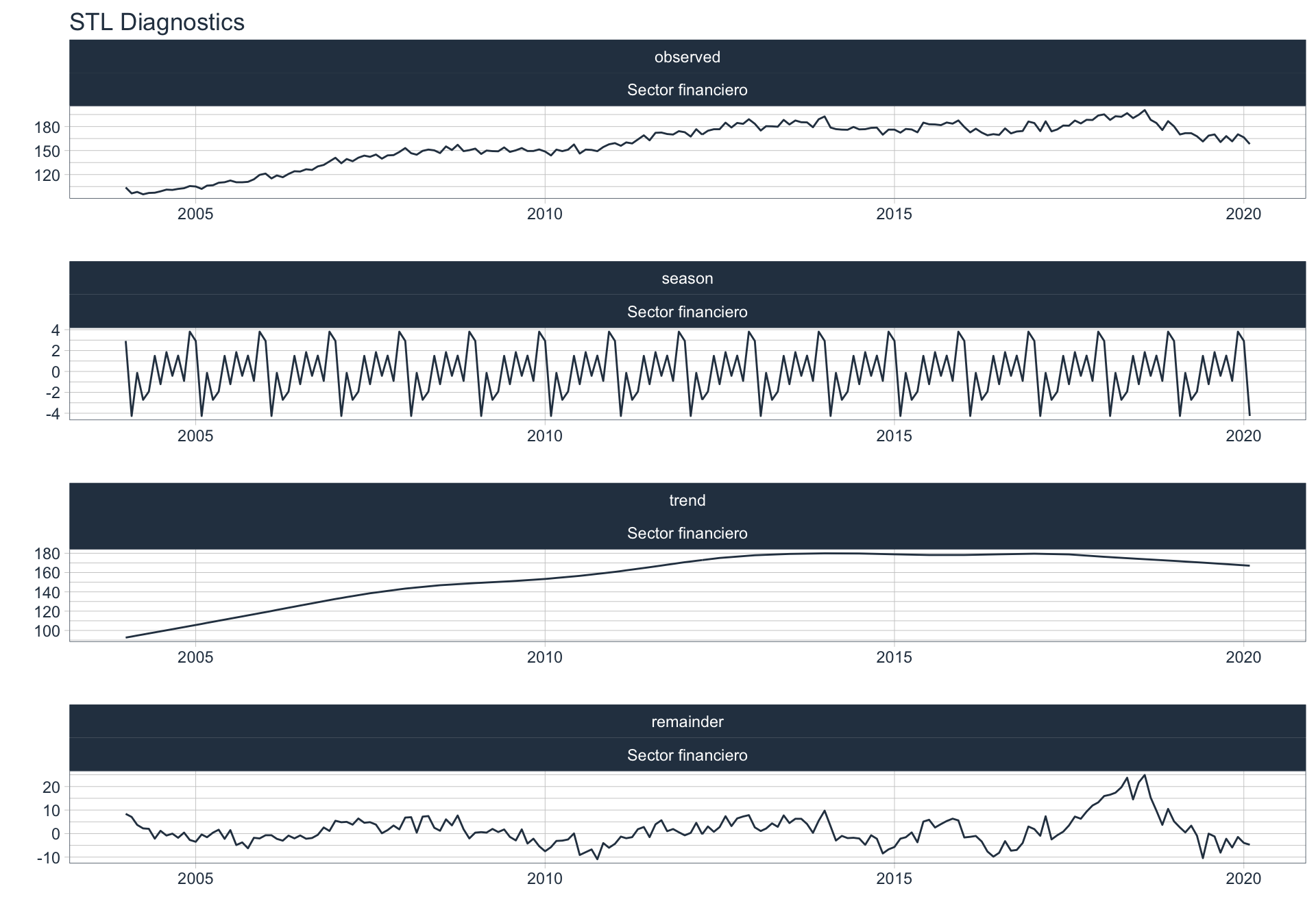
Minería
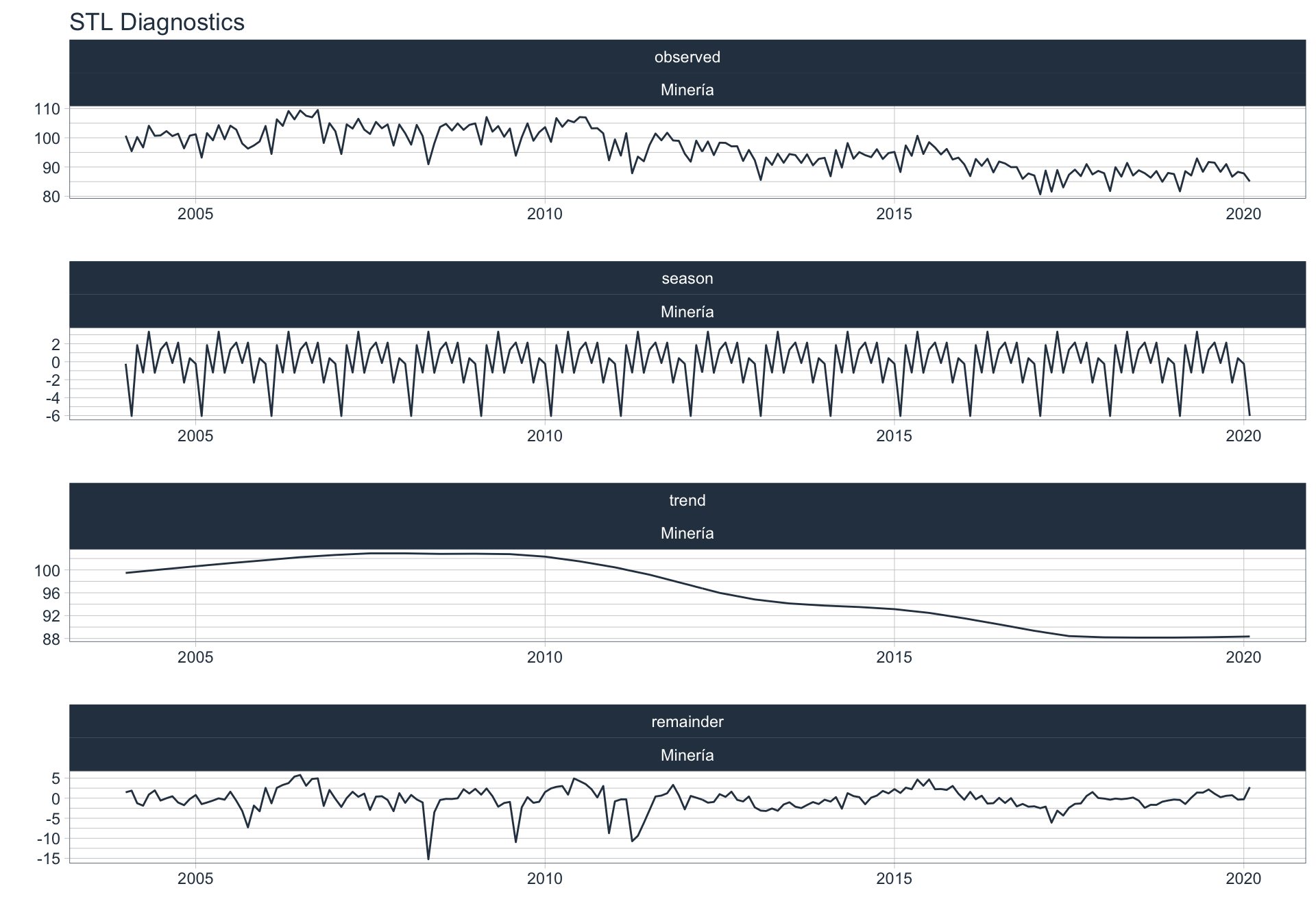
Agro/Ganadería/Caza/Silvicultura
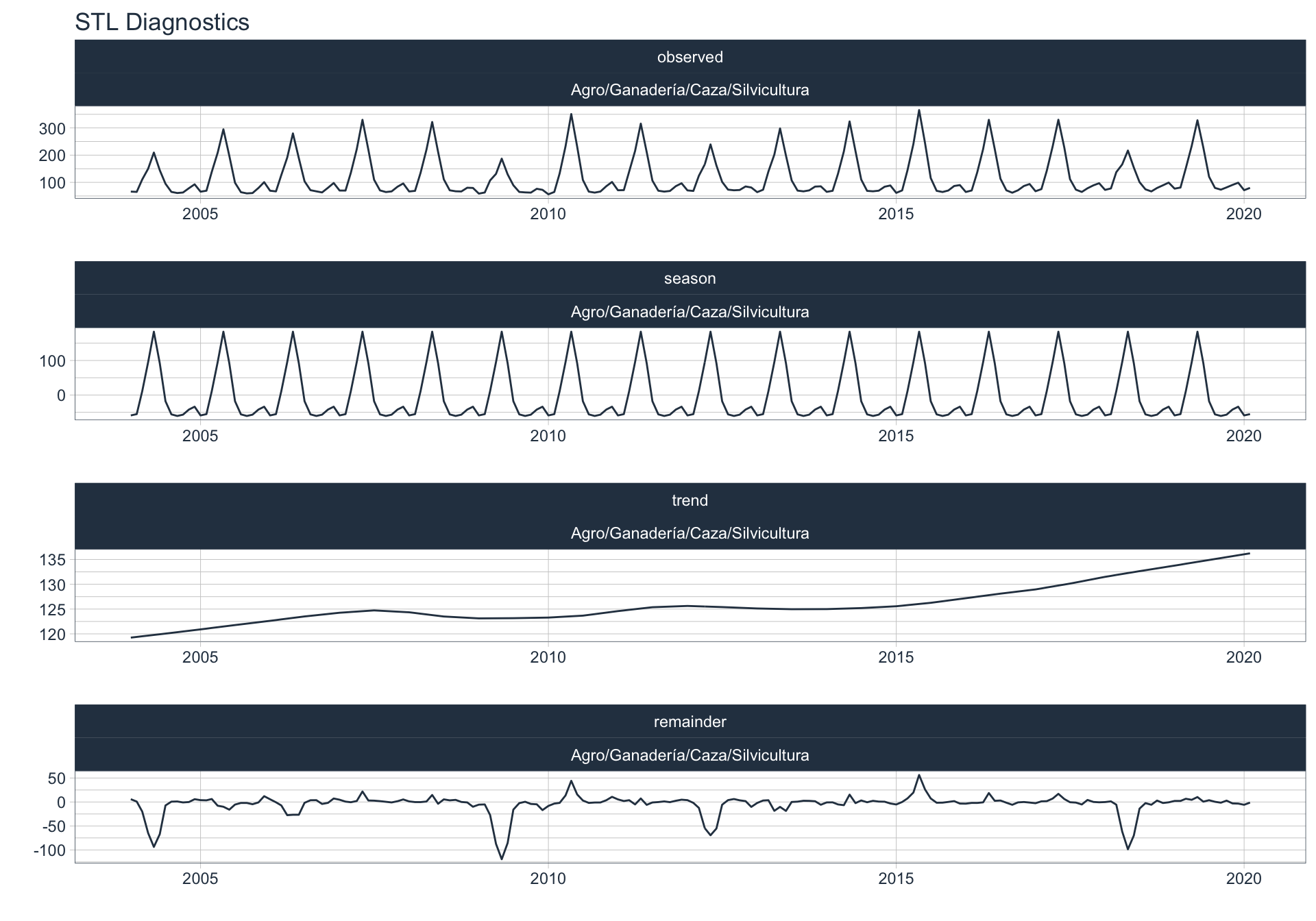
Elec/Gas/Agua
Hoteles/Rest
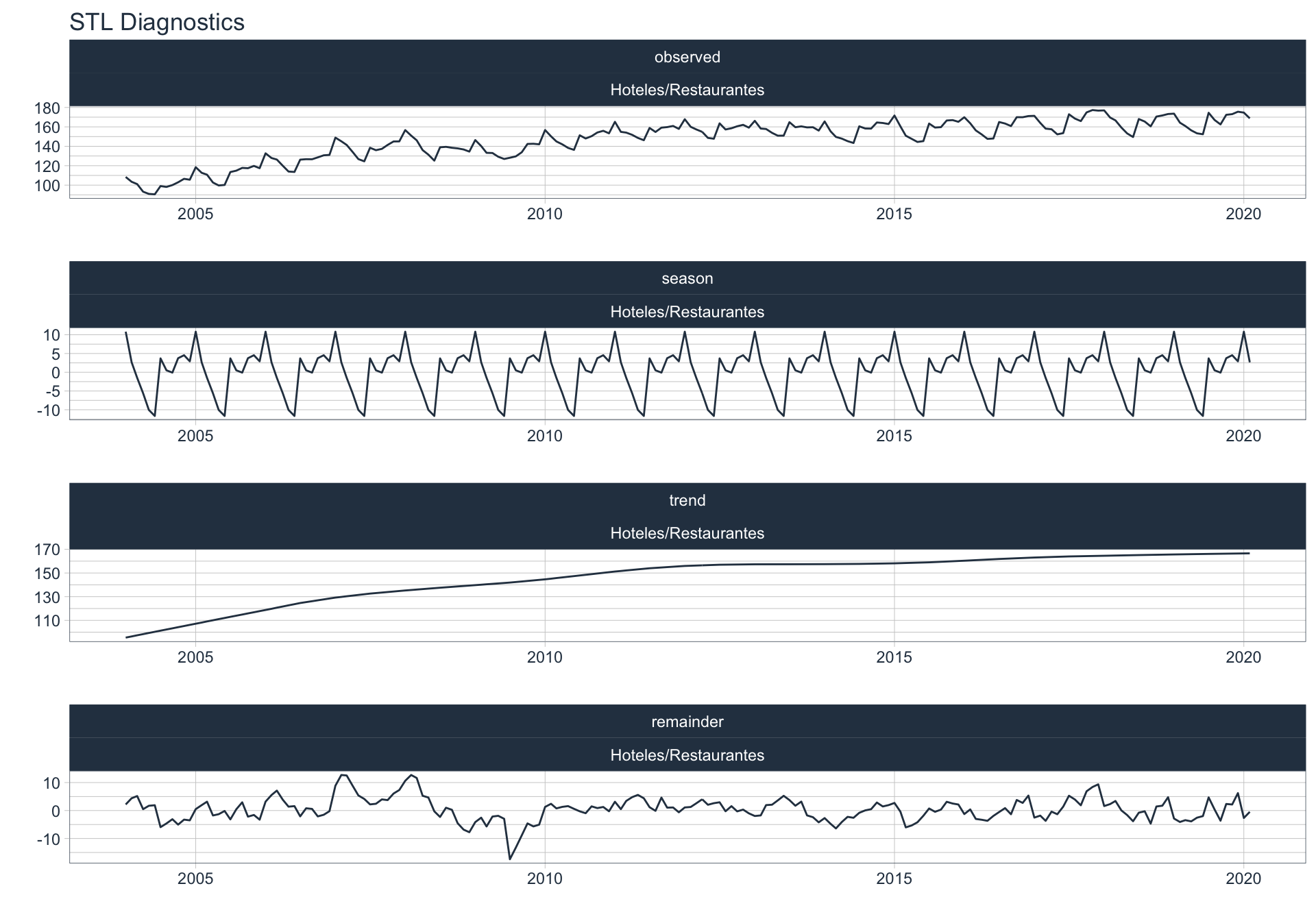
Inmobiliarias
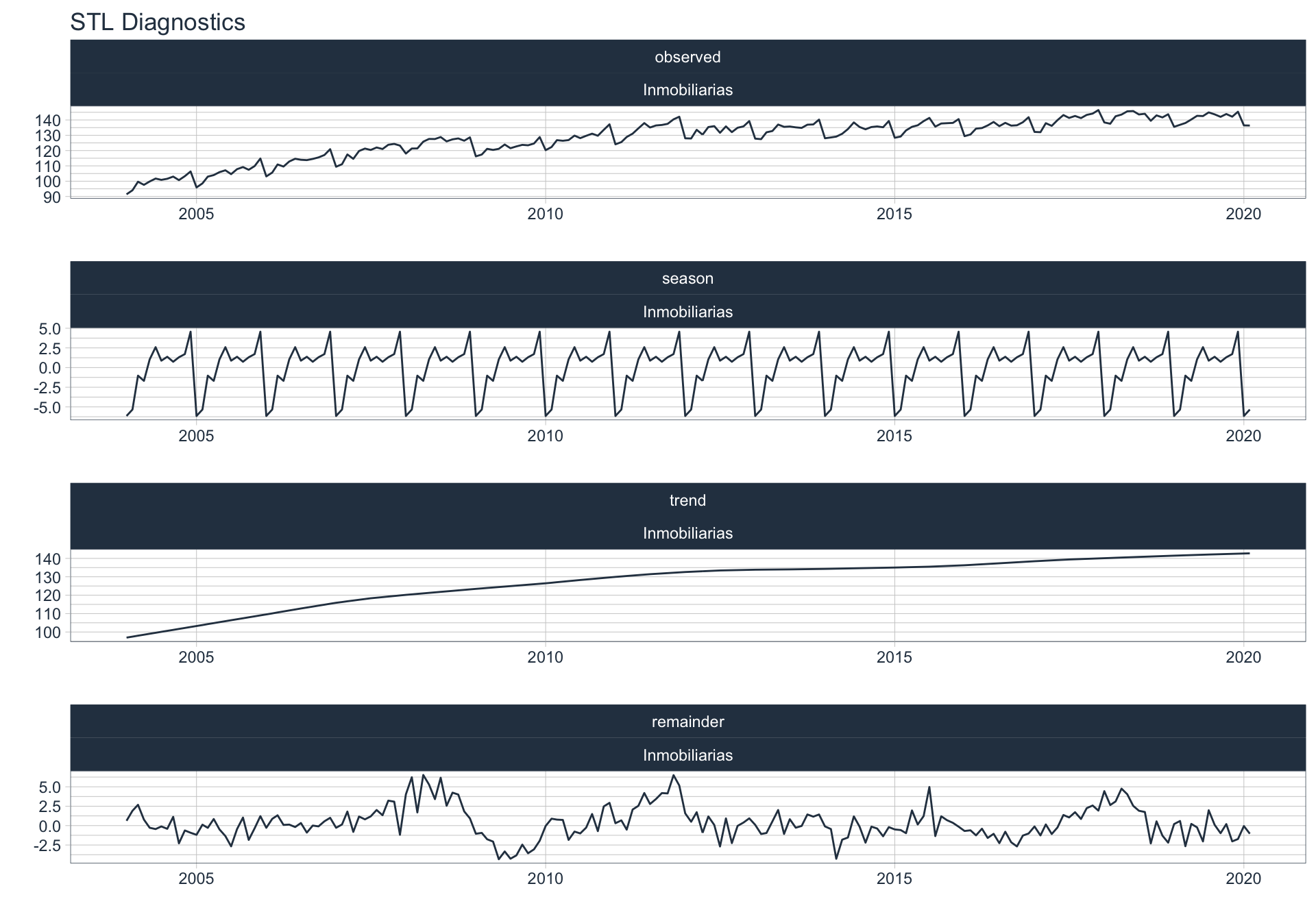
Otras actividades
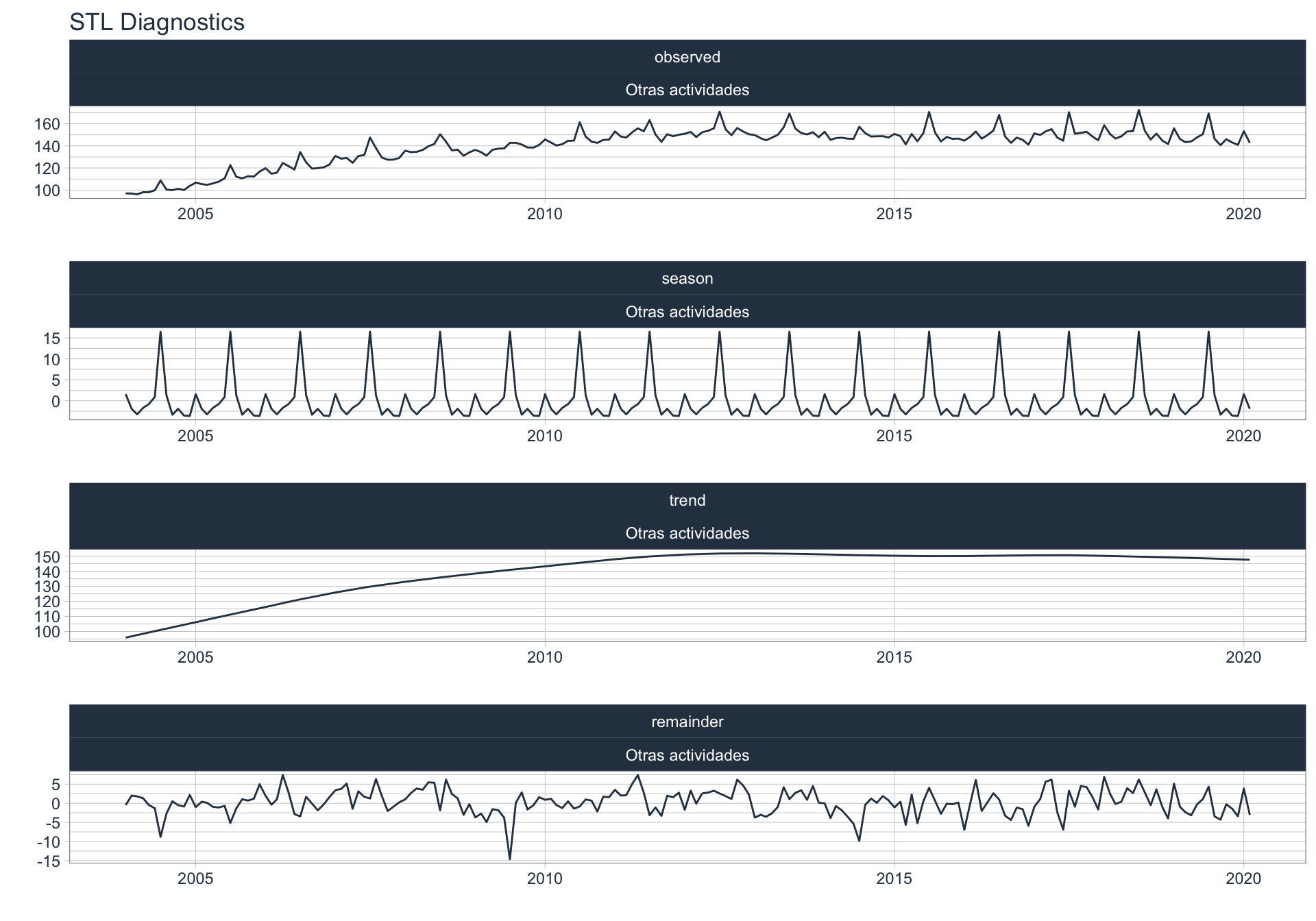
Pesca
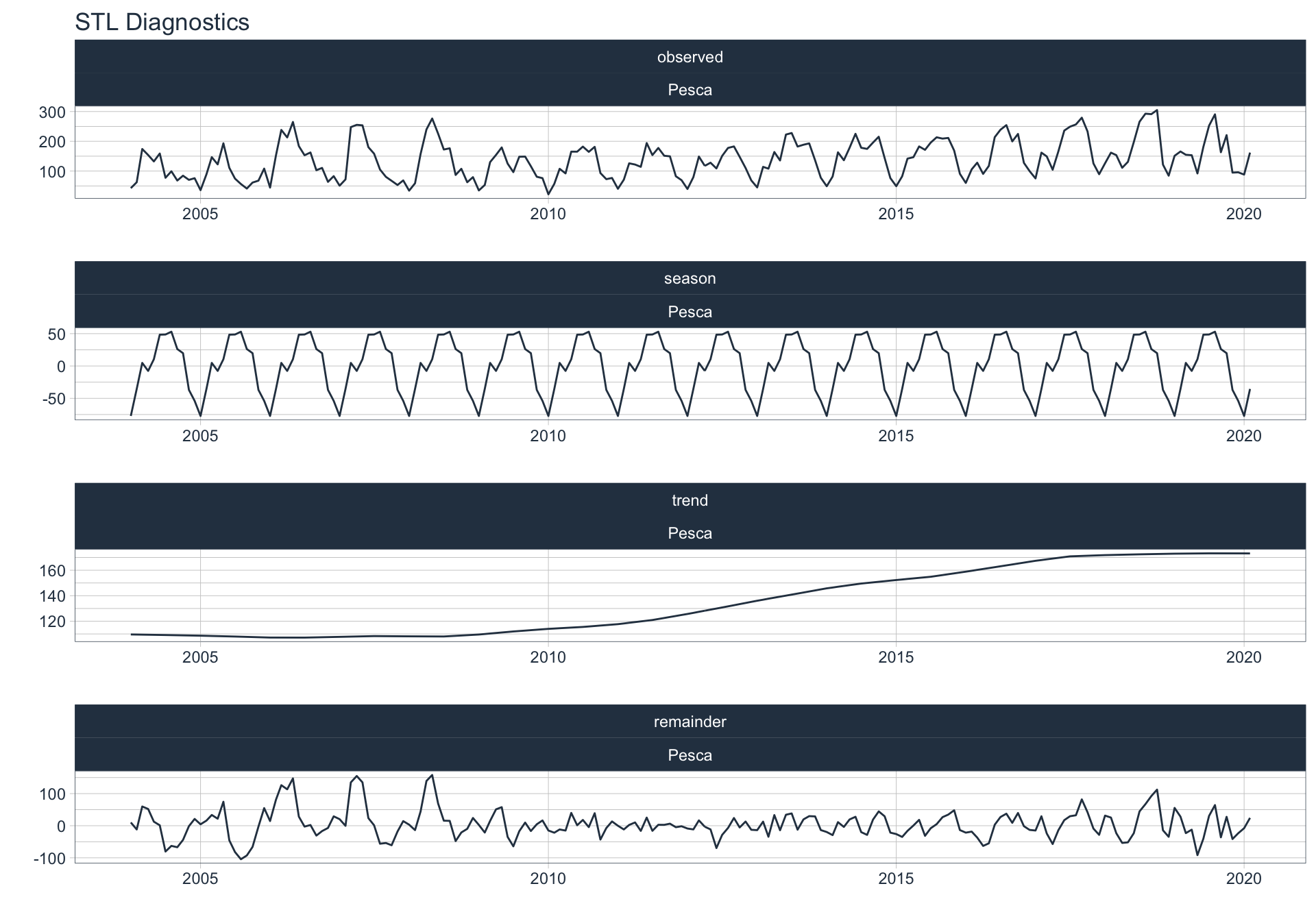
Industria Manufacturera
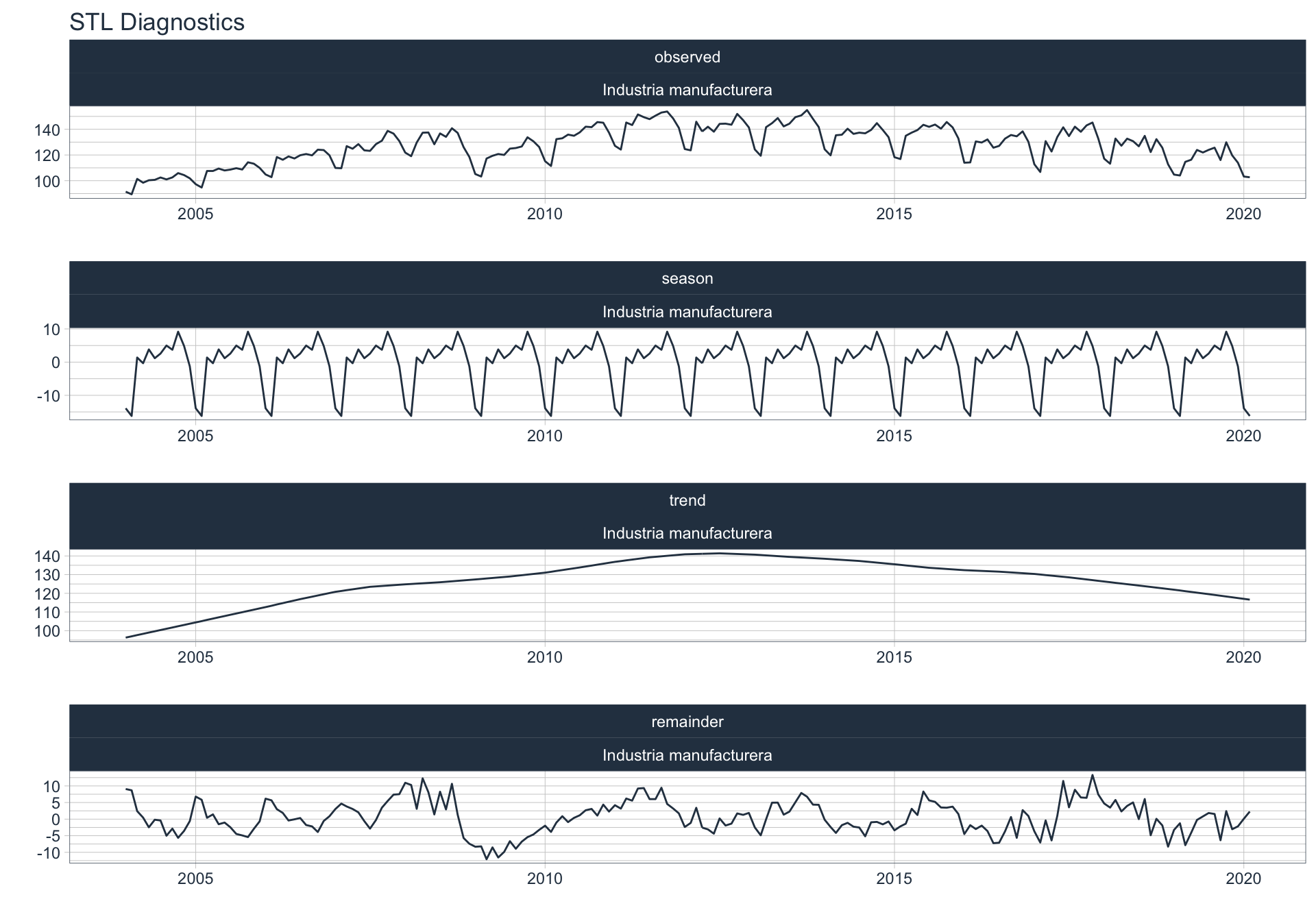
Construcción
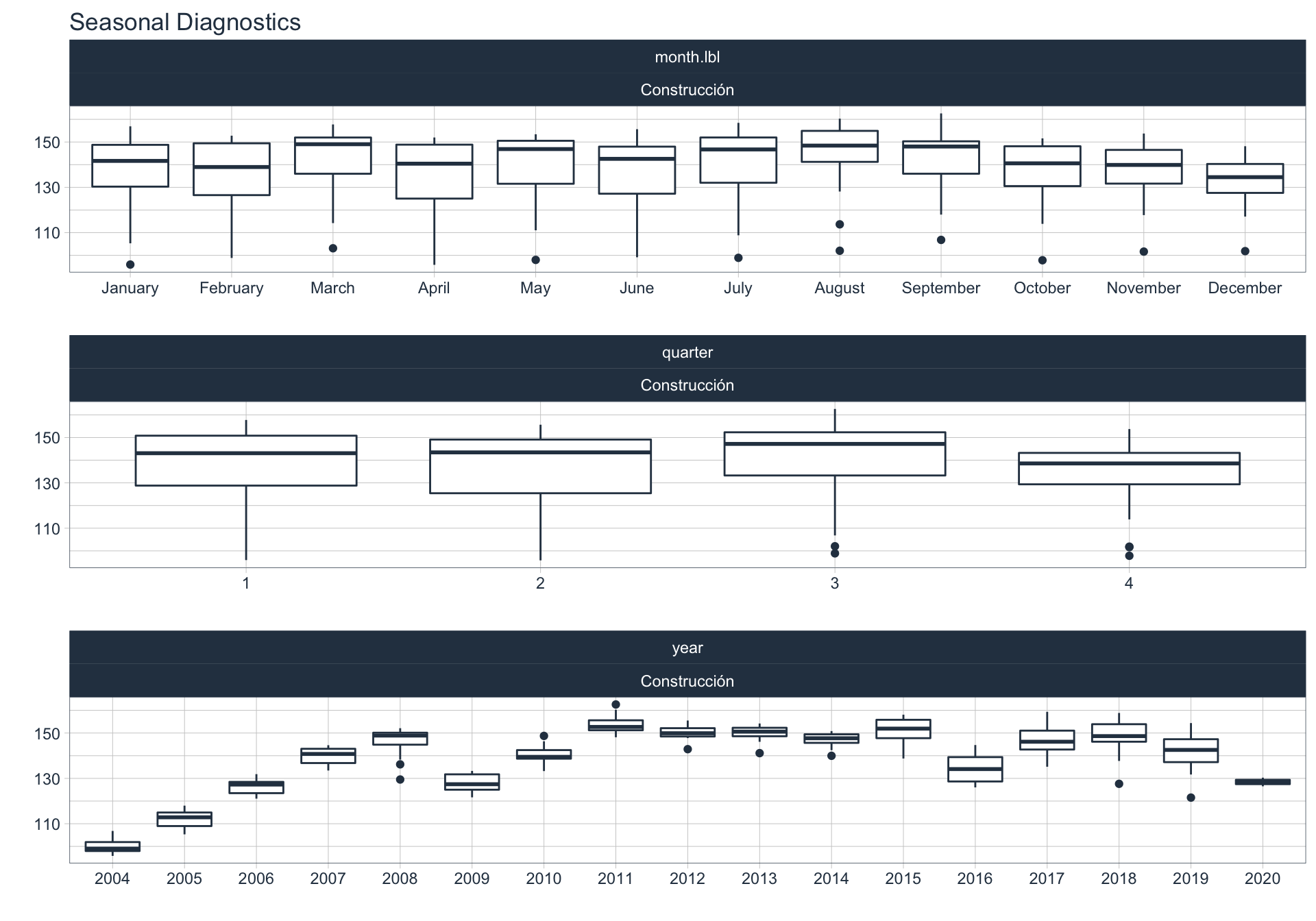
Estacionalidad 🏖
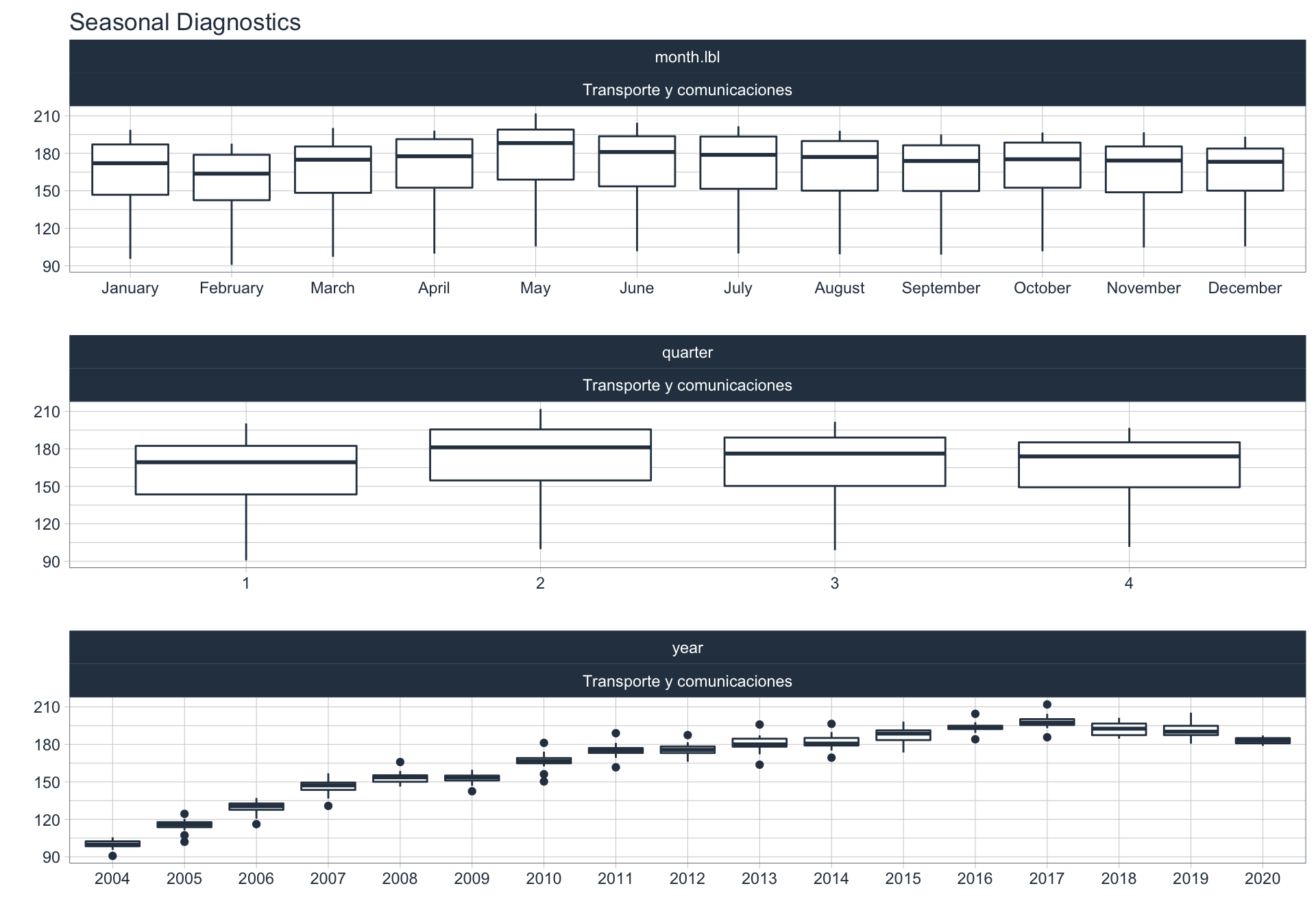
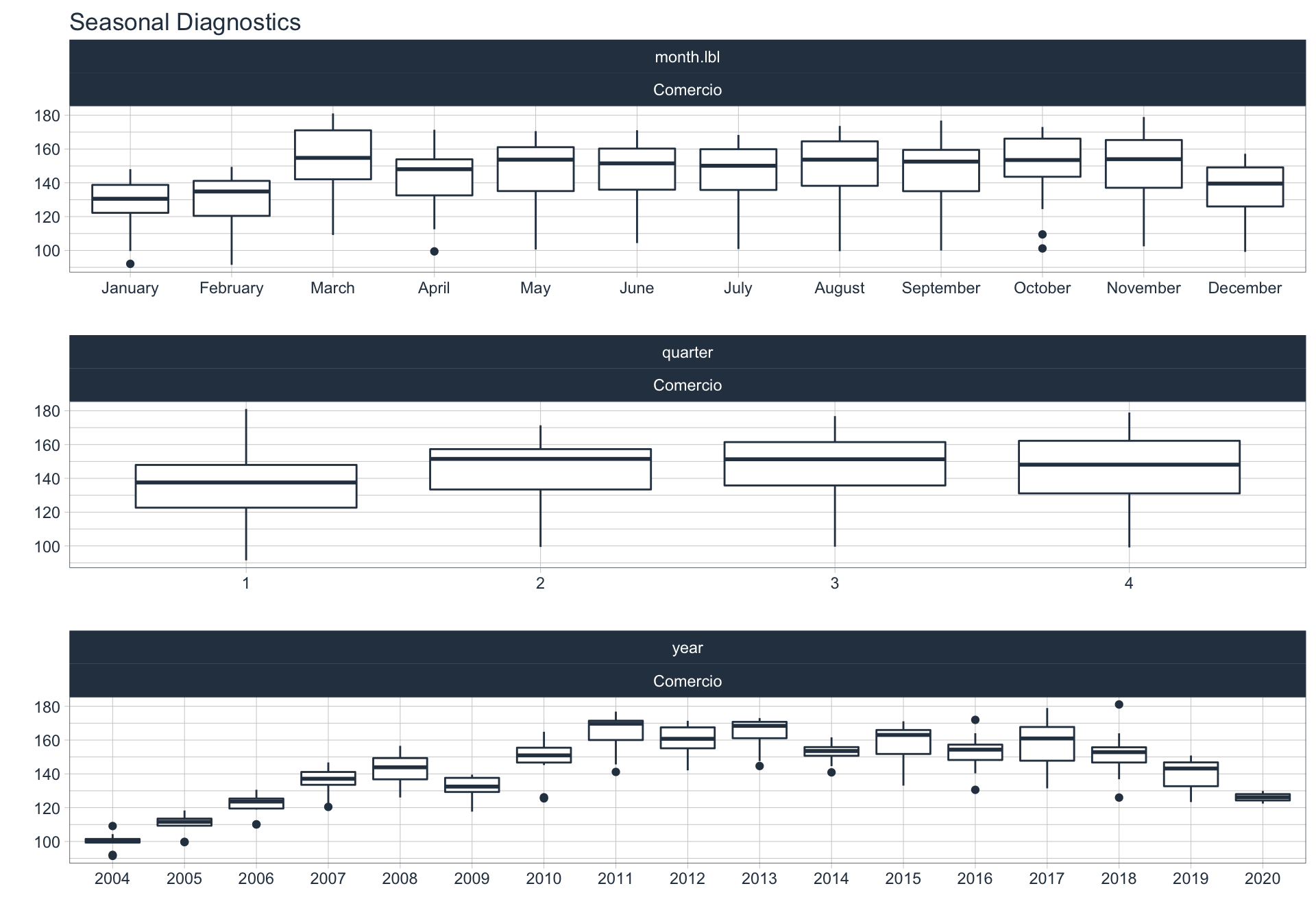
En este punto analizamos la estacionalidad 📆 en cada serie.
Para observar la estacionalidad en alguna de las series se utiliza la siguiente sintaxis:
df_emae %>%
filter(sector=='Transporte y comunicaciones', date <= FECHA) %>%
group_by(sector) %>%
plot_seasonal_diagnostics(date, value, .interactive = FALSE)
Transporte y comunicaciones
Comercio
Enseñanza
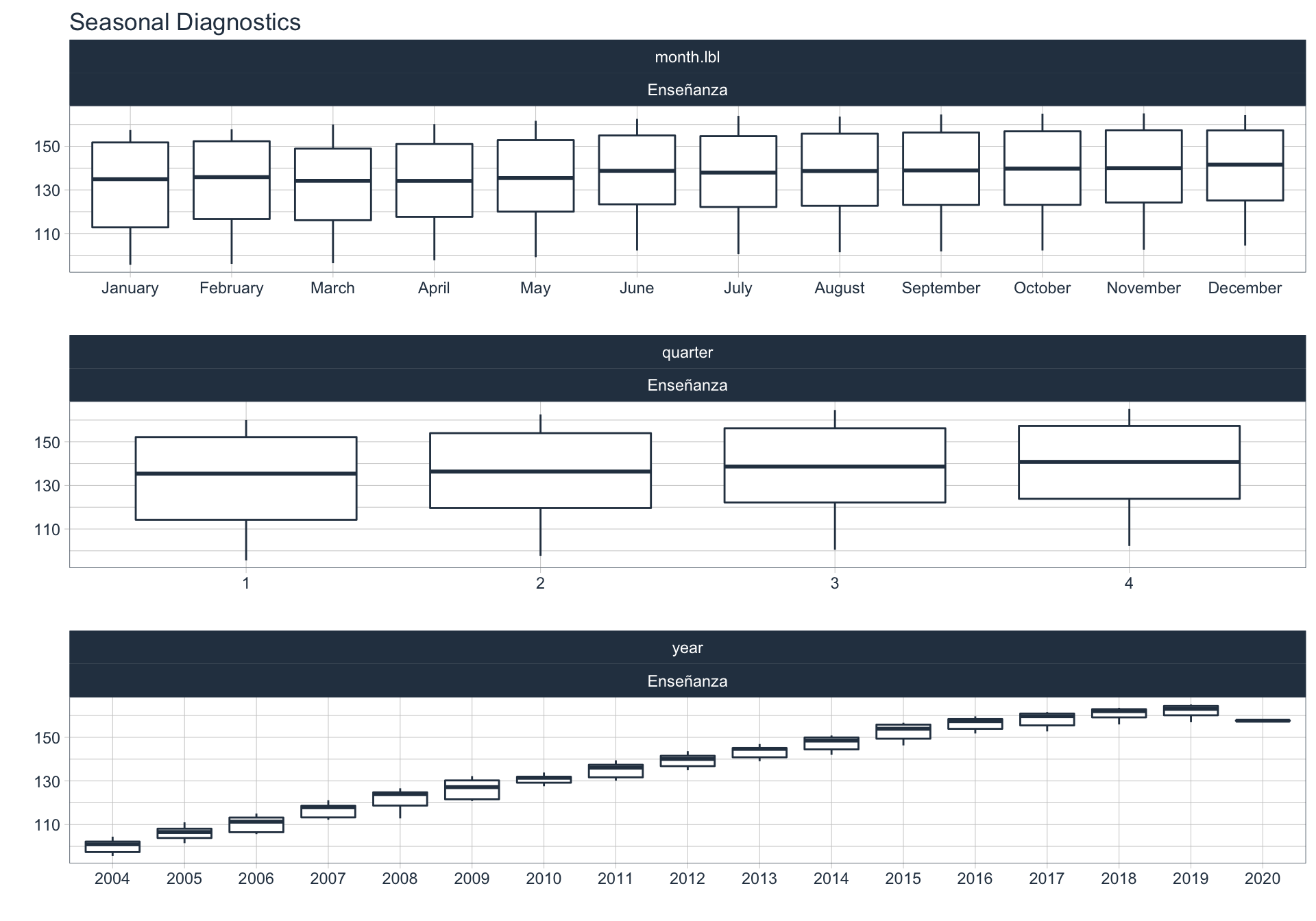
Admin pública
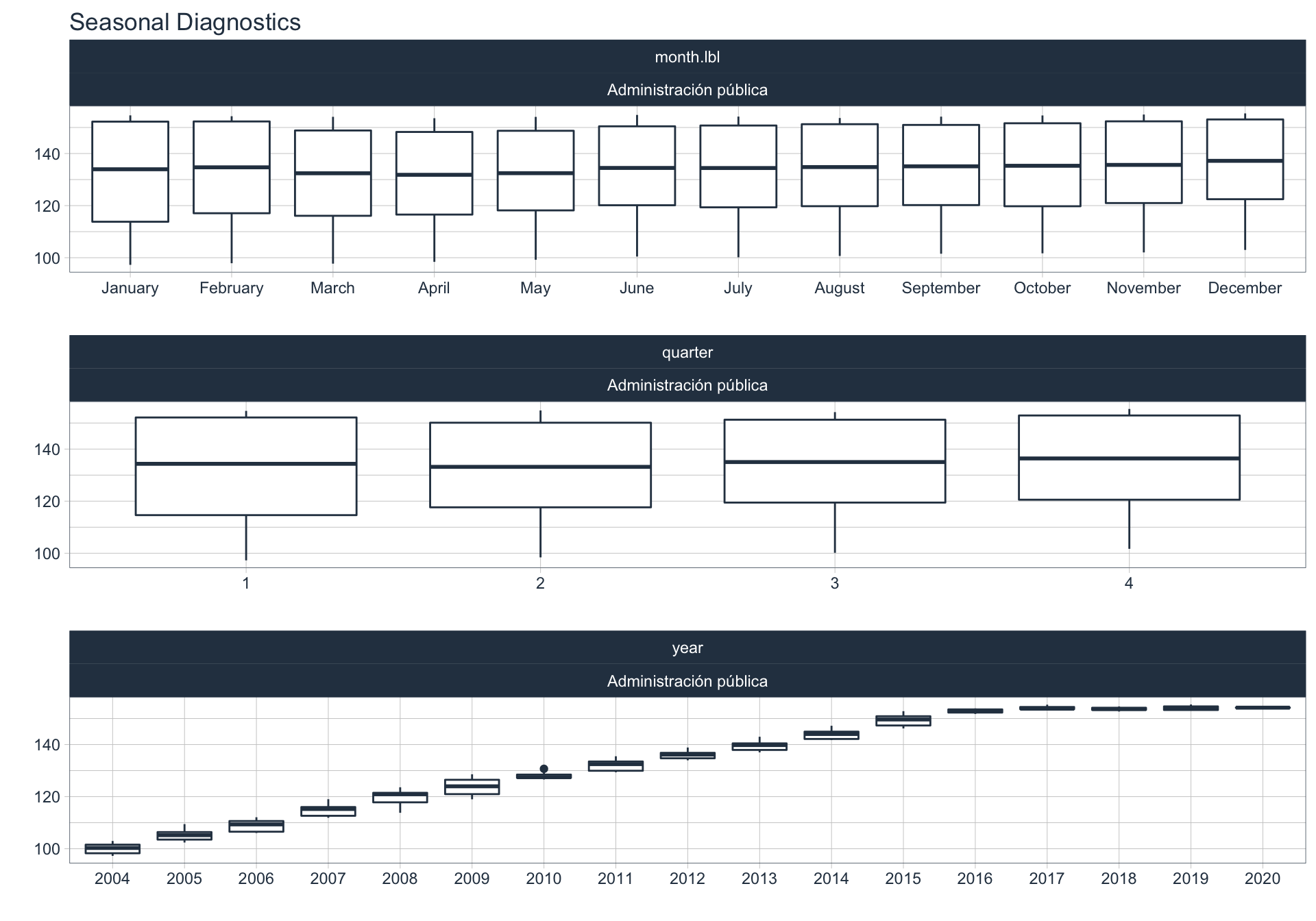
Servicios sociales/Salud
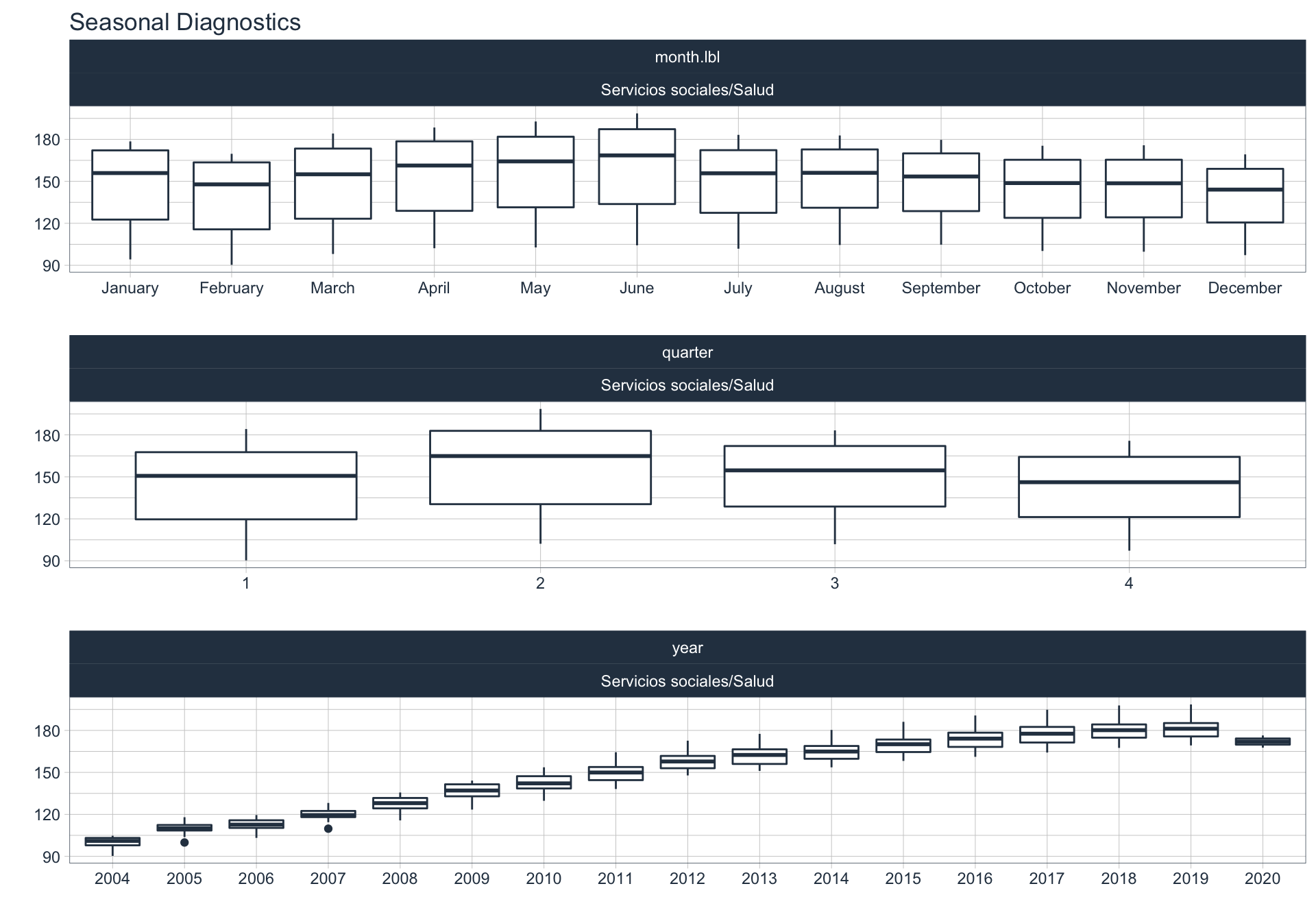
Impuestos netos
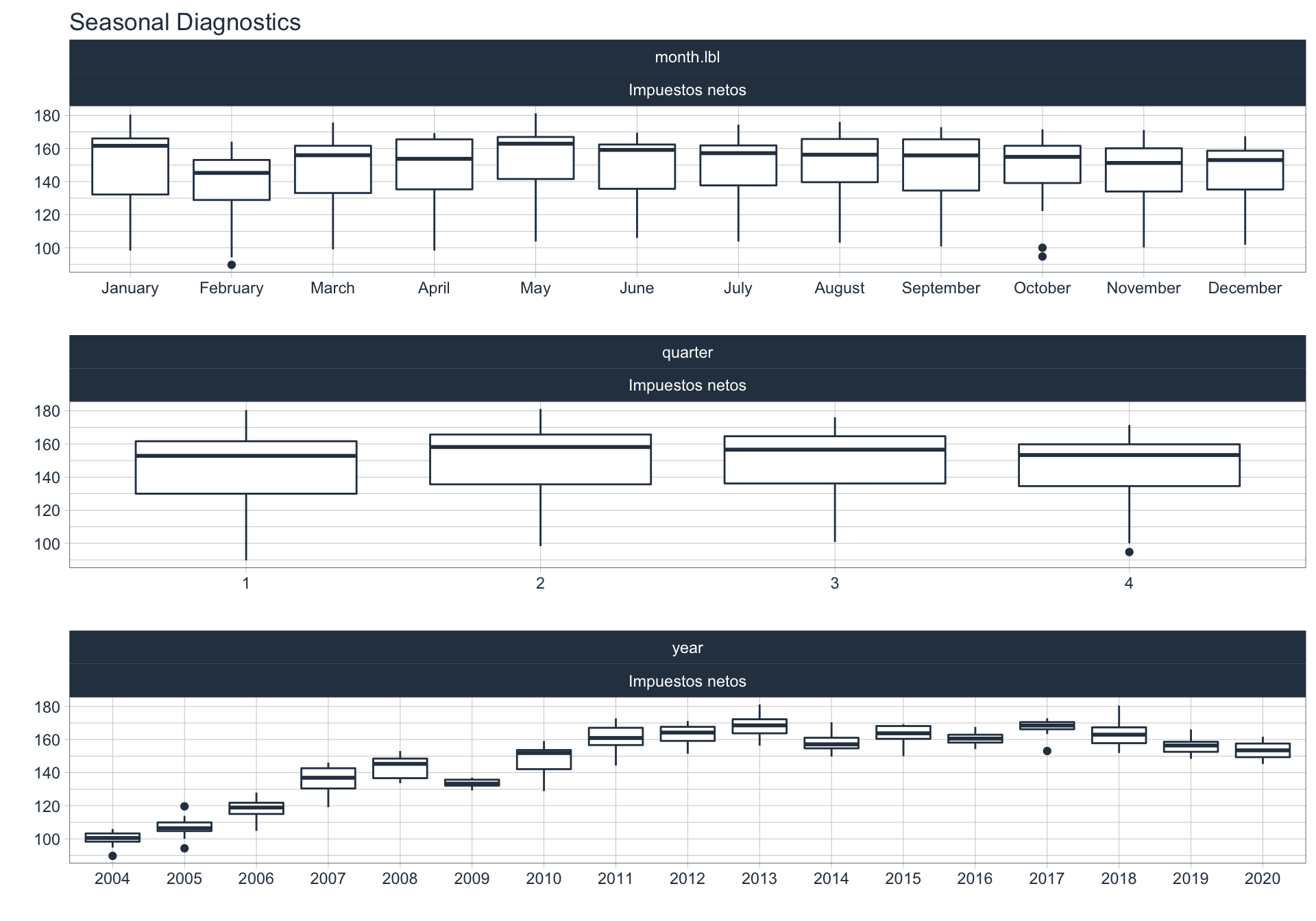
Sector financiero
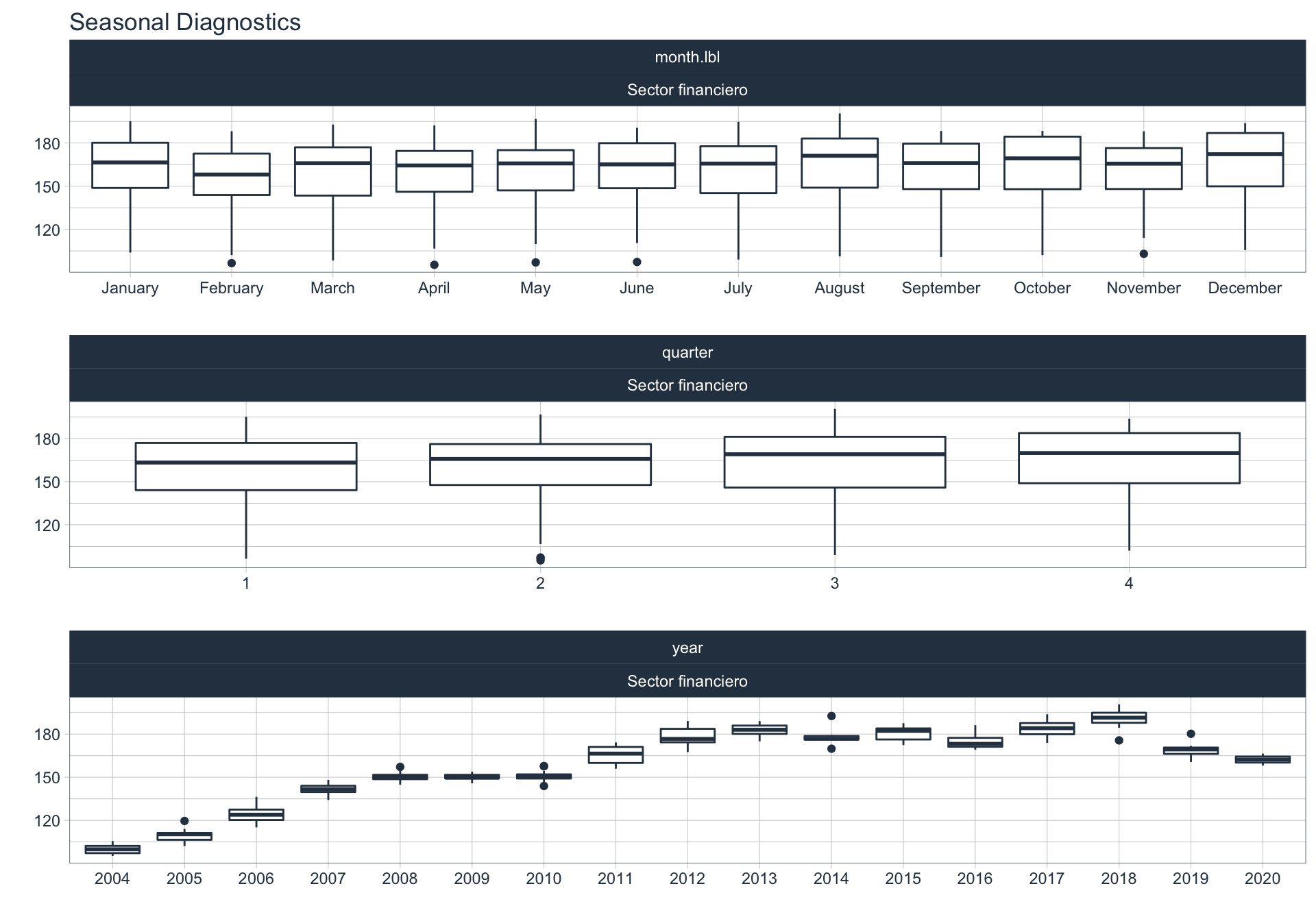
Minería
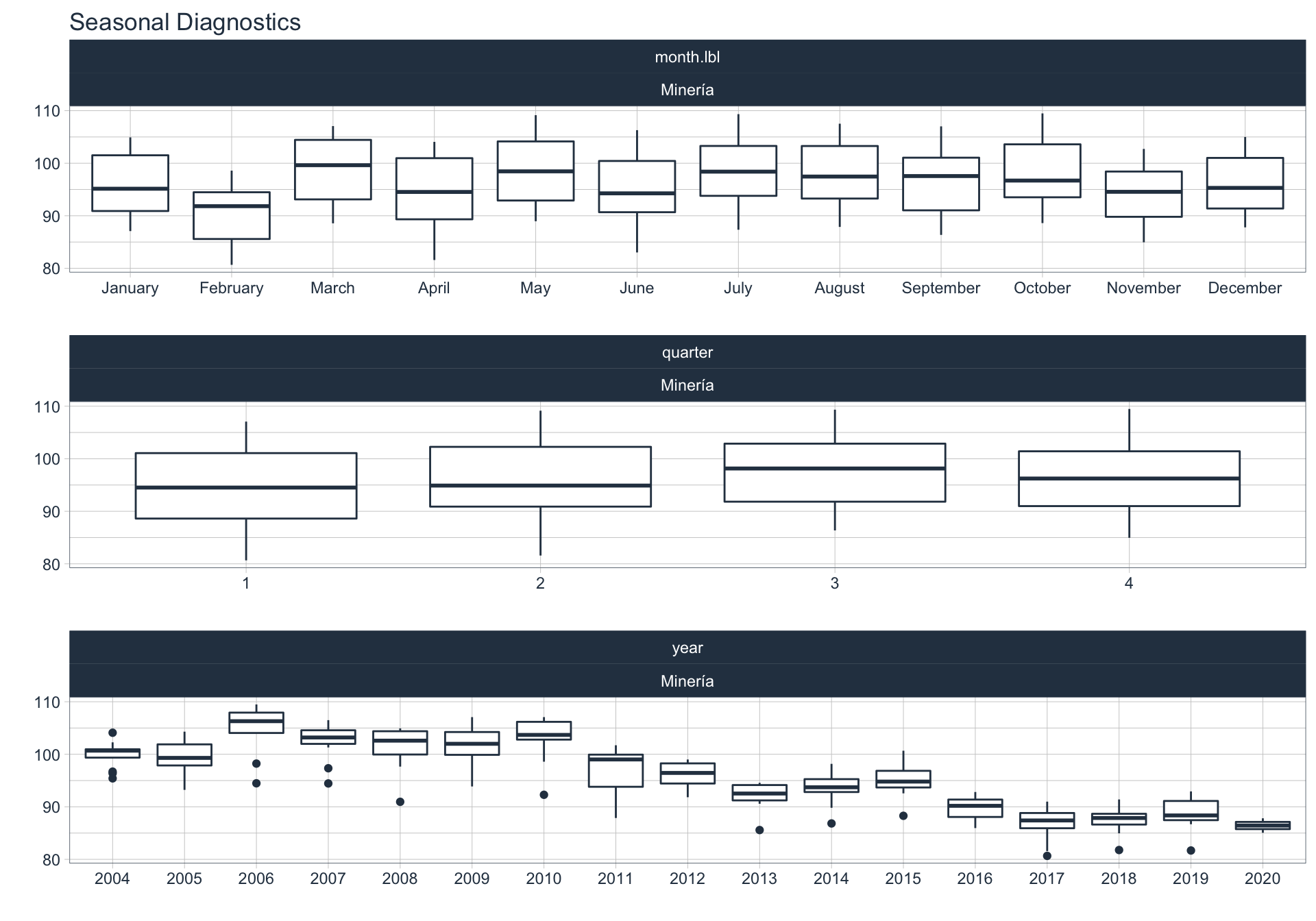
Agro/Ganadería/Caza/Silvicultura
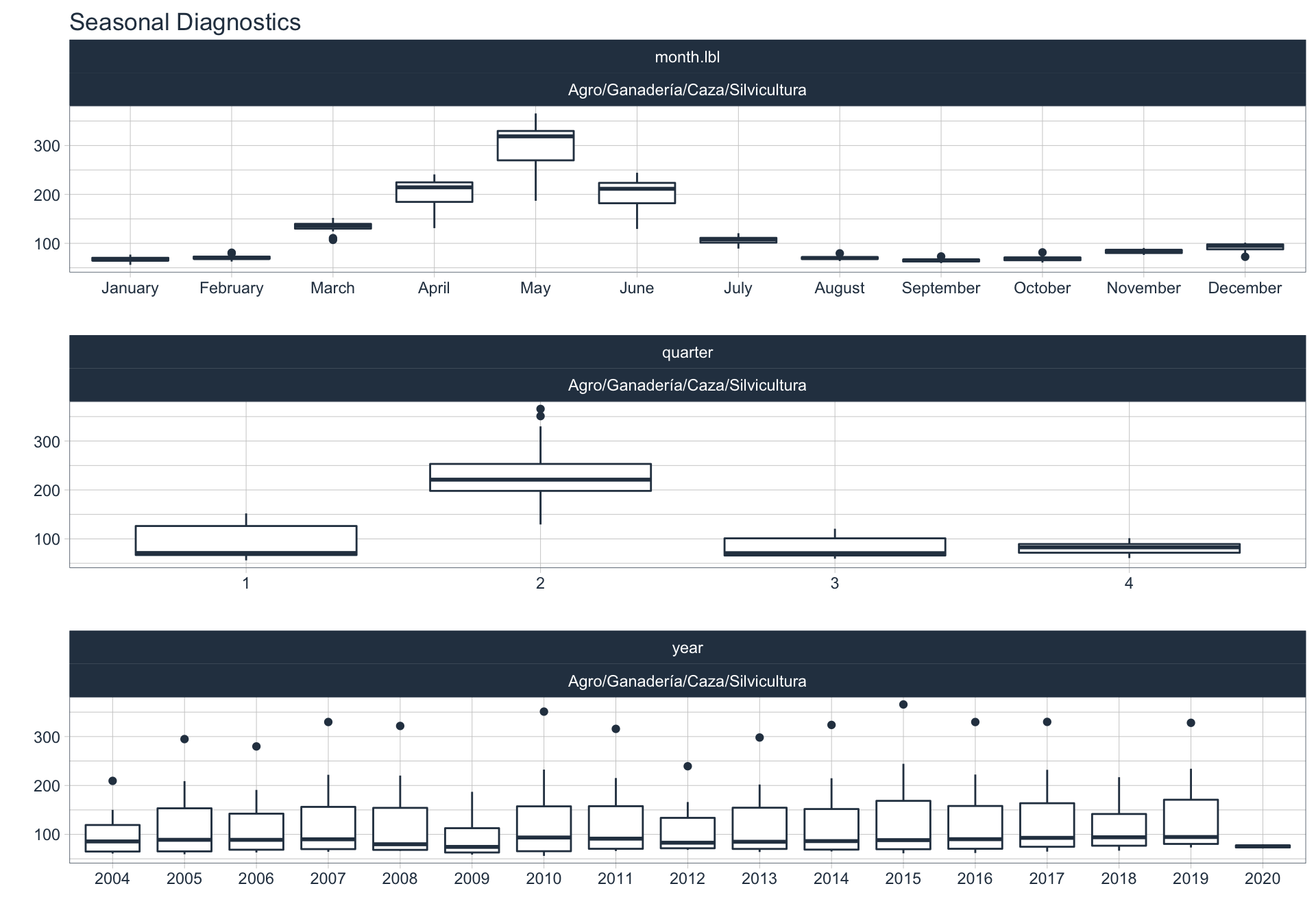
Elec/Gas/Agua
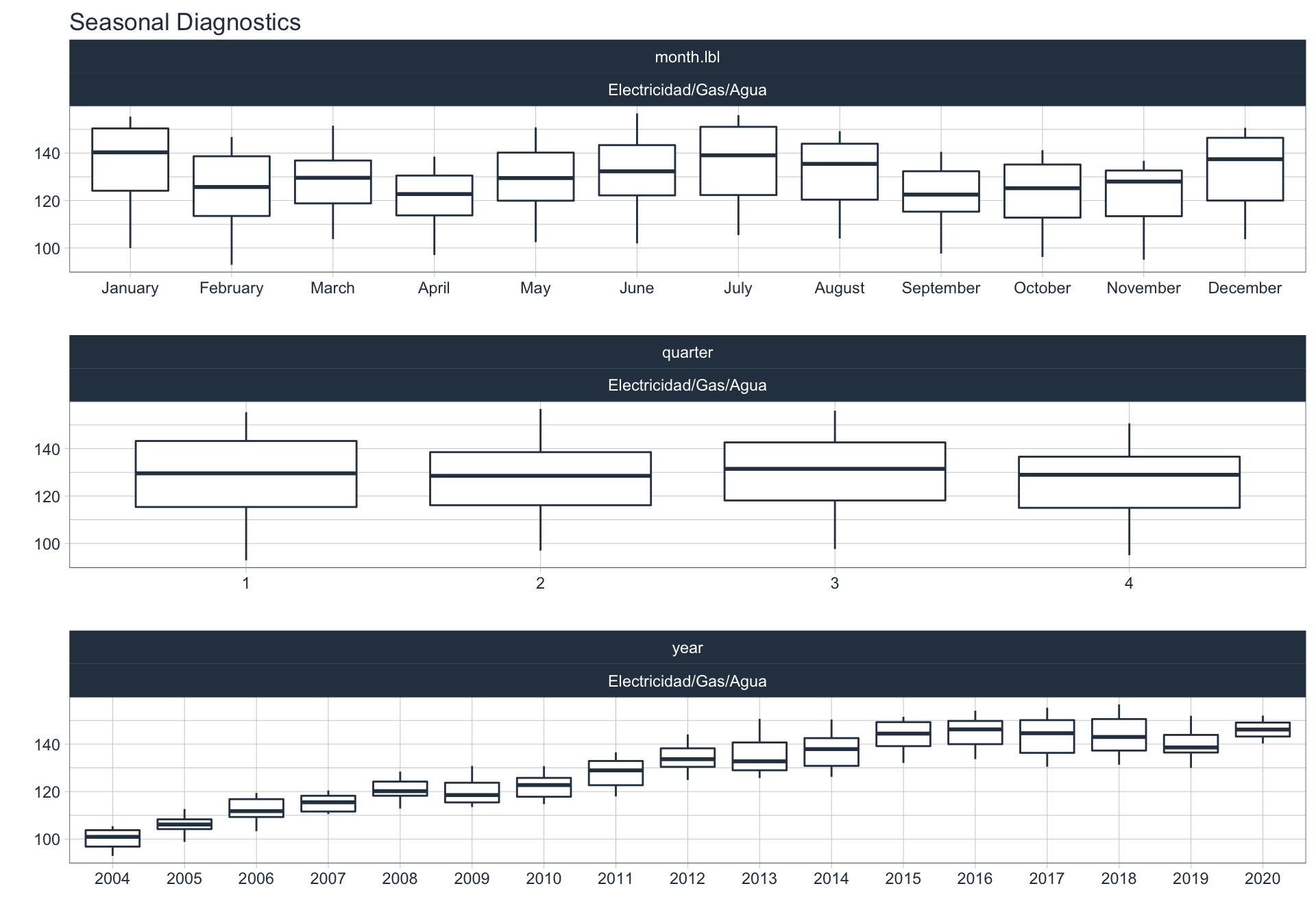
Hoteles/Rest
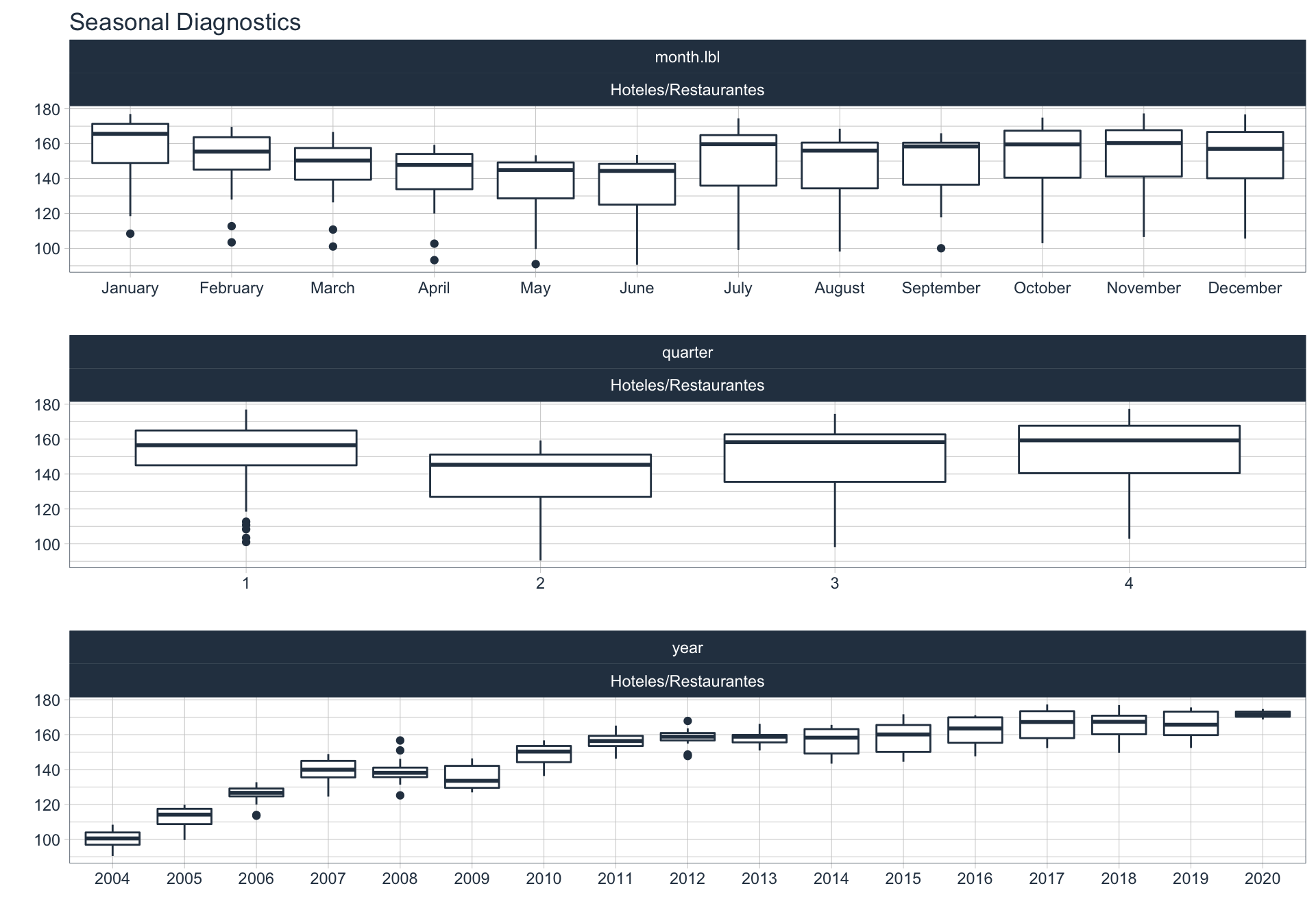
Inmobiliarias
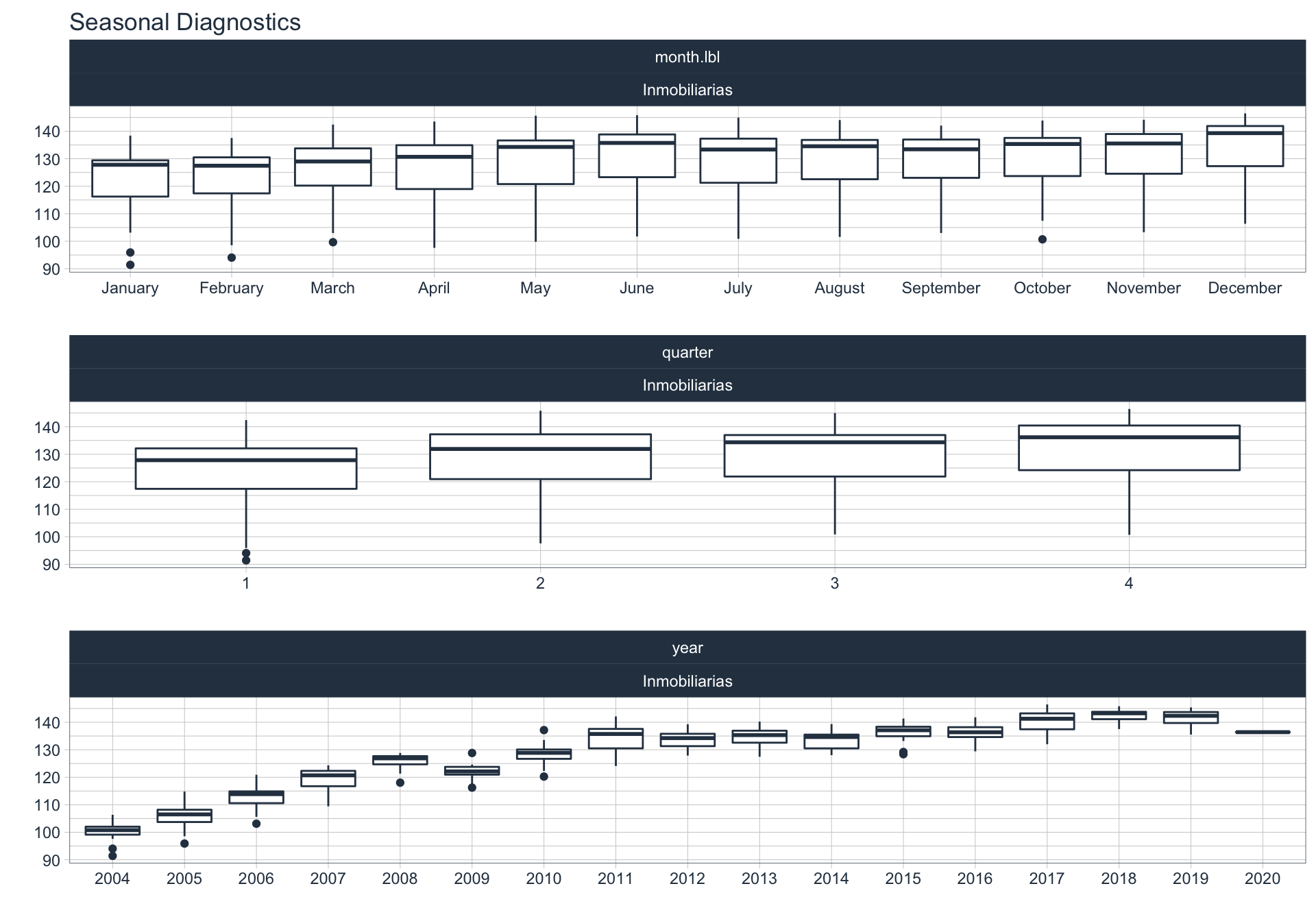
Otras actividades
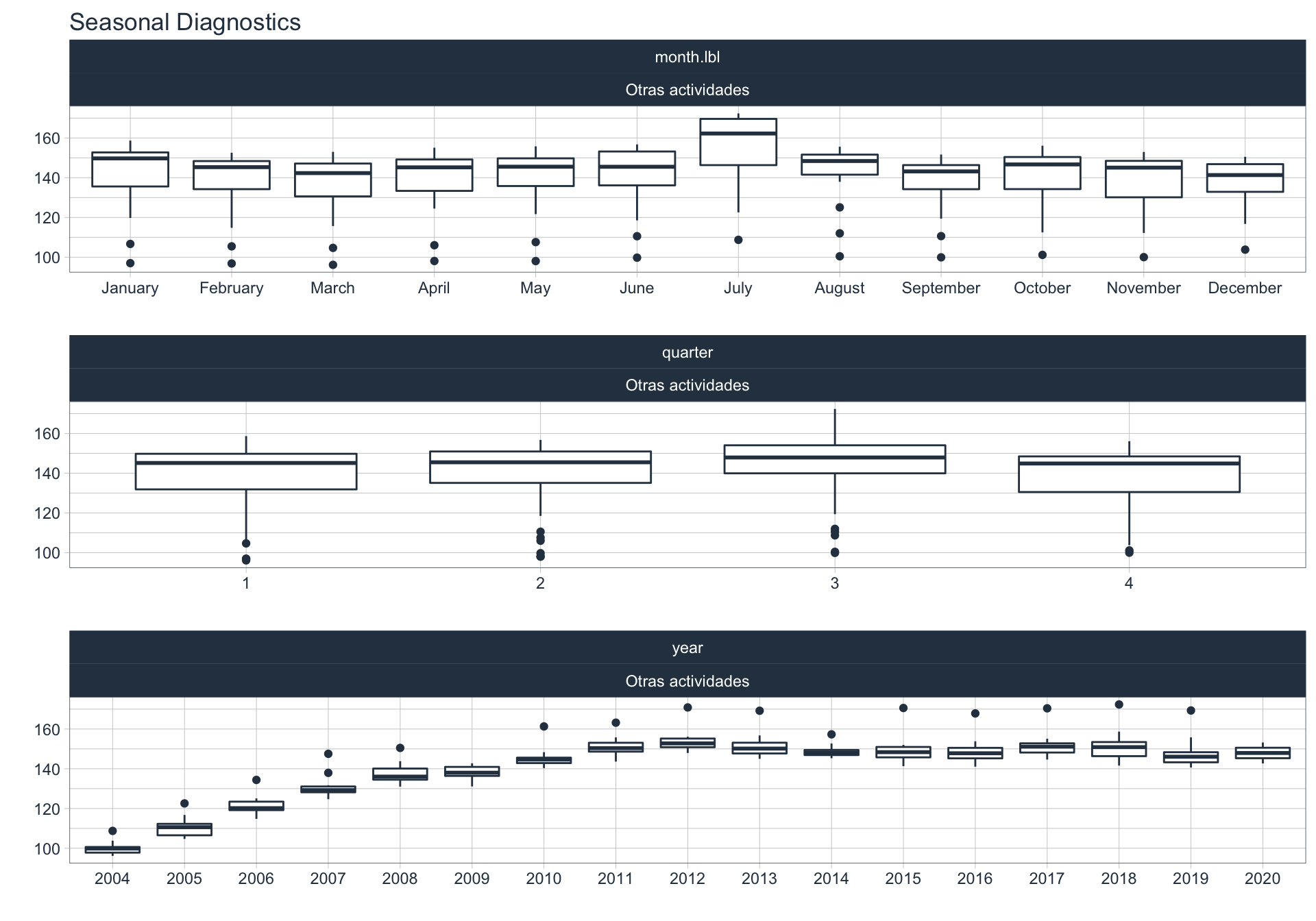
Pesca
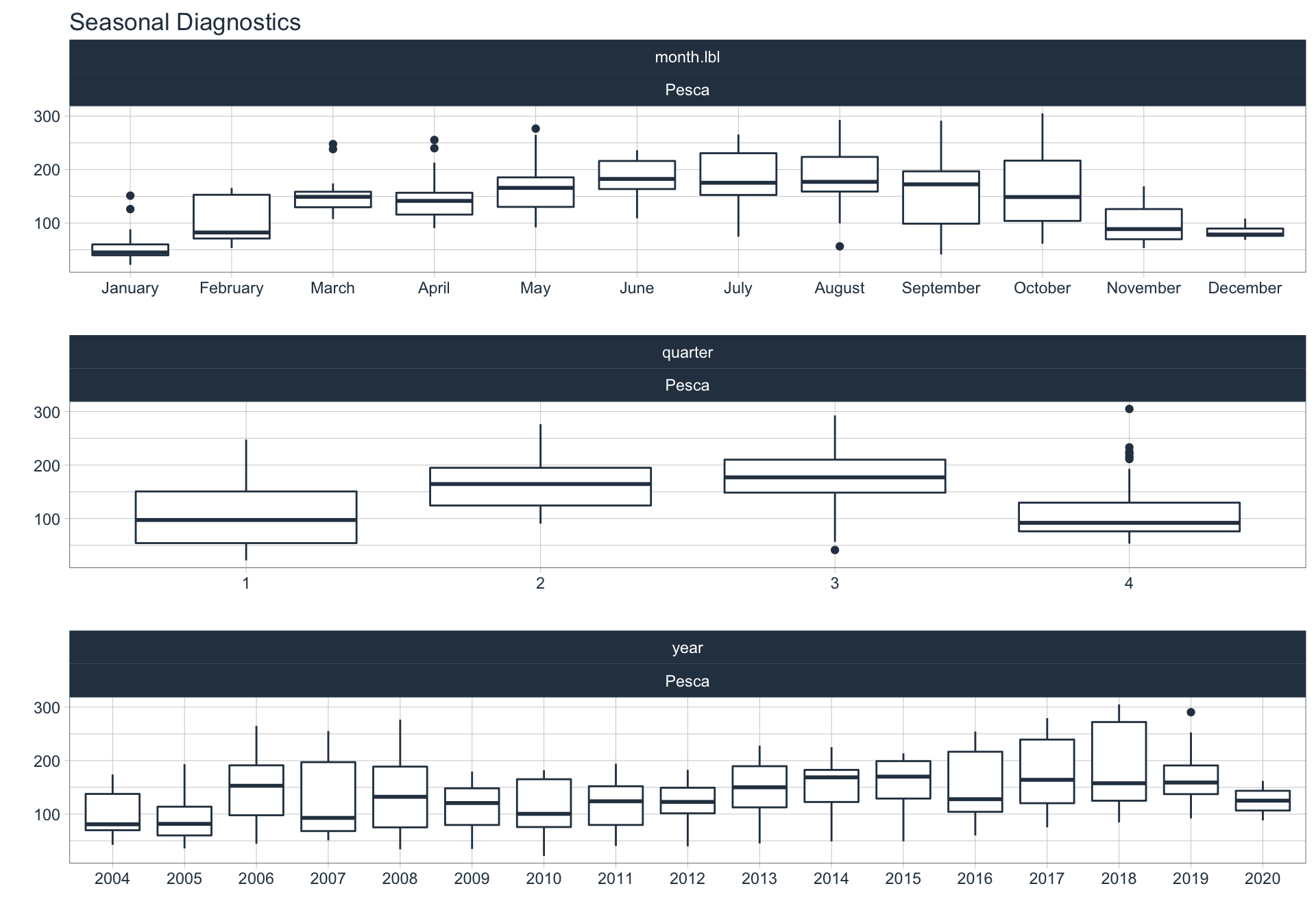
Industria Manufacturera
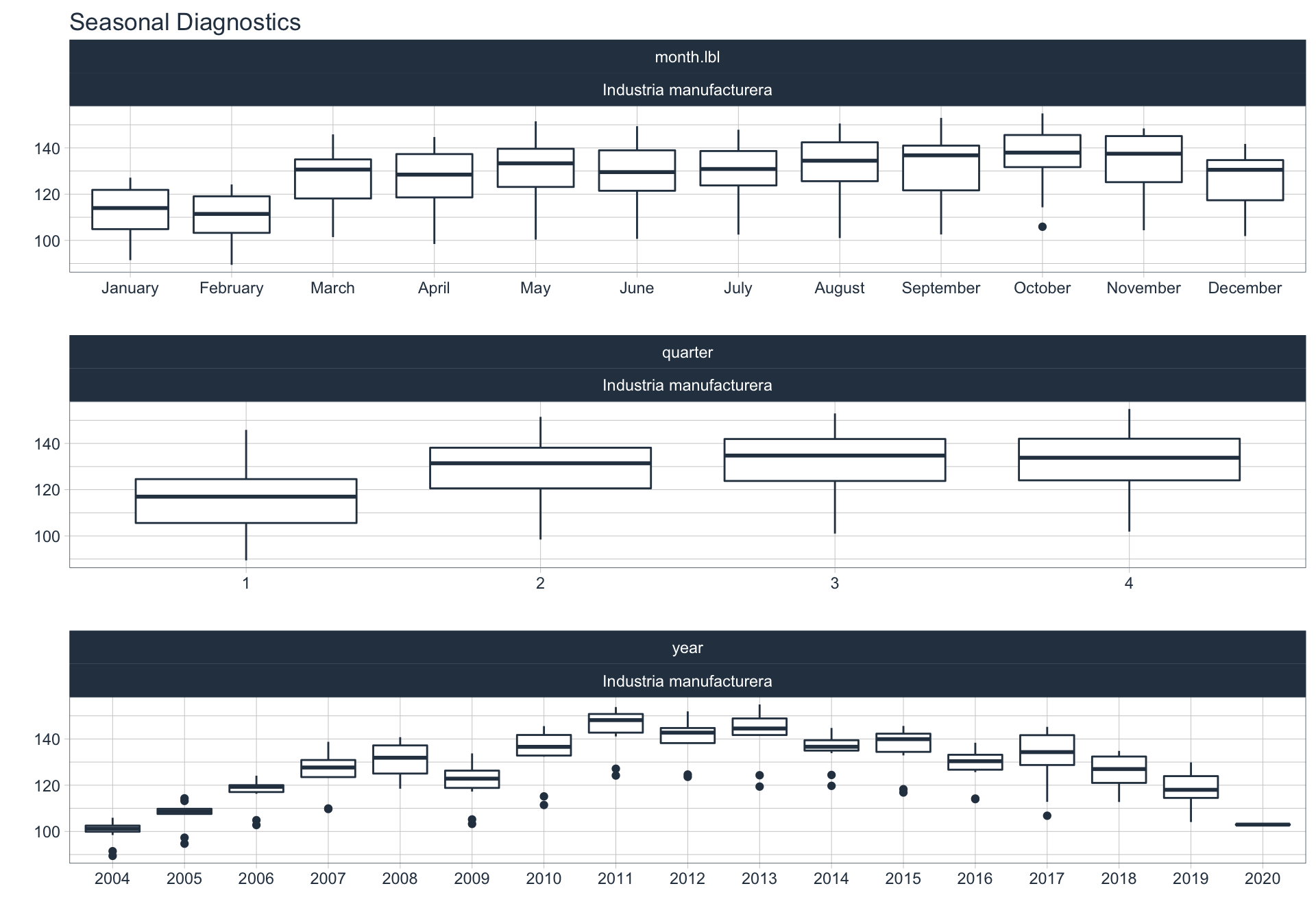
Construcción
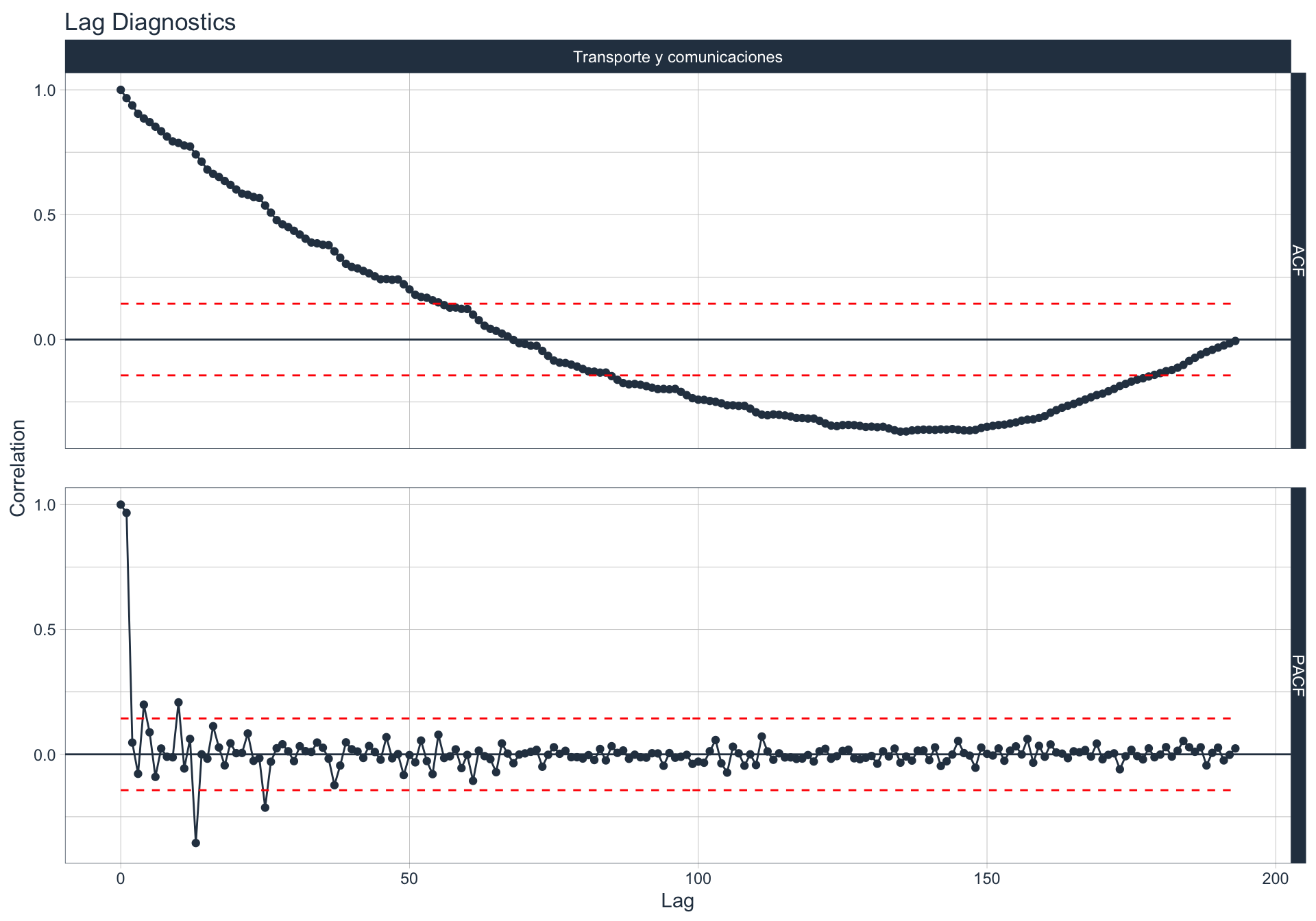
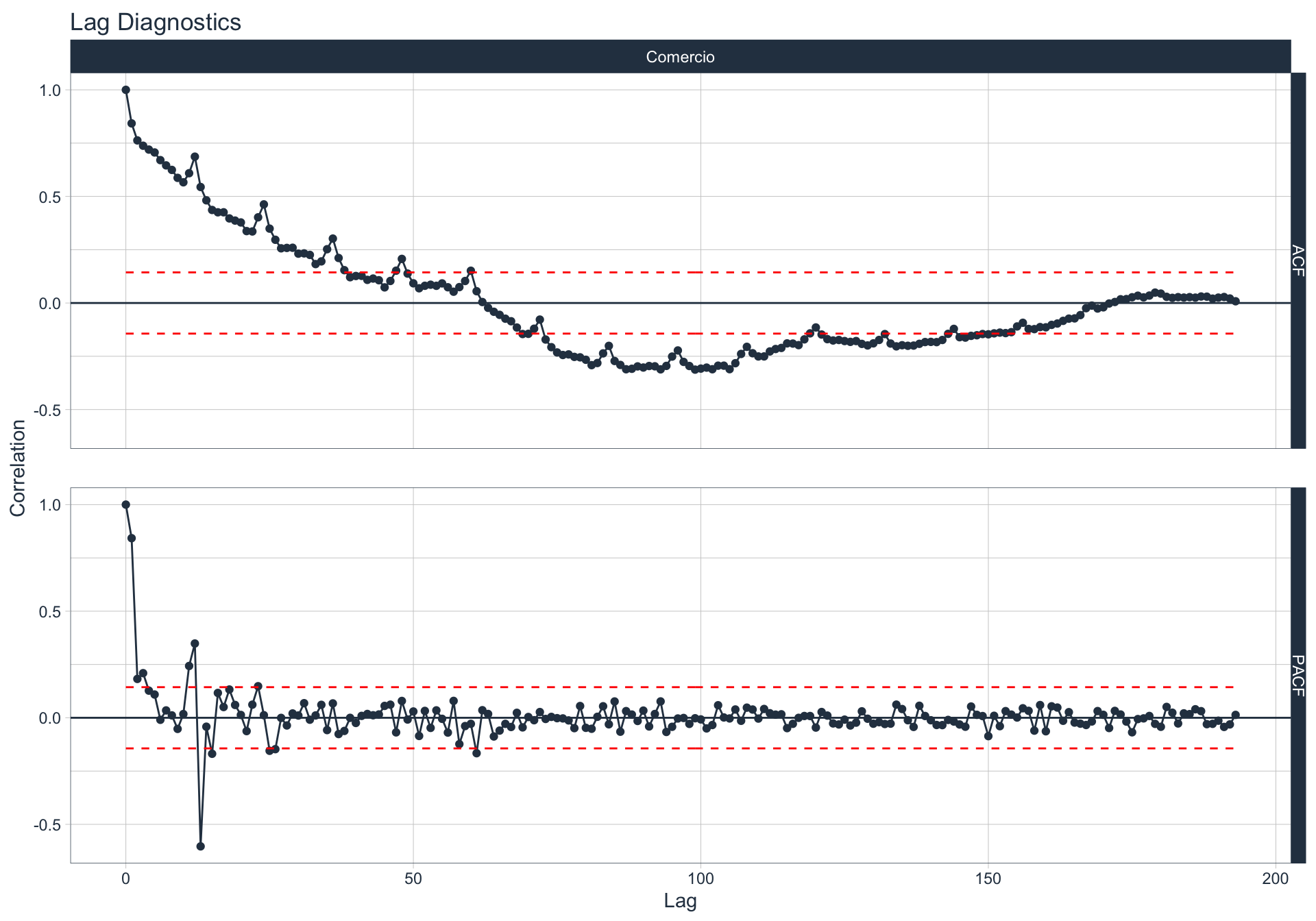
Autocorrelación y Autocorrelación parcial
🔍 La función de autocorrelación (ACF o autocorrelation function) mide la relación lineal entre una variable temporal y sus rezagos6.
\(r_t = Corr(y_{t}, y_{t-1})\), donde \(t \in [1,T]\)
🔍 La función de autocorrelación parcial (PACF, o partial autocorrelation function) mide la correlación de una variable temporal y sus rezagos, removiendo el efecto de otros rezagos más recientes.
\(v_t = \begin{cases} \ Corr(y_0,y_1) = r_1 & t=1 \\ Corr(y_0 - y_0^{t-1},y_{t}-y_t^{t-1}) & t>=2 \\ \end{cases}\)
Algunas series son no estacionarias.
🔹Para realizar la evaluación de autocorrelación en alguna de las series se utiliza la siguiente sintaxis:
df_emae %>% filter(sector=='Transporte y comunicaciones', date <= FECHA) %>%
group_by(sector) %>%
plot_acf_diagnostics(date, value,
.show_white_noise_bars = TRUE,
.white_noise_line_color = 'red',
.white_noise_line_type = 2,
.line_size=0.5,
.point_size=1.5,
.interactive = FALSE)
Transporte
Comercio
Enseñanza
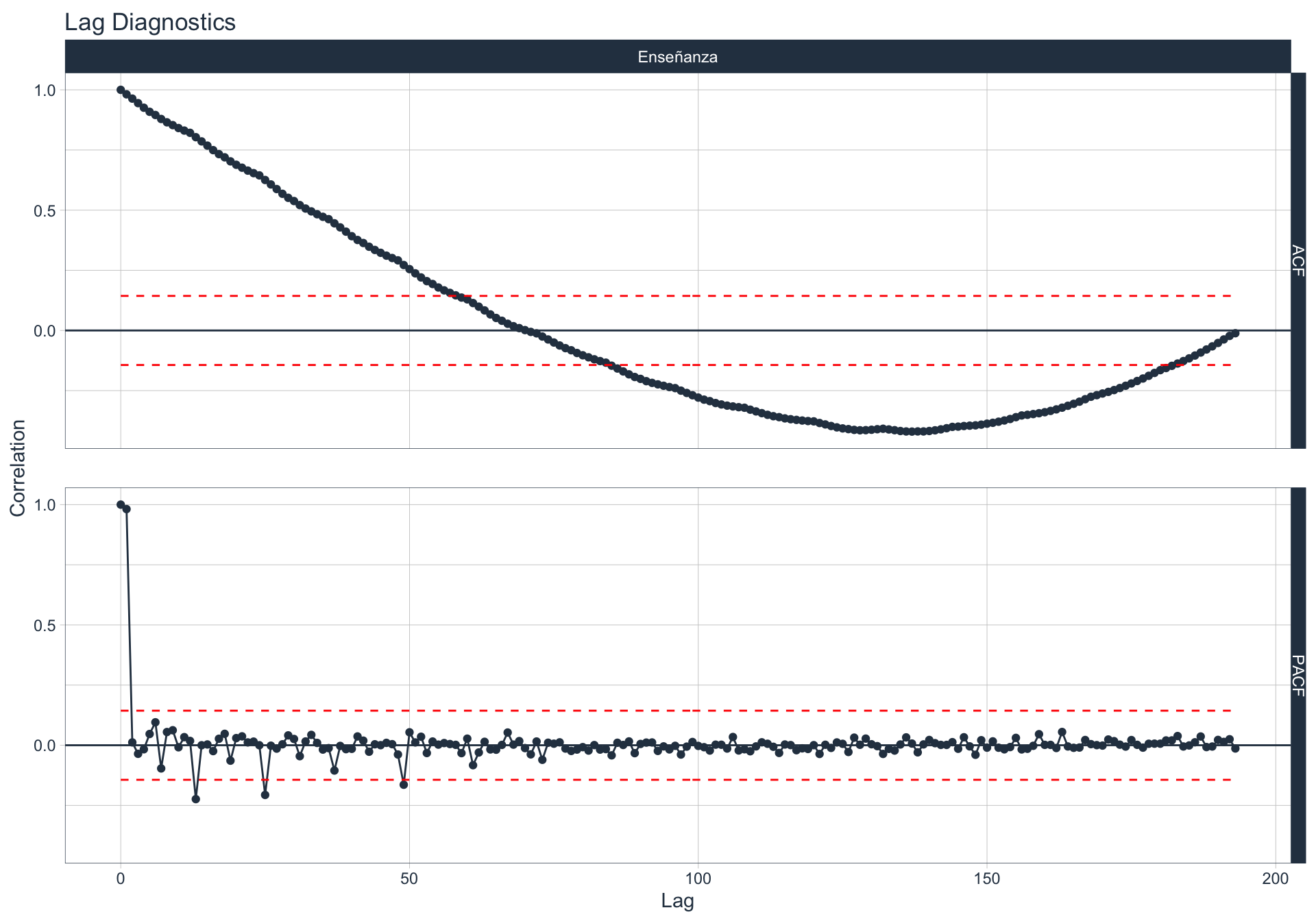
Administración pública
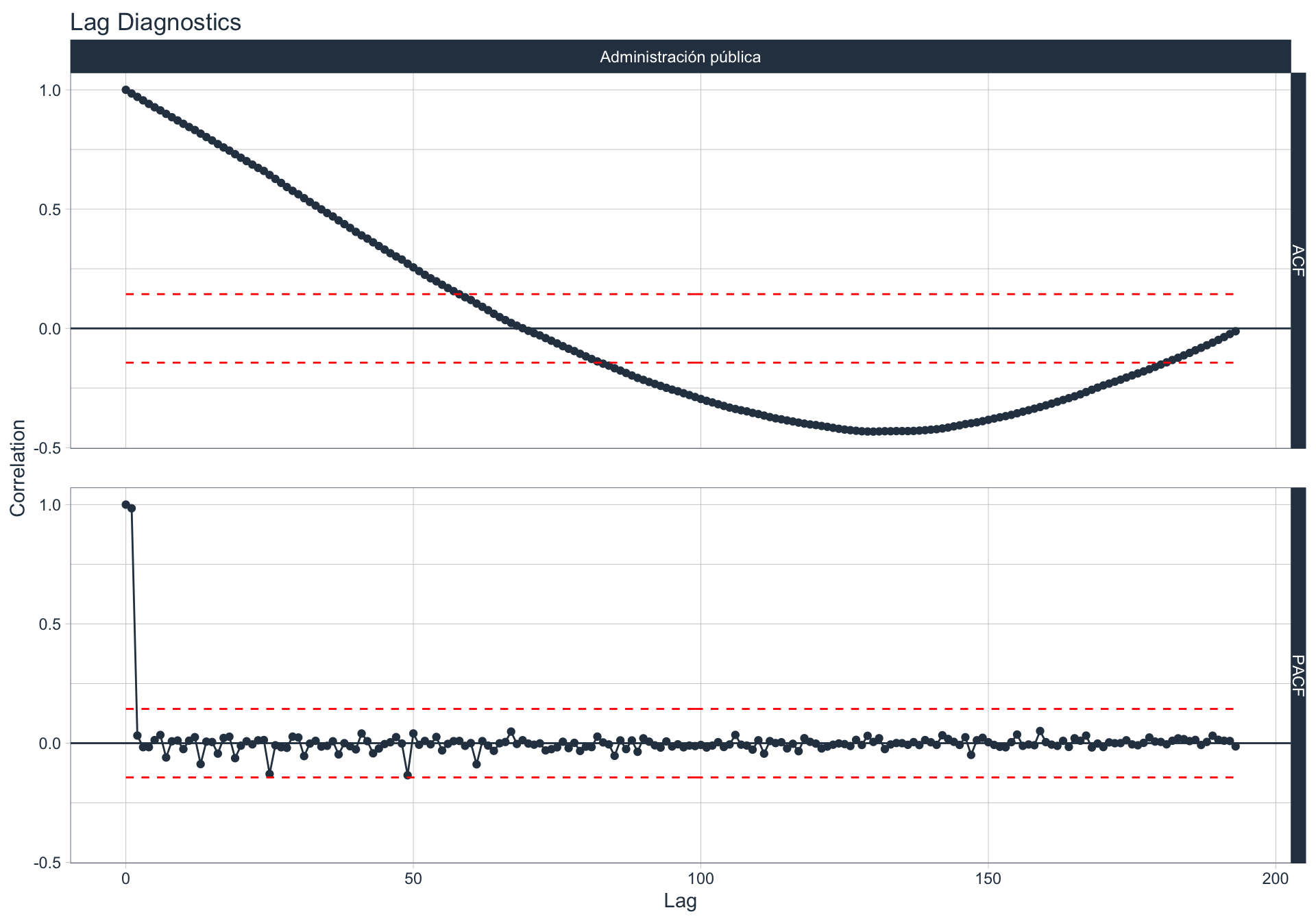
Servicios sociales/Salud
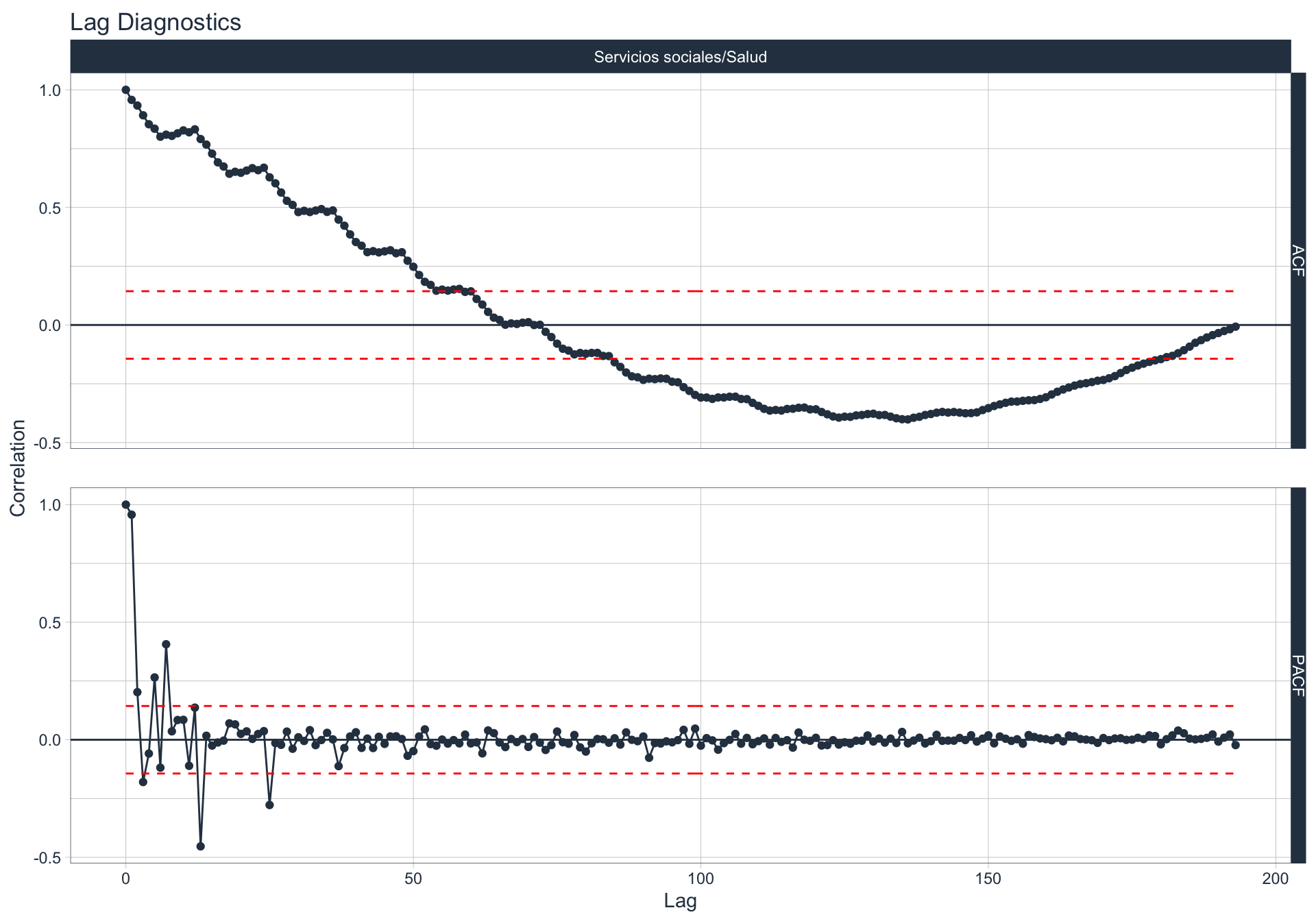
Impuestos netos
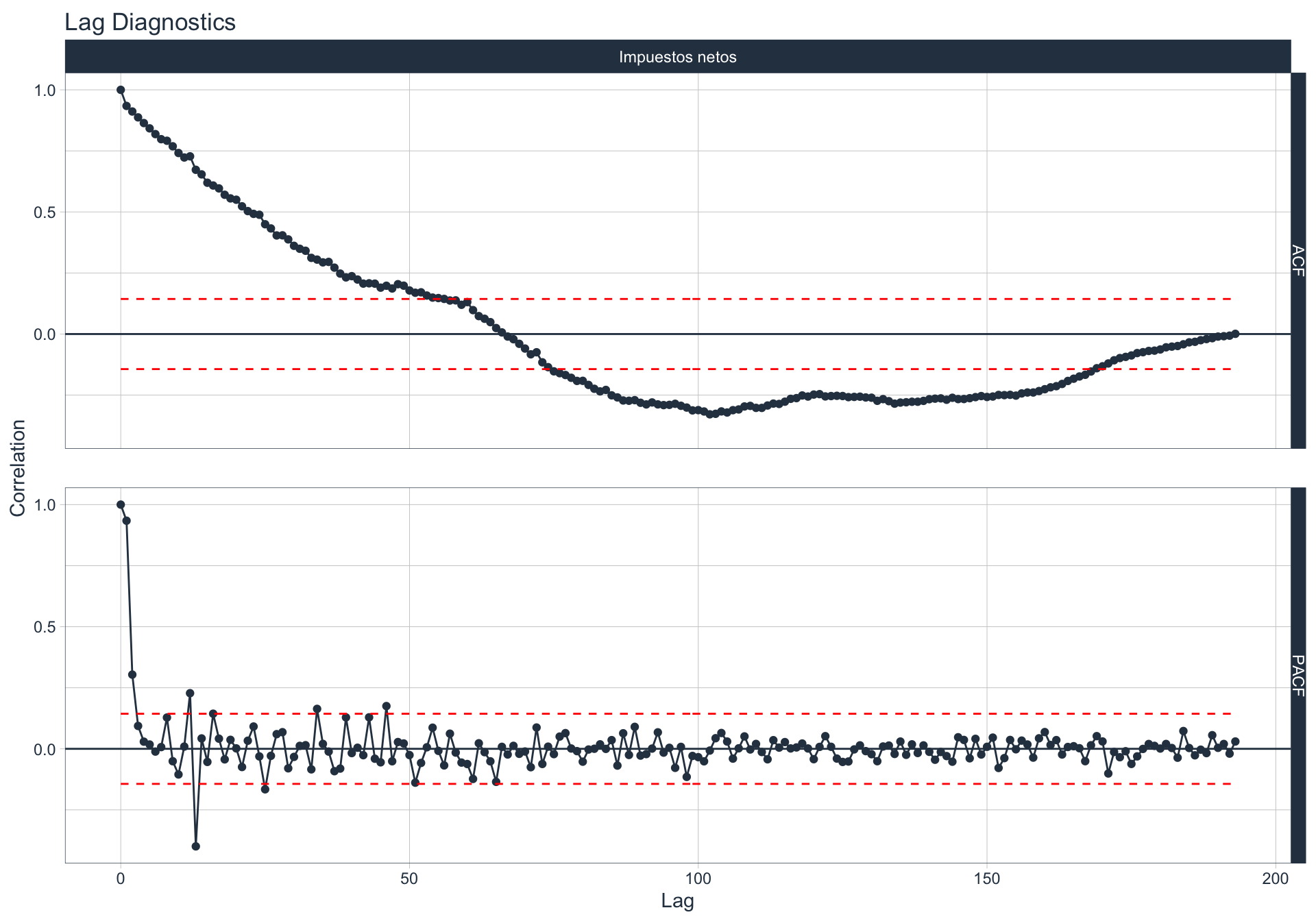
Sector financiero
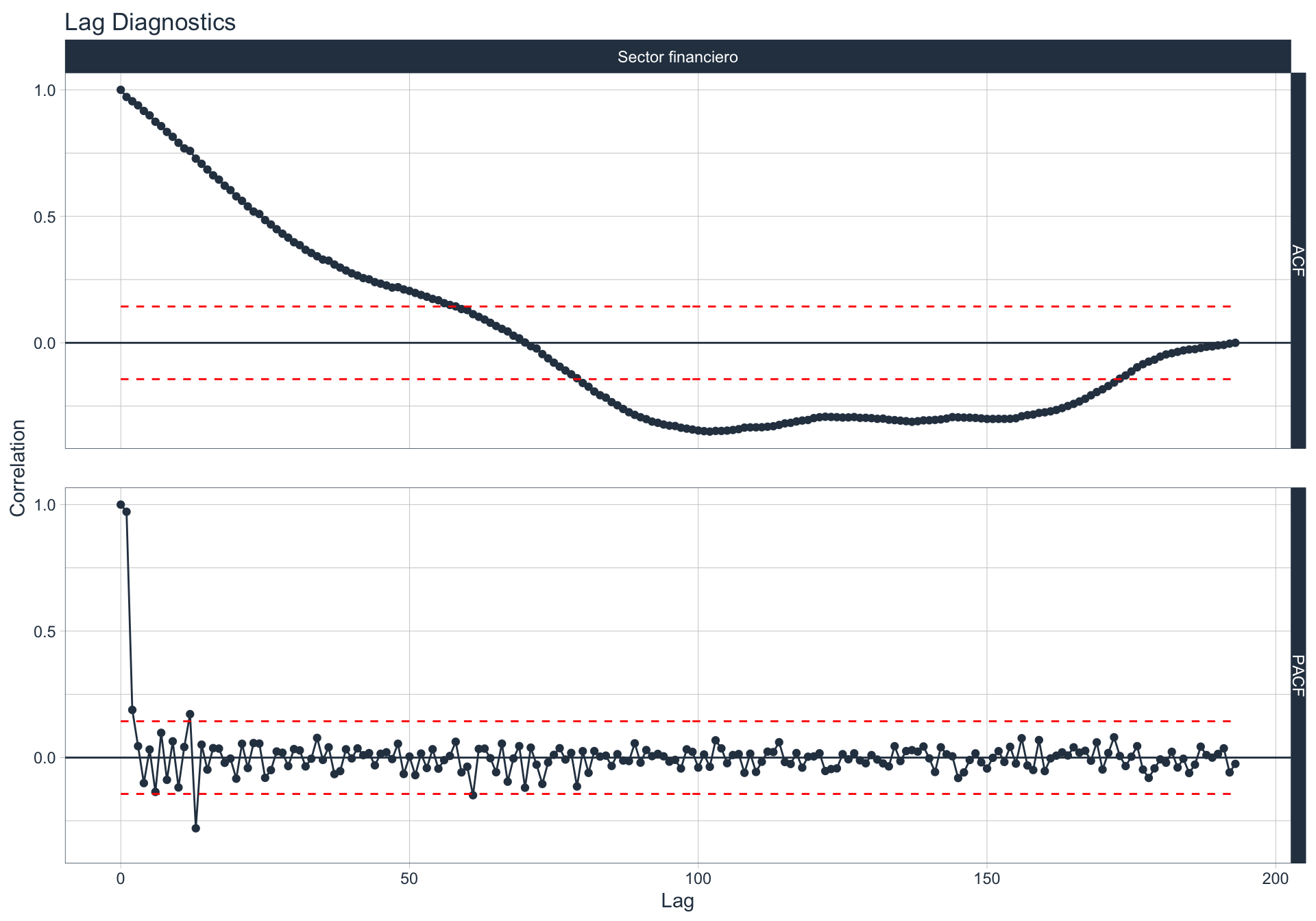
Minería
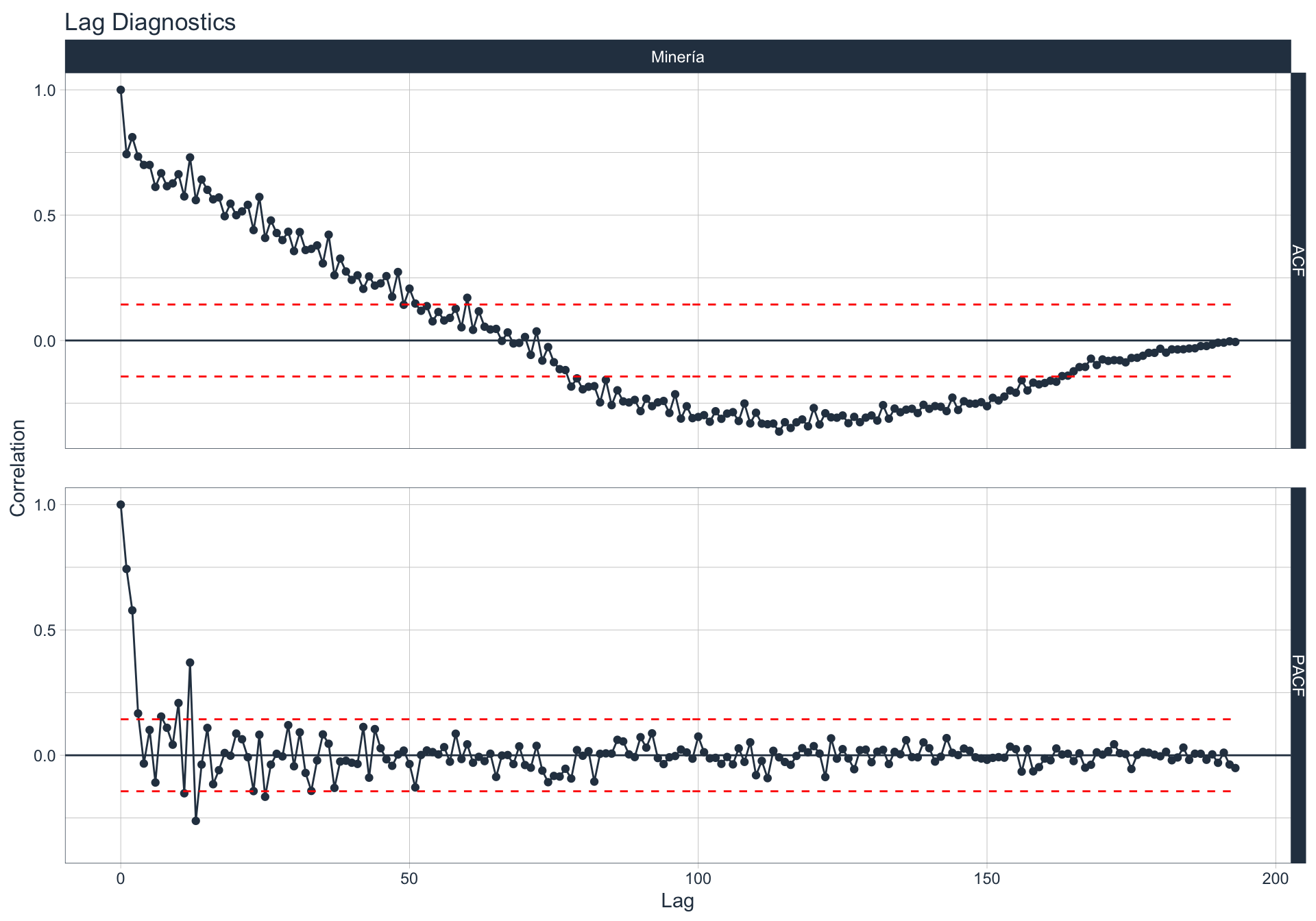
Agro/Ganadería/Caza/Silvicultura
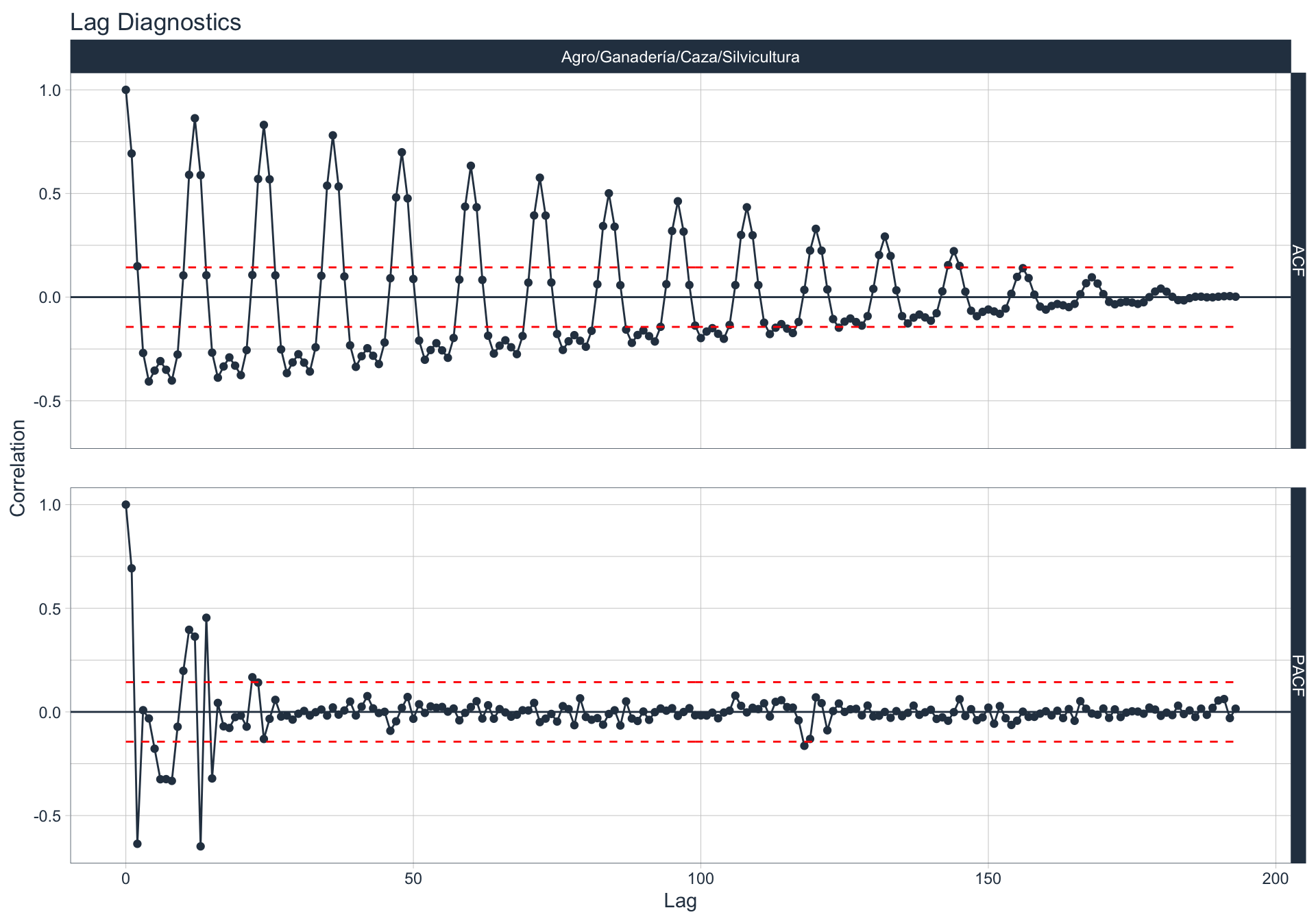
Elec/Gas/Agua
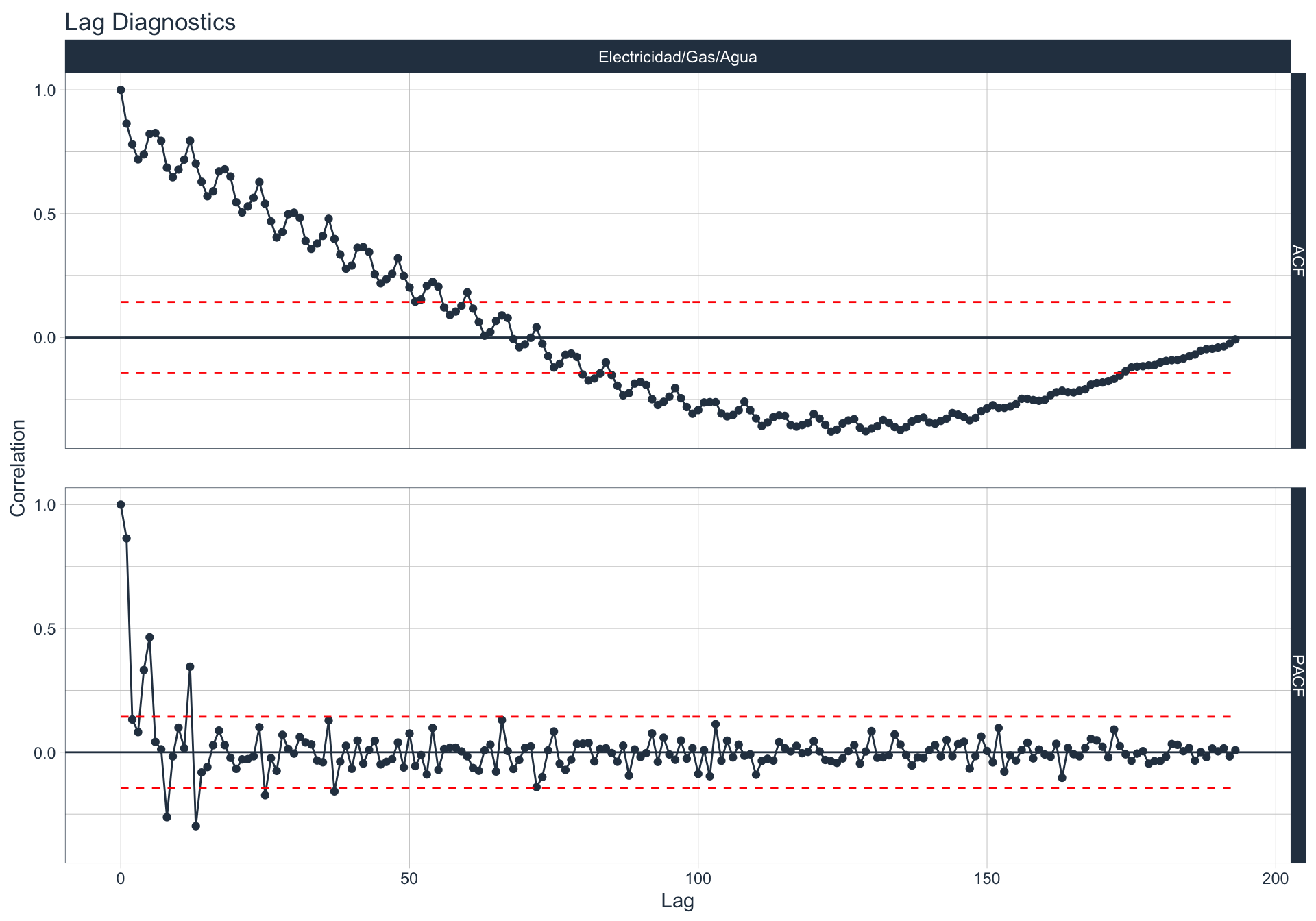
Hoteles/Rest
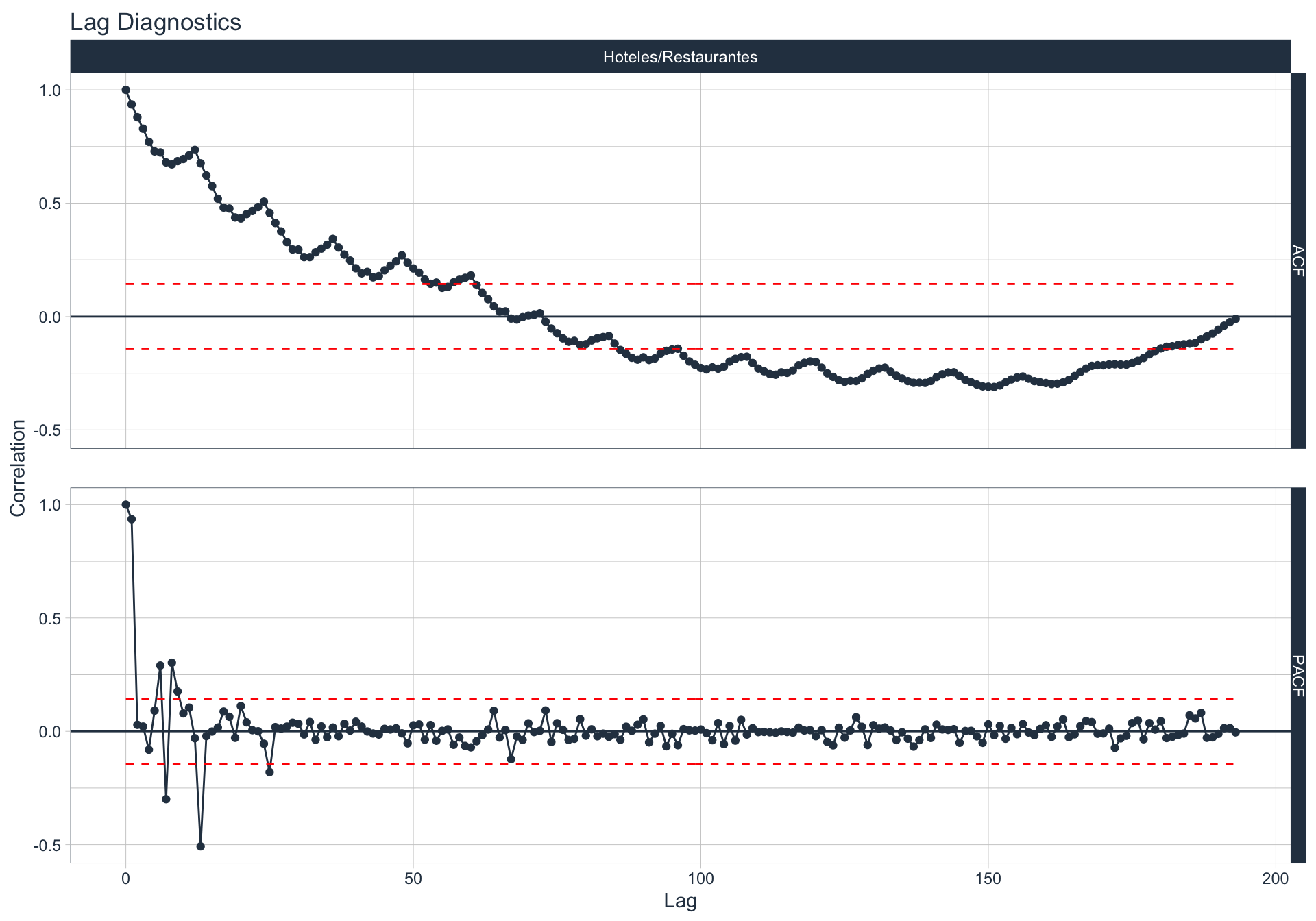
Inmobiliarias
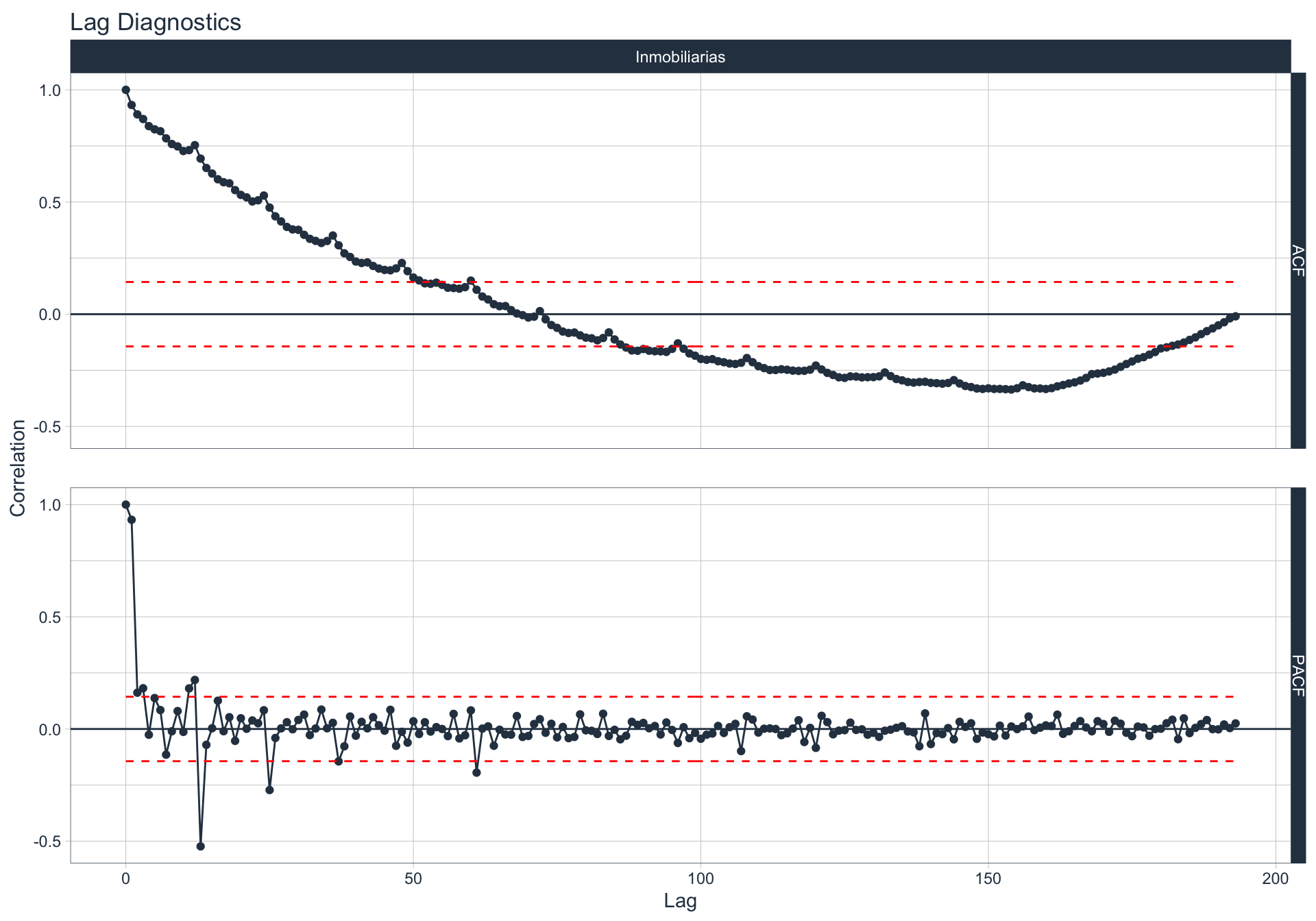
Otras actividades
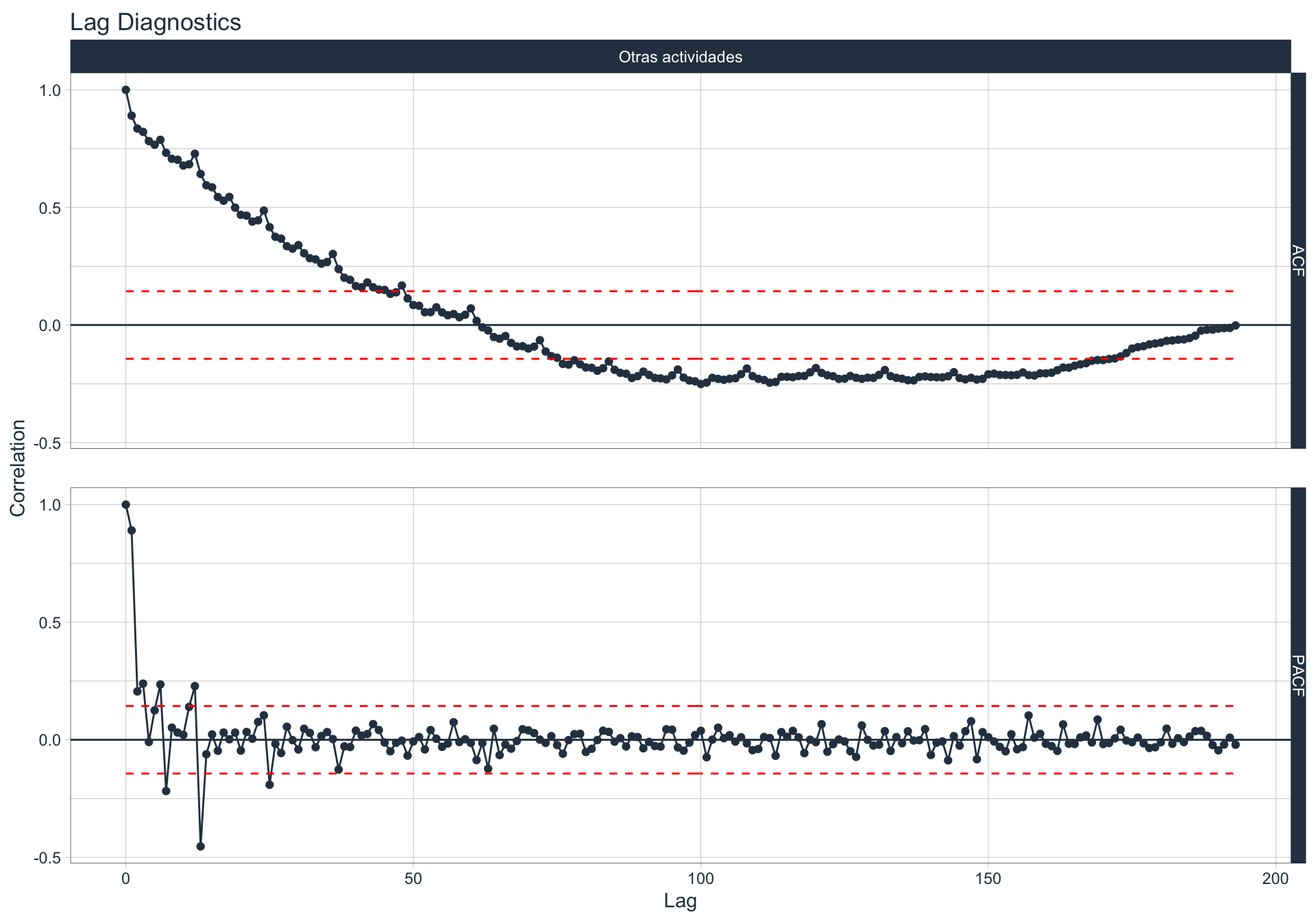
Pesca
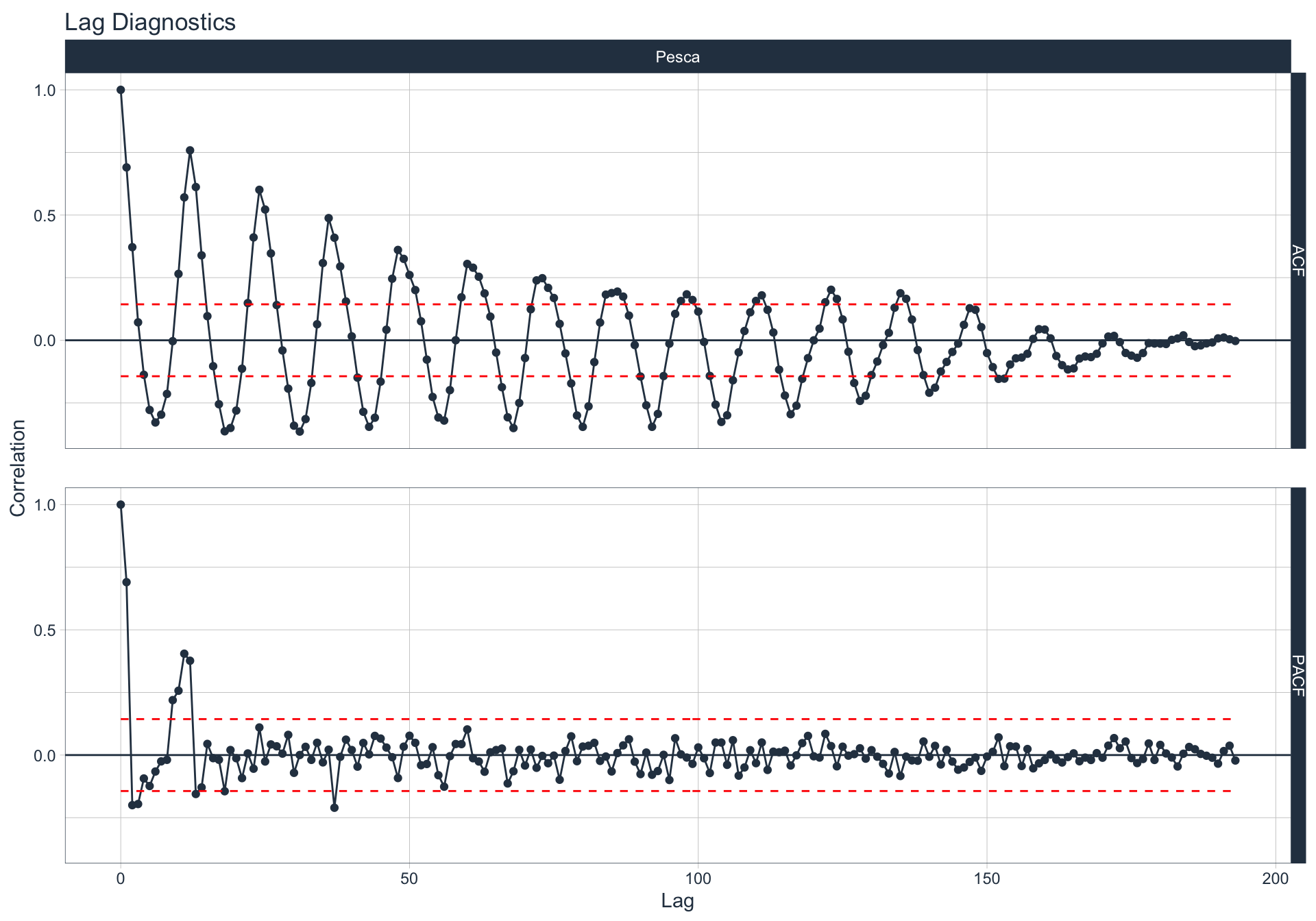
Industria Manufacturera
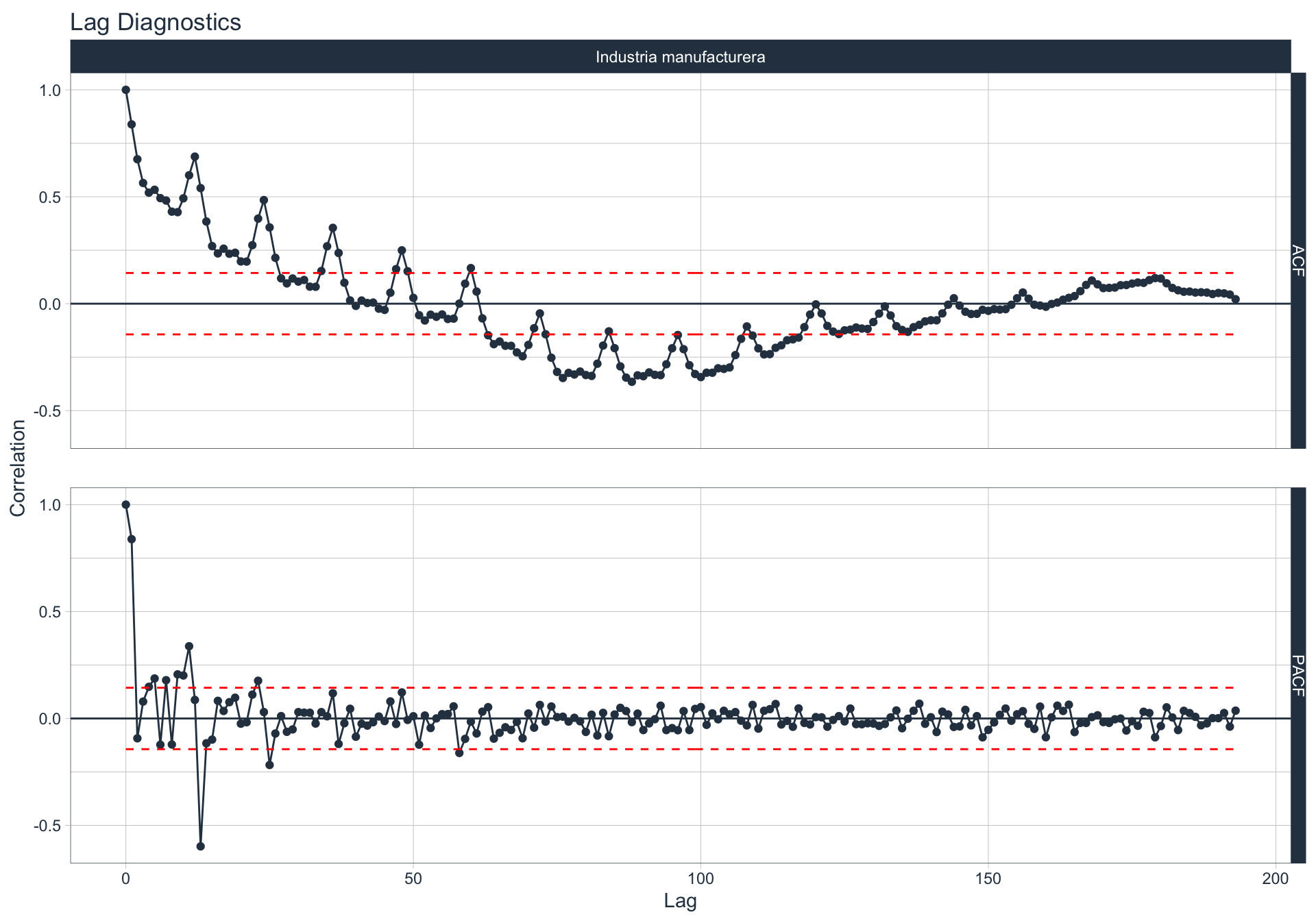
Construcción
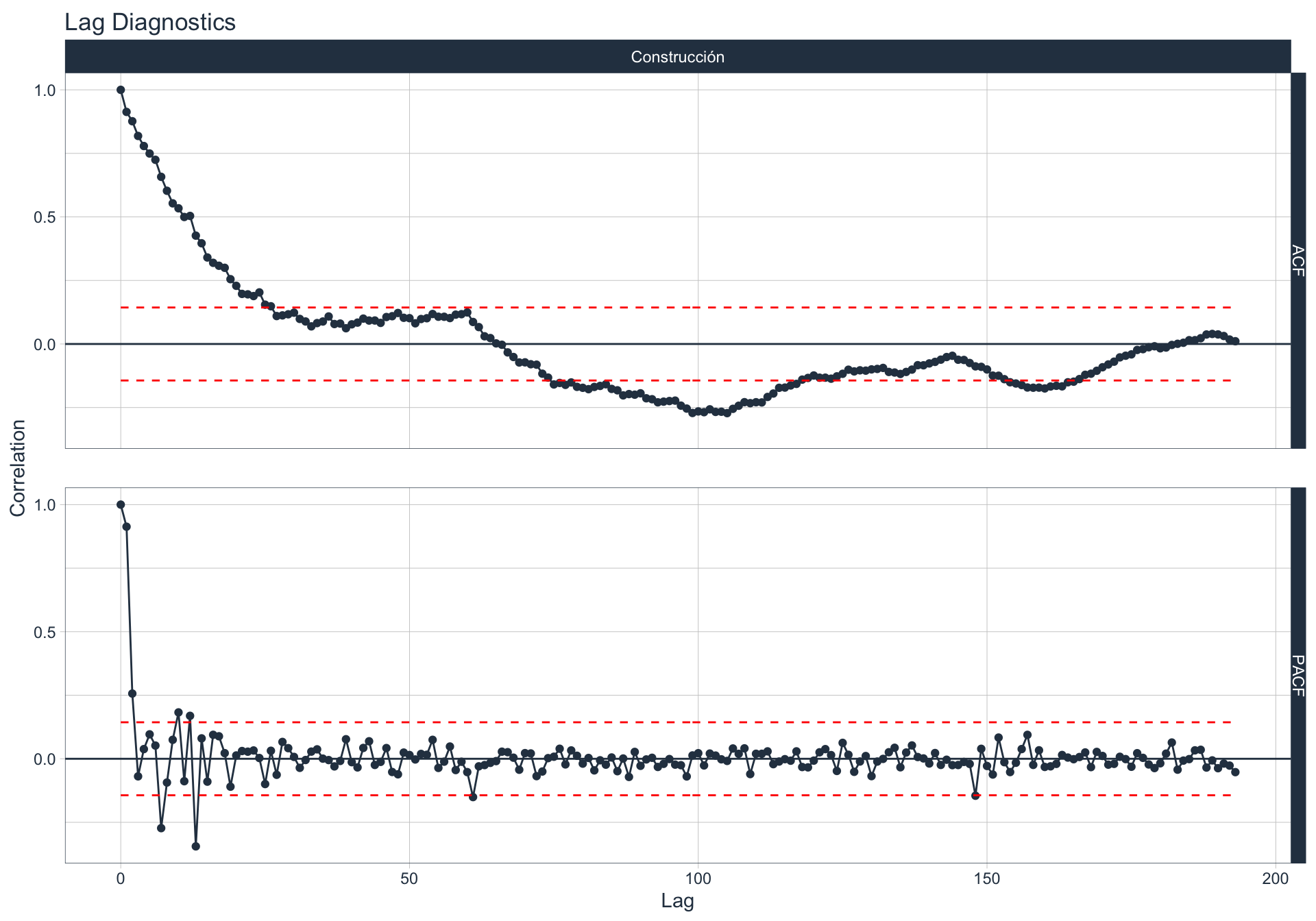
Detección de anomalías 🔍

🔷 El paquete timetk7 permite detectar anomalías en series temporales con 2 pasos:
Removiendo la tendencia y estacionalidad (STL decomposition): las frecuencias para el cálculo de la estacionalidad y la tendencia fueron definidas automáticamente en función del formato de la variable temporal. En este caso, 12 observaciones para la estacionalidad (estacionalidad mensual) y 60 observaciones para la tendencia (5 años).
Detección de anomalías en lo restante
Se define que se muestre un máximo de anomalías del 5% en los datos.
df_emae %>%
group_by(sector) %>%
plot_anomaly_diagnostics(
date,
value,
.facet_ncol = 2,
.max_anomalies = 0.05,
.facet_scales = 'free_y',
.message = TRUE,
.line_size = 0.7,
.anom_size = 1,
.interactive = FALSE
)
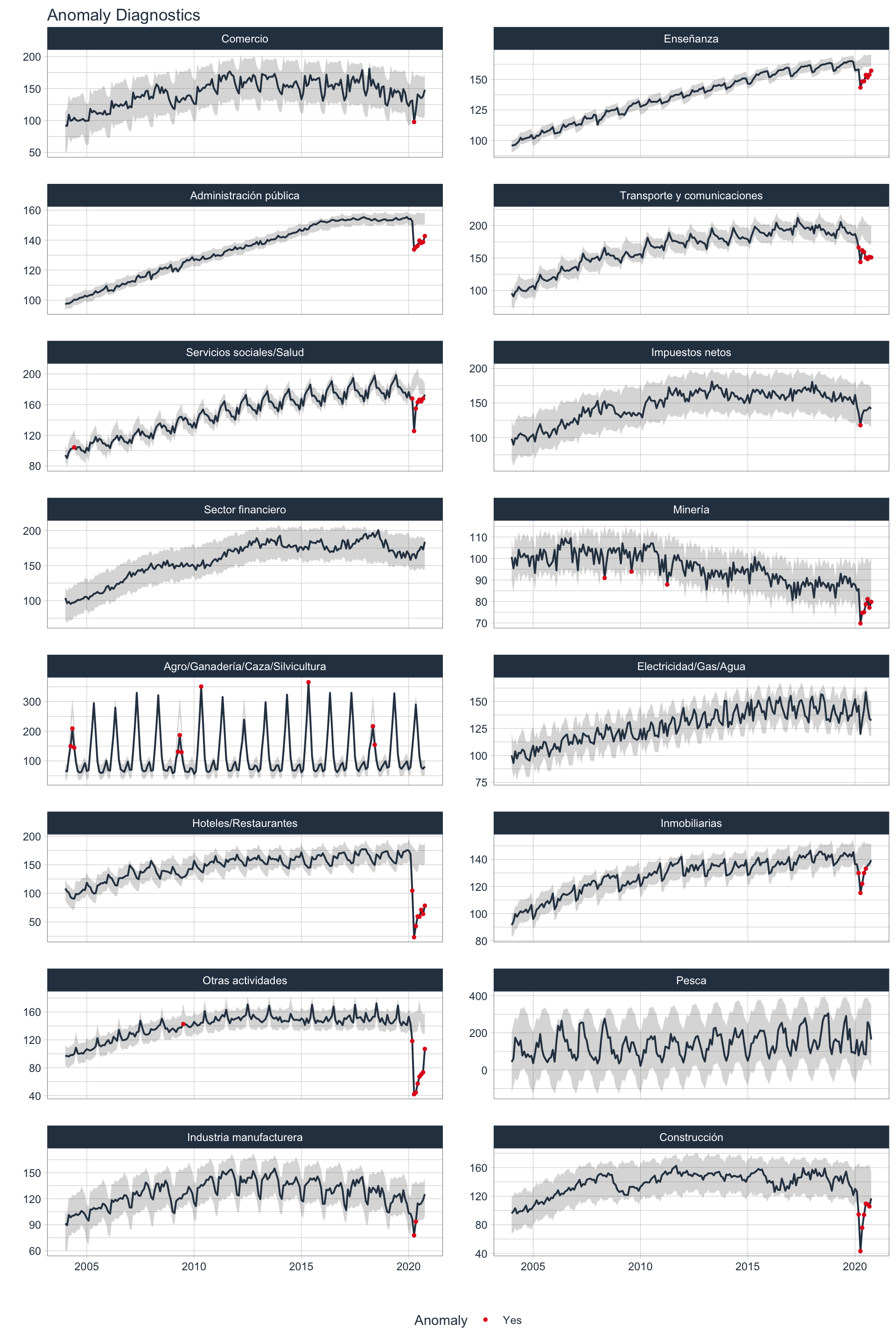
👀 En casi todos los sectores se observa que los meses de pandemia fueron valores atípicos en función de la definición de anomalías definida anteriormente. Un caso especial es el del sector Agro, donde la pandemia pareciera no haber afectado la actividad. En esta serie se observan valores anómalos en años anteriores.
Considerando a la pandemia como un evento que en general modificó el EMAE sectorial, se proyecta cómo hubiera sido el estimador mensual de actividad en cada sector de no haber existido pandemia 🧐.
Modelos 🚀
Para evaluar los modelos en conjunto, se genera una tabla de todos los modelos mediante la función modeltime_multifit() 🤙🏼 del paquete sknifedatar. Esta función permite ajustar múltiples modelos a múltiples series.
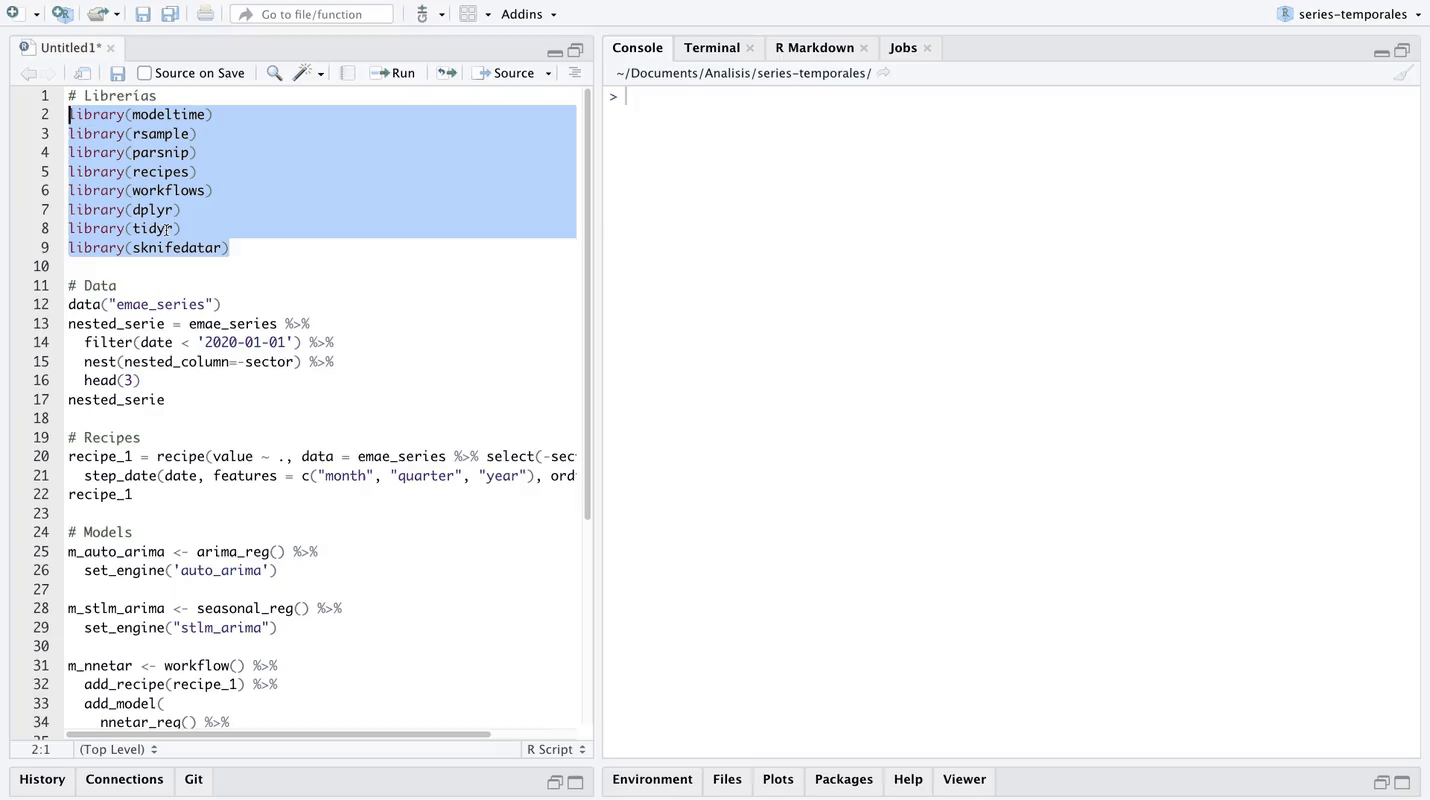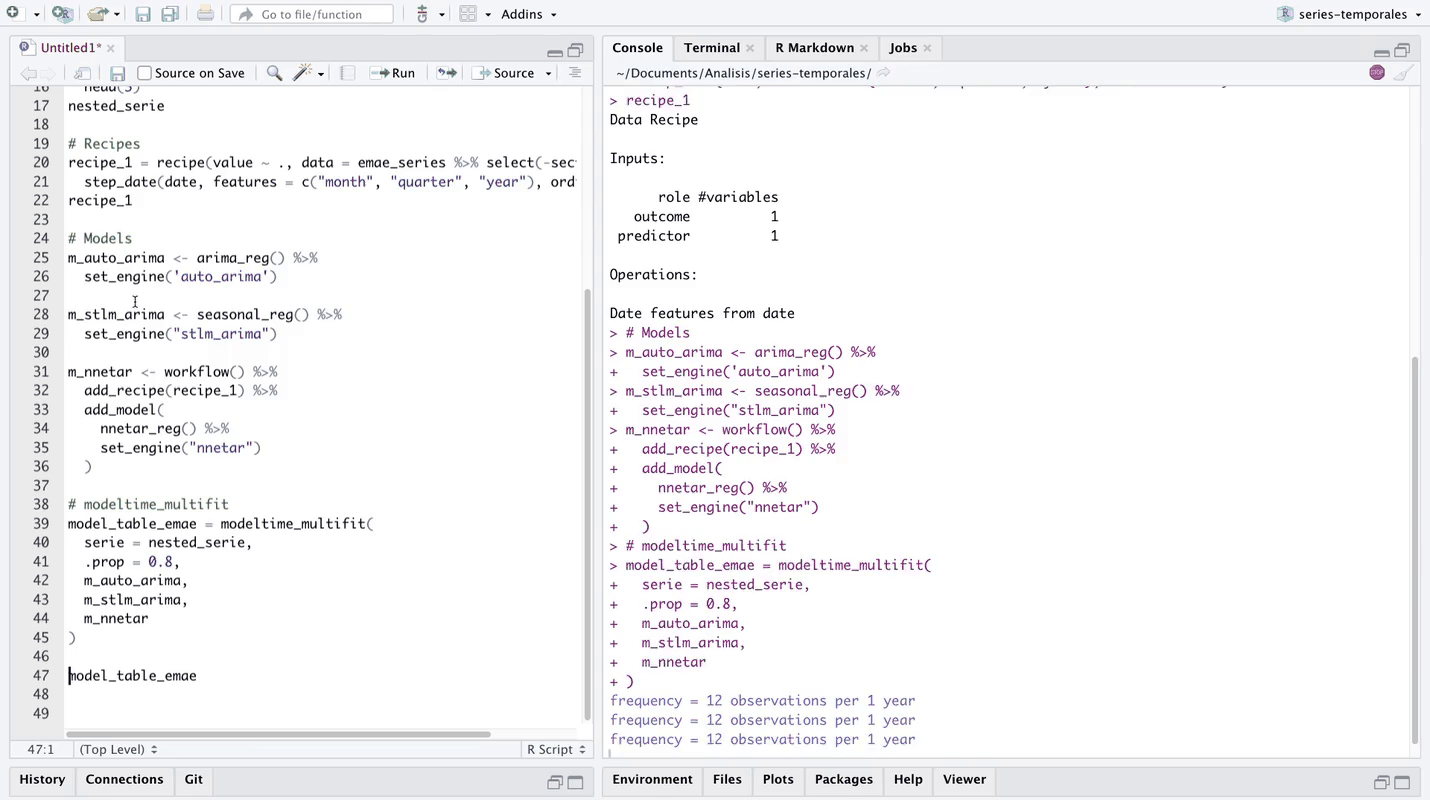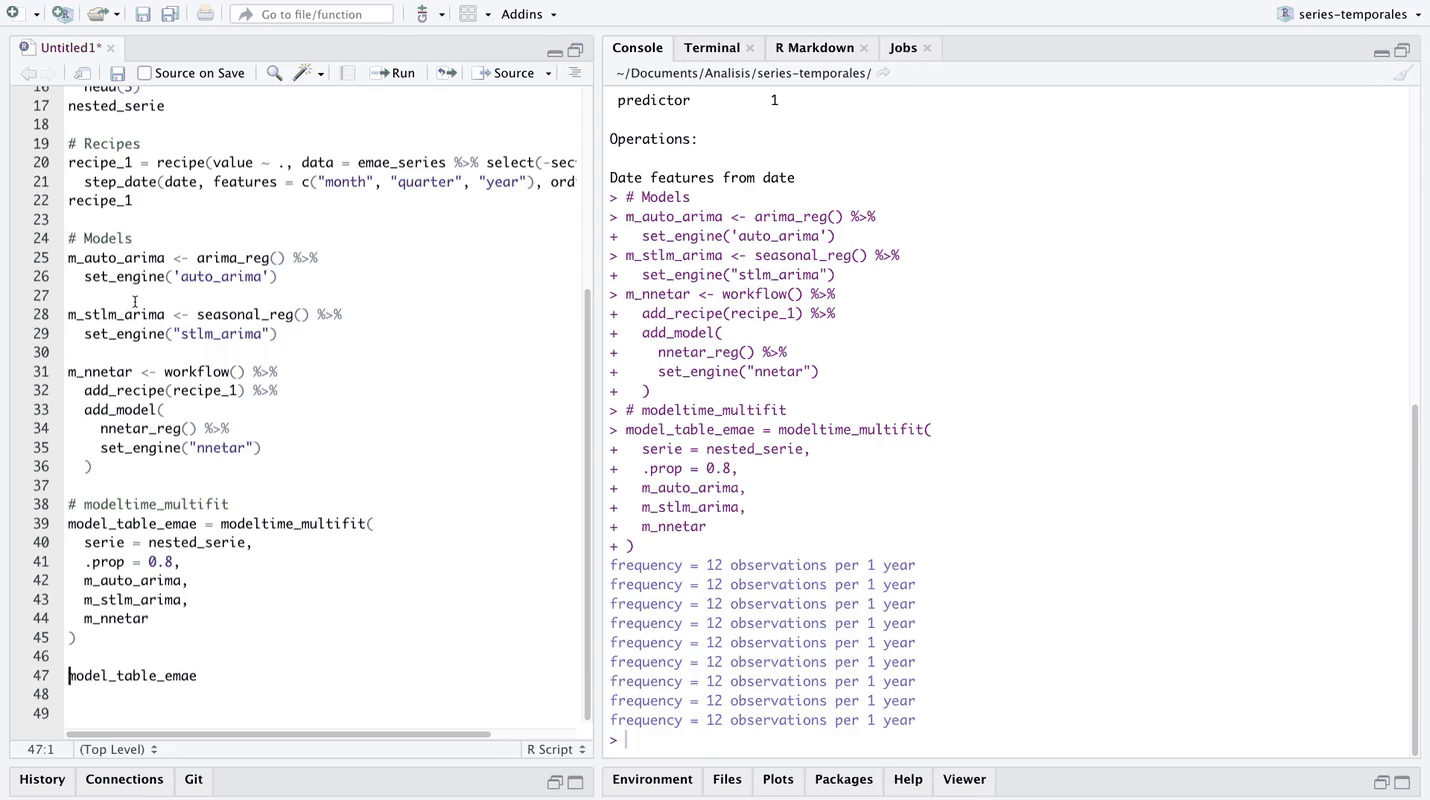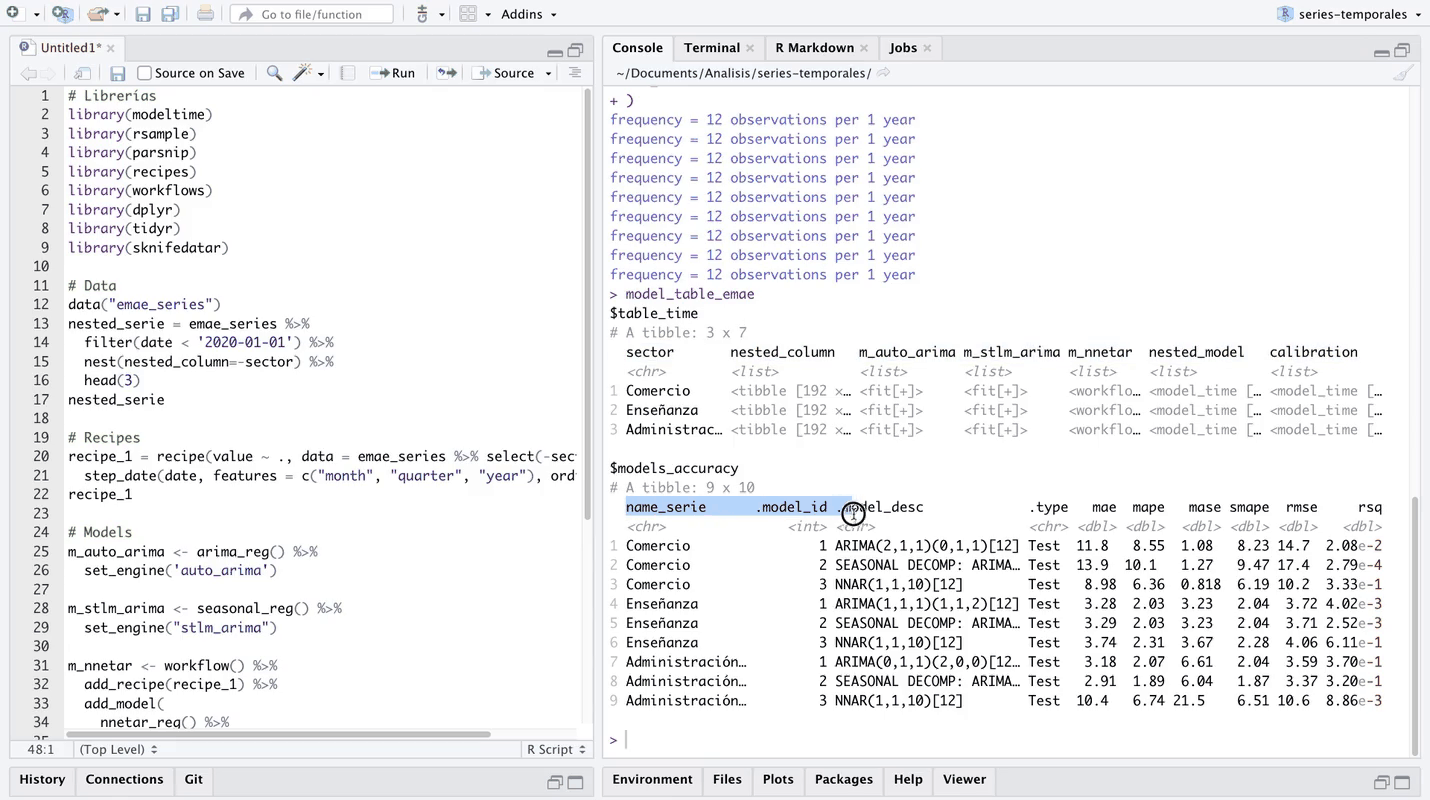
🔹Se considera una partición de las series temporales ➗ en 85% para entrenamiento y los últimos 15% de los datos para test. Tal como en el caso del peaje Avellaneda, la partición se realiza sobre datos previos a la pandemia, en este caso, datos previos a Febrero 2020.
Inicialmente, se define un dataframe anidado que incluye una fila por sector:
df_emae_modelo <- df_emae %>%
filter(date<=FECHA)
nested_df_emae = df_emae_modelo %>%
nest(nested_column=-sector)
Se definen las 🌮 recetas de transformación de variables:
receta_emae_1 = recipe(value ~ ., data = df_emae %>% select(-sector)) %>%
step_date(date, features = c("month", "quarter", "year"), ordinal = TRUE)
receta_emae_2 = receta_emae_1 %>%
step_mutate(date_num = as.numeric(date)) %>%
step_normalize(date_num) %>%
step_rm(date) %>%
step_dummy(date_month)
🔹A continuación se definen los modelos 🚀 en la misma forma que en el caso de Avellaneda, solo que de momento no los entrenamos:
Auto ARIMA
Auto ARIMA Boosted
Seasonal regression
Prophet
Prophet con xgboost
NNETAR
MARS
Elastic Net
Xgboost
Show code
# Modelo Auto-ARIMA
m_arima_emae = arima_reg() %>%
set_engine('auto_arima')
# Modelo ARIMA boosted
m_arima_boosted_emae <- workflow() %>%
add_recipe(receta_emae_1) %>%
add_model(
arima_boost() %>%
set_engine(engine = "auto_arima_xgboost")
)
# Modelo seasonal
m_seasonal_emae <- seasonal_reg() %>%
set_engine("stlm_arima")
# Modelo Prophet
m_prophet_emae <- prophet_reg() %>%
set_engine("prophet")
# Modelo prophet boosted
m_prophet_boost_emae <- workflow() %>%
add_recipe(receta_emae_1) %>%
add_model(
prophet_boost(mode='regression') %>%
set_engine("prophet_xgboost")
)
# Modelo NNetar
m_nnetar_emae <- workflow() %>%
add_recipe(receta_emae_1) %>%
add_model(
nnetar_reg() %>%
set_engine("nnetar")
)
# Modelo MARS
m_mars_emae <- workflow() %>%
add_recipe(receta_emae_2) %>%
add_model(
mars(mode = "regression") %>%
set_engine("earth")
)
# Modelo Elastic net
m_glmnet_emae <- workflow() %>%
add_recipe(receta_emae_2) %>%
add_model(
linear_reg(penalty = 0.01, mixture = 0.1) %>%
set_engine("glmnet")
)
# Modelo Xgboost
m_xgboost_emae <- workflow() %>%
add_recipe(receta_emae_2) %>%
add_model(
boost_tree() %>%
set_engine("xgboost")
)
🔹Se considera una partición de 85% para train y 15% para evaluación.
SPLIT_PROP_EMAE=0.85
🔹 Luego de tener especificados los modelos, se utiliza la función modeltime_multifit() para entrenarlos sobre cada serie. Esta función toma como inputs el dataframe anidado de las series de EMAE sectorial generado anteriormente y la proporción de la partición.
👉🏻 Al final de la función, se pueden incluir tantos modelos como sean necesarios🕺. Los modelos pueden ser workflows o modelos provenientes del paquete parsnip.
model_table_emae <- modeltime_multifit(
serie = nested_df_emae,
.prop = SPLIT_PROP_EMAE,
m_arima_boosted_emae,
m_seasonal_emae,
m_prophet_boost_emae,
m_nnetar_emae,
m_mars_emae,
m_glmnet_emae,
m_xgboost_emae
)
🔹 El output de la función es una lista con dos elementos, se pueden consultar ambos elementos mediante el símbolo “$” luego del nombre de la variable donde fue asignada la función. El primer componente se llama “table_time”, puede consultarse con la siguiente sintaxis:
🔹 Las dos primeras columnas identifican el nombre y los datos de las series, posteriormente se genera automáticamente una columna para cada modelo especificado, donde los modelos ya están entrenados sobre la partición de train de las series 💪. Por ejemplo, podemos consultar el modelo “m_seasonal_emae” ajustado sobre la serie de Comercio":
model_table_emae$table_time$m_seasonal_emae[[1]]
parsnip model object
Fit time: 188ms
SEASONAL DECOMP: ARIMA(3,1,0) with drift
Series: x
ARIMA(3,1,0) with drift
Coefficients:
ar1 ar2 ar3 drift
-0.4520 -0.2547 0.1833 0.3569
s.e. 0.0768 0.0825 0.0770 0.2191
sigma^2 estimated as 18.55: log likelihood=-467.53
AIC=945.06 AICc=945.44 BIC=960.53🔹 Se observan los parámetros del modelo ajustado. A través de la flecha “>” a la derecha del encabezado de la tabla, se puede navegar para consultar el resto de las columnas. La penúltima columna llamada “nested_model” guarda todos los objetos ajustados sobre cada serie, por ejemplo para la serie de Comercio:
model_table_emae$table_time$nested_model[[1]]
# Modeltime Table
# A tibble: 7 x 3
.model_id .model .model_desc
<int> <list> <chr>
1 1 <workflow> ARIMA(3,1,0)(0,1,1)[12] W/ XGBOOST ERRORS
2 2 <fit[+]> SEASONAL DECOMP: ARIMA(3,1,0) WITH DRIFT
3 3 <workflow> PROPHET W/ XGBOOST ERRORS
4 4 <workflow> NNAR(1,1,10)[12]
5 5 <workflow> EARTH
6 6 <workflow> GLMNET
7 7 <workflow> XGBOOST 🔹 El segundo elemento de la salida de la función se llama “models_accuracy”, almacena las métricas de ajuste sobre la partición de test de cada modelo sobre cada series. A continuación se evalúa este elemento.
Evaluación de modelos 🧪
🔹A continuación se muestran las métricas de evaluación correspondientes a cada uno de los modelos entrenados para cada una de las series. Se puede observar que hay ciertos modelos que performan mejor en ciertas series, mientras otros modelos performaron mejor en otras.
Show code
g_metrics_emae <- list()
for (i in 1:length(headers_transporte)){
temp <- model_table_emae$models_accuracy %>%
mutate(rsq = ifelse(is.na(rsq),0,rsq)) %>%
filter(name_serie == headers_transporte[i]) %>%
select(-name_serie)
g_metrics_emae[[i]] <- accuracy_table(
.accuracy = temp,
.subtitle = headers_transporte[i])
}
Transporte
| Evaluación de modelos | |||||||
|---|---|---|---|---|---|---|---|
| Transporte y comunicaciones | |||||||
| Modelo | mae | mape | mase | smape | rmse | rsq | |
| 1 | ARIMA(1,1,0)(0,1,1)[12] W/ XGBOOST ERRORS | 12.07 | 6.35 | 2.48 | 6.09 | 13.94 | 0.19 |
| 2 | SEASONAL DECOMP: ARIMA(2,2,2) | 11.76 | 6.19 | 2.41 | 5.95 | 13.35 | 0.18 |
| 3 | PROPHET W/ XGBOOST ERRORS | 14.83 | 7.81 | 3.04 | 7.44 | 16.59 | 0.09 |
| 4 | NNAR(1,1,10)[12] | 12.40 | 6.54 | 2.54 | 6.27 | 14.15 | 0.11 |
| 5 | EARTH | 10.78 | 5.69 | 2.21 | 5.48 | 12.29 | 0.16 |
| 6 | GLMNET | 24.01 | 12.61 | 4.93 | 11.78 | 25.34 | 0.04 |
| 7 | XGBOOST | 4.70 | 2.48 | 0.96 | 2.45 | 5.34 | 0.53 |
Comercio
| Evaluación de modelos | |||||||
|---|---|---|---|---|---|---|---|
| Comercio | |||||||
| Modelo | mae | mape | mase | smape | rmse | rsq | |
| 1 | ARIMA(3,1,0)(0,1,1)[12] W/ XGBOOST ERRORS | 16.93 | 12.06 | 1.36 | 11.11 | 20.11 | 0.33 |
| 2 | SEASONAL DECOMP: ARIMA(3,1,0) WITH DRIFT | 19.57 | 14.01 | 1.58 | 12.80 | 22.63 | 0.16 |
| 3 | PROPHET W/ XGBOOST ERRORS | 11.86 | 8.31 | 0.96 | 7.92 | 14.00 | 0.40 |
| 4 | NNAR(1,1,10)[12] | 10.68 | 7.42 | 0.86 | 7.20 | 12.58 | 0.37 |
| 5 | EARTH | 21.68 | 15.56 | 1.75 | 14.06 | 25.21 | 0.05 |
| 6 | GLMNET | 29.07 | 20.79 | 2.34 | 18.39 | 32.08 | 0.13 |
| 7 | XGBOOST | 12.35 | 8.72 | 0.99 | 8.29 | 14.25 | 0.42 |
Enseñanza
| Evaluación de modelos | |||||||
|---|---|---|---|---|---|---|---|
| Enseñanza | |||||||
| Modelo | mae | mape | mase | smape | rmse | rsq | |
| 1 | ARIMA(1,1,1)(0,1,1)[12] W/ XGBOOST ERRORS | 3.12 | 1.93 | 2.42 | 1.91 | 3.73 | 0.69 |
| 2 | SEASONAL DECOMP: ARIMA(1,1,1) WITH DRIFT | 4.27 | 2.65 | 3.32 | 2.60 | 4.99 | 0.53 |
| 3 | PROPHET W/ XGBOOST ERRORS | 2.56 | 1.58 | 1.99 | 1.56 | 3.18 | 0.72 |
| 4 | NNAR(1,1,10)[12] | 1.81 | 1.12 | 1.40 | 1.11 | 2.11 | 0.88 |
| 5 | EARTH | 4.51 | 2.80 | 3.50 | 2.75 | 5.02 | 0.58 |
| 6 | GLMNET | 6.43 | 3.99 | 4.99 | 3.90 | 6.92 | 0.52 |
| 7 | XGBOOST | 5.36 | 3.32 | 4.16 | 3.38 | 5.48 | 0.82 |
Admin públic
| Evaluación de modelos | |||||||
|---|---|---|---|---|---|---|---|
| Administración pública | |||||||
| Modelo | mae | mape | mase | smape | rmse | rsq | |
| 1 | ARIMA(0,1,1)(2,0,0)[12] WITH DRIFT W/ XGBOOST ERRORS | 2.88 | 1.87 | 5.65 | 1.85 | 3.27 | 0.03 |
| 2 | SEASONAL DECOMP: ARIMA(0,1,1) WITH DRIFT | 5.13 | 3.33 | 10.07 | 3.26 | 5.94 | 0.03 |
| 3 | PROPHET W/ XGBOOST ERRORS | 5.51 | 3.58 | 10.81 | 3.50 | 6.07 | 0.03 |
| 4 | NNAR(1,1,10)[12] | 4.11 | 2.67 | 8.08 | 2.63 | 4.34 | 0.03 |
| 5 | EARTH | 6.31 | 4.10 | 12.38 | 4.00 | 6.79 | 0.03 |
| 6 | GLMNET | 9.11 | 5.92 | 17.88 | 5.73 | 9.62 | 0.03 |
| 7 | XGBOOST | 1.70 | 1.11 | 3.35 | 1.11 | 1.84 | 0.00 |
Impuestos netos
| Evaluación de modelos | |||||||
|---|---|---|---|---|---|---|---|
| Impuestos netos | |||||||
| Modelo | mae | mape | mase | smape | rmse | rsq | |
| 1 | ARIMA(2,1,0)(1,0,0)[12] W/ XGBOOST ERRORS | 14.28 | 9.10 | 2.07 | 8.59 | 16.45 | 0.01 |
| 2 | SEASONAL DECOMP: ARIMA(0,1,2) WITH DRIFT | 14.30 | 9.10 | 2.08 | 8.61 | 16.24 | 0.07 |
| 3 | PROPHET W/ XGBOOST ERRORS | 7.32 | 4.60 | 1.06 | 4.52 | 8.21 | 0.16 |
| 4 | NNAR(1,1,10)[12] | 6.36 | 4.00 | 0.92 | 3.94 | 7.92 | 0.16 |
| 5 | EARTH | 8.67 | 5.44 | 1.26 | 5.34 | 9.48 | 0.04 |
| 6 | GLMNET | 23.49 | 14.93 | 3.41 | 13.68 | 25.84 | 0.10 |
| 7 | XGBOOST | 6.47 | 4.03 | 0.94 | 4.01 | 7.57 | 0.16 |
Sect financiero
| Evaluación de modelos | |||||||
|---|---|---|---|---|---|---|---|
| Sector financiero | |||||||
| Modelo | mae | mape | mase | smape | rmse | rsq | |
| 1 | ARIMA(2,1,0)(2,0,0)[12] W/ XGBOOST ERRORS | 15.10 | 8.83 | 2.69 | 8.30 | 18.76 | 0.04 |
| 2 | SEASONAL DECOMP: ARIMA(0,1,1) WITH DRIFT | 16.43 | 9.65 | 2.93 | 8.98 | 20.65 | 0.41 |
| 3 | PROPHET W/ XGBOOST ERRORS | 10.64 | 6.00 | 1.90 | 5.94 | 12.21 | 0.06 |
| 4 | NNAR(1,1,10)[12] | 12.12 | 6.71 | 2.16 | 6.80 | 14.29 | 0.00 |
| 5 | EARTH | 17.50 | 10.29 | 3.12 | 9.52 | 22.17 | 0.51 |
| 6 | GLMNET | 25.39 | 14.84 | 4.53 | 13.39 | 30.27 | 0.48 |
| 7 | XGBOOST | 11.40 | 6.37 | 2.03 | 6.37 | 12.48 | 0.03 |
Minería
| Evaluación de modelos | |||||||
|---|---|---|---|---|---|---|---|
| Minería | |||||||
| Modelo | mae | mape | mase | smape | rmse | rsq | |
| 1 | ARIMA(0,1,1)(2,0,0)[12] W/ XGBOOST ERRORS | 5.45 | 6.18 | 1.70 | 6.42 | 5.94 | 0.44 |
| 2 | SEASONAL DECOMP: ARIMA(0,1,1) | 2.00 | 2.27 | 0.63 | 2.30 | 2.38 | 0.73 |
| 3 | PROPHET W/ XGBOOST ERRORS | 5.19 | 5.89 | 1.62 | 6.10 | 5.68 | 0.48 |
| 4 | NNAR(1,1,10)[12] | 4.78 | 5.45 | 1.49 | 5.32 | 5.59 | 0.06 |
| 5 | EARTH | 8.07 | 9.16 | 2.52 | 9.68 | 8.78 | 0.23 |
| 6 | GLMNET | 1.61 | 1.84 | 0.50 | 1.82 | 1.91 | 0.59 |
| 7 | XGBOOST | 2.36 | 2.67 | 0.74 | 2.73 | 2.89 | 0.59 |
Agro/Ganadería/Caza/Silvicultura
| Evaluación de modelos | |||||||
|---|---|---|---|---|---|---|---|
| Agro/Ganadería/Caza/Silvicultura | |||||||
| Modelo | mae | mape | mase | smape | rmse | rsq | |
| 1 | ARIMA(1,0,2)(0,1,1)[12] WITH DRIFT W/ XGBOOST ERRORS | 12.08 | 8.67 | 0.36 | 7.75 | 26.58 | 0.89 |
| 2 | SEASONAL DECOMP: ARIMA(1,1,3) | 12.89 | 9.52 | 0.38 | 9.01 | 24.14 | 0.89 |
| 3 | PROPHET W/ XGBOOST ERRORS | 15.54 | 10.83 | 0.46 | 9.99 | 31.62 | 0.89 |
| 4 | NNAR(1,1,10)[12] | 16.59 | 11.20 | 0.49 | 9.92 | 35.04 | 0.89 |
| 5 | EARTH | 19.90 | 18.81 | 0.59 | 16.70 | 28.63 | 0.90 |
| 6 | GLMNET | 12.53 | 9.33 | 0.37 | 8.56 | 23.07 | 0.90 |
| 7 | XGBOOST | 13.38 | 10.22 | 0.40 | 9.63 | 26.75 | 0.89 |
Elec/Gas/Agua
| Evaluación de modelos | |||||||
|---|---|---|---|---|---|---|---|
| Electricidad/Gas/Agua | |||||||
| Modelo | mae | mape | mase | smape | rmse | rsq | |
| 1 | ARIMA(1,0,2)(0,1,1)[12] WITH DRIFT W/ XGBOOST ERRORS | 8.09 | 5.80 | 1.16 | 5.57 | 9.83 | 0.47 |
| 2 | SEASONAL DECOMP: ARIMA(2,1,1) WITH DRIFT | 7.79 | 5.61 | 1.12 | 5.41 | 9.13 | 0.51 |
| 3 | PROPHET W/ XGBOOST ERRORS | 6.98 | 5.00 | 1.00 | 4.84 | 8.15 | 0.56 |
| 4 | NNAR(1,1,10)[12] | 6.93 | 4.98 | 0.99 | 4.81 | 8.25 | 0.58 |
| 5 | EARTH | 4.61 | 3.18 | 0.66 | 3.25 | 5.83 | 0.65 |
| 6 | GLMNET | 11.68 | 8.42 | 1.67 | 8.01 | 12.92 | 0.45 |
| 7 | XGBOOST | 3.85 | 2.72 | 0.55 | 2.71 | 4.50 | 0.68 |
Hoteles/Rest
| Evaluación de modelos | |||||||
|---|---|---|---|---|---|---|---|
| Hoteles/Restaurantes | |||||||
| Modelo | mae | mape | mase | smape | rmse | rsq | |
| 1 | ARIMA(0,1,0)(0,1,1)[12] W/ XGBOOST ERRORS | 6.64 | 4.01 | 1.25 | 3.91 | 7.41 | 0.69 |
| 2 | SEASONAL DECOMP: ARIMA(0,1,0) WITH DRIFT | 9.43 | 5.72 | 1.78 | 5.52 | 10.52 | 0.54 |
| 3 | PROPHET W/ XGBOOST ERRORS | 3.75 | 2.26 | 0.71 | 2.24 | 4.35 | 0.77 |
| 4 | NNAR(1,1,10)[12] | 2.37 | 1.41 | 0.45 | 1.41 | 2.78 | 0.88 |
| 5 | EARTH | 4.83 | 2.93 | 0.91 | 2.88 | 5.57 | 0.71 |
| 6 | GLMNET | 12.59 | 7.64 | 2.37 | 7.31 | 13.71 | 0.55 |
| 7 | XGBOOST | 4.58 | 2.68 | 0.86 | 2.74 | 5.72 | 0.79 |
Inmobiliarias
| Evaluación de modelos | |||||||
|---|---|---|---|---|---|---|---|
| Inmobiliarias | |||||||
| Modelo | mae | mape | mase | smape | rmse | rsq | |
| 1 | ARIMA(2,1,1)(0,1,1)[12] W/ XGBOOST ERRORS | 3.32 | 2.35 | 1.31 | 2.31 | 4.07 | 0.43 |
| 2 | SEASONAL DECOMP: ARIMA(2,1,1) WITH DRIFT | 3.70 | 2.62 | 1.46 | 2.57 | 4.46 | 0.39 |
| 3 | PROPHET W/ XGBOOST ERRORS | 2.09 | 1.47 | 0.83 | 1.47 | 2.67 | 0.57 |
| 4 | NNAR(1,1,10)[12] | 3.26 | 2.29 | 1.29 | 2.32 | 3.67 | 0.53 |
| 5 | EARTH | 4.51 | 3.20 | 1.78 | 3.13 | 5.46 | 0.27 |
| 6 | GLMNET | 5.93 | 4.19 | 2.35 | 4.09 | 6.65 | 0.41 |
| 7 | XGBOOST | 4.29 | 3.02 | 1.70 | 3.07 | 4.64 | 0.68 |
Otras actividades
| Evaluación de modelos | |||||||
|---|---|---|---|---|---|---|---|
| Otras actividades | |||||||
| Modelo | mae | mape | mase | smape | rmse | rsq | |
| 1 | ARIMA(0,1,2)(0,1,1)[12] W/ XGBOOST ERRORS | 4.61 | 3.11 | 0.62 | 3.08 | 5.57 | 0.53 |
| 2 | SEASONAL DECOMP: ARIMA(0,1,1) WITH DRIFT | 6.89 | 4.71 | 0.92 | 4.55 | 8.48 | 0.32 |
| 3 | PROPHET W/ XGBOOST ERRORS | 4.58 | 3.11 | 0.61 | 3.07 | 5.28 | 0.55 |
| 4 | NNAR(1,1,10)[12] | 4.59 | 3.09 | 0.62 | 3.08 | 5.78 | 0.48 |
| 5 | EARTH | 4.17 | 2.80 | 0.56 | 2.78 | 4.78 | 0.65 |
| 6 | GLMNET | 17.59 | 11.94 | 2.36 | 11.18 | 18.66 | 0.29 |
| 7 | XGBOOST | 4.42 | 2.95 | 0.59 | 2.95 | 4.97 | 0.55 |
Pesca
| Evaluación de modelos | |||||||
|---|---|---|---|---|---|---|---|
| Pesca | |||||||
| Modelo | mae | mape | mase | smape | rmse | rsq | |
| 1 | ARIMA(1,0,2)(0,1,1)[12] WITH DRIFT W/ XGBOOST ERRORS | 37.11 | 24.93 | 0.73 | 22.91 | 44.25 | 0.62 |
| 2 | SEASONAL DECOMP: ARIMA(1,1,1) | 40.84 | 24.73 | 0.80 | 25.04 | 48.77 | 0.56 |
| 3 | PROPHET W/ XGBOOST ERRORS | 33.27 | 22.48 | 0.65 | 20.49 | 41.85 | 0.65 |
| 4 | NNAR(1,1,10)[12] | 52.31 | 37.98 | 1.03 | 30.14 | 61.19 | 0.39 |
| 5 | EARTH | 49.68 | 33.92 | 0.98 | 29.63 | 57.20 | 0.34 |
| 6 | GLMNET | 52.46 | 30.76 | 1.03 | 30.58 | 63.81 | 0.24 |
| 7 | XGBOOST | 32.97 | 19.53 | 0.65 | 20.15 | 42.56 | 0.67 |
Industria Manufacturera
| Evaluación de modelos | |||||||
|---|---|---|---|---|---|---|---|
| Industria manufacturera | |||||||
| Modelo | mae | mape | mase | smape | rmse | rsq | |
| 1 | ARIMA(0,1,1)(0,1,1)[12] W/ XGBOOST ERRORS | 13.24 | 11.08 | 1.82 | 10.25 | 15.98 | 0.45 |
| 2 | SEASONAL DECOMP: ARIMA(0,1,1) | 12.47 | 10.51 | 1.72 | 9.82 | 14.28 | 0.58 |
| 3 | PROPHET W/ XGBOOST ERRORS | 6.60 | 5.44 | 0.91 | 5.25 | 8.30 | 0.66 |
| 4 | NNAR(1,1,10)[12] | 6.73 | 5.61 | 0.93 | 5.47 | 8.31 | 0.56 |
| 5 | EARTH | 5.02 | 4.11 | 0.69 | 4.05 | 6.03 | 0.73 |
| 6 | GLMNET | 23.61 | 19.82 | 3.25 | 17.77 | 25.19 | 0.39 |
| 7 | XGBOOST | 9.26 | 7.68 | 1.27 | 7.32 | 11.35 | 0.47 |
Construcción
| Evaluación de modelos | |||||||
|---|---|---|---|---|---|---|---|
| Construcción | |||||||
| Modelo | mae | mape | mase | smape | rmse | rsq | |
| 1 | ARIMA(3,1,0)(2,0,0)[12] WITH DRIFT W/ XGBOOST ERRORS | 19.40 | 14.06 | 2.72 | 12.67 | 24.02 | 0.07 |
| 2 | SEASONAL DECOMP: ARIMA(0,1,3) | 11.48 | 8.36 | 1.61 | 7.84 | 14.05 | 0.30 |
| 3 | PROPHET W/ XGBOOST ERRORS | 6.88 | 4.79 | 0.96 | 4.85 | 8.02 | 0.38 |
| 4 | NNAR(1,1,10)[12] | 9.64 | 6.61 | 1.35 | 6.84 | 11.34 | 0.17 |
| 5 | EARTH | 33.01 | 23.86 | 4.62 | 20.28 | 39.75 | 0.34 |
| 6 | GLMNET | 14.95 | 10.85 | 2.09 | 10.03 | 17.93 | 0.00 |
| 7 | XGBOOST | 6.72 | 4.74 | 0.94 | 4.73 | 8.18 | 0.27 |
⚠ Notar que en la mayoría de los modelos ARIMA, el término de integración es 1. Esto se debe a que la mayoría de las series no son estacionarias. En el caso de 🌱 Agro, el término de integración es 0 y esto se debe a que es una serie estacionaria con lo cual no se requiere ningún tipo de transformación para convertirla en estacionaria.
🔹 Para las proyecciones se utiliza la función ✨modeltime_multiforecast ✨, también incluida en el paquete sknifedatar. Esta función permite tomar los múltiples modelos ajustados y realizar un forecast sobre las particiones de test de cada serie.
forecast_emae <- modeltime_multiforecast(
model_table_emae$table_time,
.prop = SPLIT_PROP_EMAE
)
Visualmente 🔭 se observa lo mismo que en las métricas , ciertos modelos ajustan mejor a ciertas series.
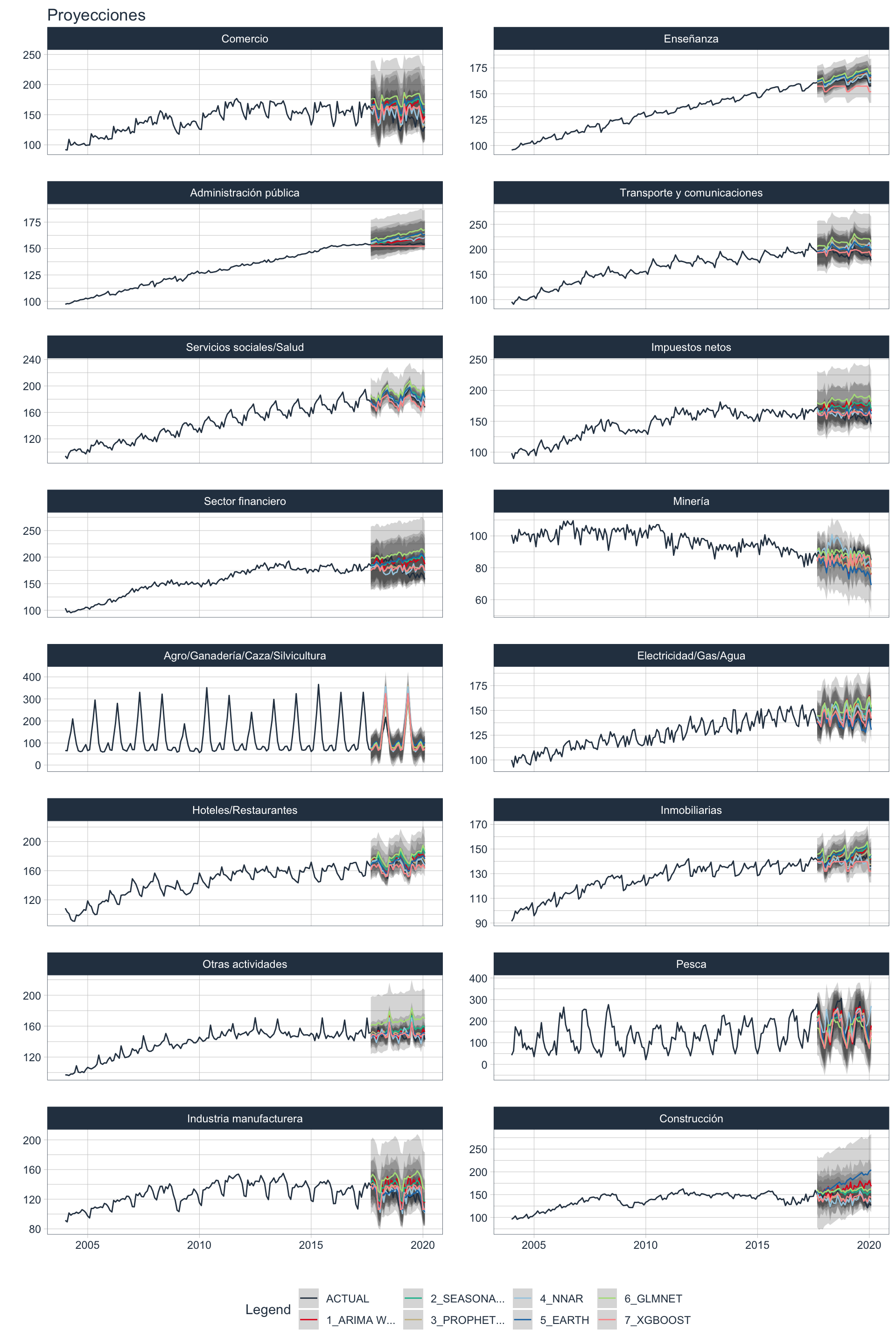
Selección del mejor modelo 🥇
🔹Se selecciona el mejor modelo en función de una de las métricas 🏆 (en este caso se considera el error cuadrático medio, o rmse). Para ello, se utiliza la función modeltime_multibestmodel(),incluida en el paquete sknifedatar.
best_model_emae <- modeltime_multibestmodel(
.table = model_table_emae$table_time,
.metric = rmse,
.optimization = which.min
)
🔹 Mediante la función modeltime_multirefit(), de sknifedatar se entrena el mejor modelo para cada serie, utilizando todos los datos disponibles pre-pandemia.
model_refit_emae <- modeltime_multirefit(best_model_emae)
Se unen los datos de la tabla original:
📝 Se realiza el forecast considerando los modelos luego del refit. En este caso, en vez de utilizar la función modeltime_multiforecast() se utiliza una función modificada, debido a que se busca predecir a partir de determinada fecha y comparar la predicción contra el valor observado durante la pandemia 😷 . Este es un caso muy particular y por ello se decidió no incluirlo en el pquete.
Show code
modeltime_multiforecast_pandemia = function(models_table,
.fecha = '2020-02-01',
.prop = 0.7) {
models_table %>% mutate(
nested_forecast = pmap(list(calibration, nested_column, actual_data),
function(calibration, nested_column, actual_data) {
calibration %>% modeltime_forecast(
new_data = actual_data %>% filter(date >= .fecha),
actual_data = actual_data
) %>%
mutate(
.model_details = .model_desc,
.model_desc = str_replace_all(.model_desc, "[[:punct:][:digit:][:cntrl:]]", "")
) %>%
mutate(.model_desc = ifelse(str_detect(.model_desc, "ARIMA"), "ARIMA", .model_desc))
}))
}
🔹Aplicando esta función se obtienen las proyecciones durante la pandemia 🧙♂️
forecast_best_emae <- modeltime_multiforecast_pandemia(model_refit_emae,
.fecha = FECHA,
.prop = SPLIT_PROP_EMAE)
🔹 Se visualiza la predicción durante el período de pandemia contra los valores reales. Puede observarse como muchas actividades sufrieron de una caída considerable en relación a lo que se esperaría, mientras que otras actividades como el Agro no se vieron afectadas.
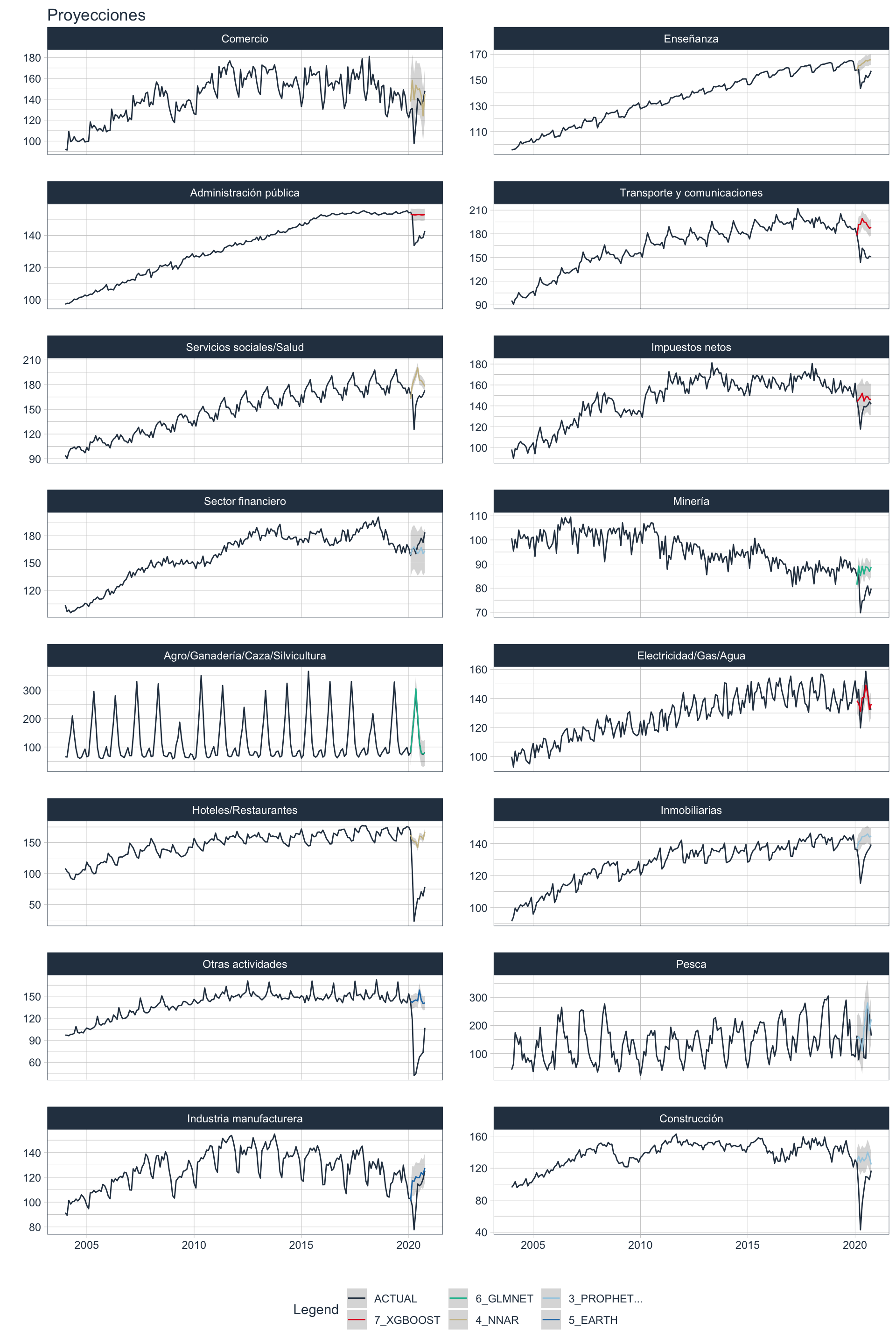
Comentarios finales 📝
👉Tradicionalmente, el modelado de series de tiempo en lenguajes de programación como R o python, lleva consigo cientos o miles de líneas de código (for, while, for, while, … 😭🚫😨).
🔹La filosofía de datos ordenados en R, materializada a través del ecosistema de paquetes tidy (tidyverse, tidymodels, modeltime), permite manipular y modelar con datos de manera prolija y simple.
📌En este post ajustamos múltiples modelos sobre múltiples series de tiempo. También se hizo un análisis exploratorio previo (descomposición, estacionalidad, autocorrelación, detección de anomalías). Todo esto se logró en formato sencillo y metódico, lo que permite colocar el foco en el análisis y no en el código en sí. Este post forma parte de una serie de artículos enfocados en el modelado de series de tiempo, siguiendo el enfoque de datos ordenados (tidy) del lenguaje R.
Los próximos artículos 💡 que estamos considerando son los siguientes:
Ensambles de modelos 🧶.
Ajuste de hiperparametros ⏳ (cross validation de seriess temporales)
Esperamos que haya sido de utilidad, gracias por leernos 👏👏👏.
Contatos ✉
Karina Bartolome, Linkedin, Twitter, Github, Blogpost.
Rafael Zambrano, Linkedin, Twitter, Github, Blogpost.
Hasta 2019 el tipo de vehículo fue Livianos o Pesados. Sin embargo, a partir de 2020 hubo un cambio en la metodología y se comenzó a informar a nivel más desagregado, también incorporando una categoría N/D o No disponible. Decidimos omitir la categoría NA y clasificar el resto entre Livianos y Pesados, aunque podría existir alguna consideración metodológica que no estemos considerando.↩︎
Applied Time Series Analysis for Fisheries and Environmental Sciences↩︎