Introducción
En un post anterior (Uso del subte en la Ciudad Autónoma de Buenos Aires) se muestra cómo utilizar el paquete {gt}📦1 para realizar tablas basadas en the Grammar of Graphics. Se recomienda revisar el post anterior antes de leer este.
En este caso, se mostrarán algunas funcionalidades de {pandas}📦2 que permiten generar un formato de tabla muy similar al obtenido en el post sobre {gt} pero en este caso utilizando python.
Conda environment 🐍
⚙️ Se utiliza un environment específico para este proyecto, con python 3.9:
Show code
reticulate::conda_create(envname='tabla-subtes', python_version="3.9")Se instalan los paquetes python 📦
Show code
reticulate::conda_install(envname = 'tabla-subtes',
packages='geopandas', channel='conda-forge')
reticulate::conda_install(envname = 'tabla-subtes',
packages='plotnine', channel='conda-forge')
reticulate::conda_install(envname = 'tabla-subtes',
packages='seaborn', channel='conda-forge')
reticulate::conda_install(envname = 'tabla-subtes',
packages='IPython', channel='conda-forge')Con el environment creado y activado, se define que se va a utilizar ese environment:
Show code
reticulate::use_condaenv(condaenv = 'tabla-subtes', required = TRUE)Para utilizar python en rmarkdown, es necesario definir que se va a utilizar un chunk de código python. Para más información sobre python en rmarkdown, ver: El uso de múltiples lenguajes en Rmarkdown.
1️⃣ Librerías
Se importan las librerías python a utilizar:
Show code
import numpy as np
import pandas as pd
import geopandas as gpd
from io import BytesIO
import base64
from IPython.core.display import HTML
from plotnine import *
import seaborn as sns
import matplotlib.pyplot as plt
from mizani.formatters import date_format
from mizani.breaks import date_breaks
from scipy.stats import circmean
import pprint
import warnings
warnings.filterwarnings("ignore")2️⃣ Datos
Se importan los datos de viajes en subte de la Ciudad Autónoma de Buenos Aires, en Noviembre 2021.
Show code
base_url = 'https://cdn.buenosaires.gob.ar/datosabiertos/datasets'
dataset = 'sbase/subte-viajes-molinetes'
def read_data(url, dataset, file):
path = f'{url}/{dataset}/{file}'
print(path)
df_ = (pd.read_csv(path, delimiter=';')
.query('~FECHA.isna()', engine='python')
.rename({'DESDE':'hora'},axis=1)
.drop(['HASTA'], axis=1)
.rename(columns = lambda c: c.lower())
.assign(
linea = lambda x: [i.replace('Linea','') for i in x['linea']],
fecha = lambda x: pd.to_datetime(x['fecha'],format='%d/%m/%Y')
)
.assign(color = lambda x: np.select(
[x['linea']=='A',
x['linea']=='B',
x['linea']=='C',
x['linea']=='D',
x['linea']=='E',
x['linea']=='H'],
['#18cccc','#eb0909','#233aa8','#02db2e','#c618cc','#ffdd00'],
default='black')
)
[
['linea',
'color',
'fecha',
'hora',
'molinete',
'estacion',
'pax_pagos',
'pax_pases_pagos',
'pax_franq',
'pax_total']
]
)
return(df_)
df = read_data(url=base_url, dataset=dataset, file='molinetes_112021.csv')
df_oct = read_data(url=base_url,dataset=dataset, file='molinetes_102021.csv')Show code
#df.to_csv('data/df_nov.csv', index=False)
#df_oct.to_csv('data/df_oct.csv', index=False)
df = (pd.read_csv('data/df_nov.csv')
.assign(
fecha = lambda x: pd.to_datetime(x['fecha']),
hora = lambda x: pd.to_datetime(x['hora'], format='%H:%M:%S').dt.hour
)
)
df_oct = (pd.read_csv('data/df_oct.csv')
.assign(
fecha = lambda x: pd.to_datetime(x['fecha']),
hora = lambda x: pd.to_datetime(x['hora'], format='%H:%M:%S').dt.hour
)
)Estaciones de subte:
Show code
df_estaciones = pd.read_csv('data/estaciones.csv')
renombrar_estaciones = {
'Flores': 'San Jose De Flores',
'Saenz Peña ': 'Saenz Peña',
'Callao.b': 'Callao',
'Retiro E': 'Retiro',
'Independencia.h': 'Independencia',
'Pueyrredon.d': 'Pueyrredon',
'General Belgrano':'Belgrano',
'Rosas': 'Juan Manuel De Rosas',
'Patricios': 'Parque Patricios',
'Mariano Moreno': 'Moreno'
}
df_pasajeros_estaciones = (df
.groupby(['linea','color','estacion'], as_index=False)
.agg(pax_total = ('pax_total','sum'))
.assign(estacion = lambda x: x['estacion'].str.title())
.replace(renombrar_estaciones)
.merge(df_estaciones, on=['linea','estacion'])
)Introducción a styler objects en Pandas
Se define el estilo de la tabla y los strings que se utilizarán como títulos y subtítulos. Al definirlos como objetos podrán ser reutilizados fácilmente en cualquier tabla que se genere luego.
Show code
custom_style = [
{'selector':"caption",
'props':[("text-align", "left"),
("font-size", "135%"),
("font-weight", "bold")]
},
{'selector':'th',
"props": 'text-align : center; background-color: white; color: black'
},
{"selector": "",
"props": [("border", "1px solid lightgrey")]
}
]
titulo ='Formato de los datos (primeras 5 filas)'
subtitulo = 'Cantidad de pasajeros por molinete y por estación de todas las estaciones de la red de subte, Noviembre 2021'Un primer ejemplo para mostrar con pandas son los primeros registros del dataframe original. En este caso, se incluyen algunas primeras opciones del pandas styler object:
Show code
styled_df = (df
.drop('color',axis=1)
.assign(fecha=lambda x: x['fecha'].dt.date)
.head(5)
# A partir de acá deja de ser un dataframe y pasa a ser un styler:
.style
# Formato de dos decimales en los valores numéricos
.format(precision=2)
# Se añade una capa de título y subtítulo
.set_caption(f"""
<h1><span style="color: darkblue">{titulo}</span><br></h1>
<span style="color: black">{subtitulo}</span><br><br>
""")
# Se añade una capa de estilo
.set_table_styles(custom_style)
# Se oculta el índice
.hide(axis='index')
)
styled_df| linea | fecha | hora | molinete | estacion | pax_pagos | pax_pases_pagos | pax_franq | pax_total |
|---|---|---|---|---|---|---|---|---|
| C | 2021-11-01 | 5 | LineaC_Indepen_Turn03 | Independencia | 0 | 0 | 2 | 2 |
| A | 2021-11-01 | 5 | LineaA_Pasco_Turn03 | Pasco | 1 | 0 | 0 | 1 |
| B | 2021-11-01 | 5 | LineaB_Malabia_N_Turn05 | Malabia | 0 | 0 | 1 | 1 |
| B | 2021-11-01 | 5 | LineaB_Gallardo_S_Turn02 | Angel Gallardo | 1 | 0 | 0 | 1 |
| A | 2021-11-01 | 5 | LineaA_Congreso_S_Turn03 | Congreso | 0 | 0 | 1 | 1 |
Construcción de la tabla de subtes
Versión inicial
Se construye un dataframe a nivel Línea de subte. Para ello, se agrupa por línea obteniendo la estación más utilizada (moda) y la cantidad de usuarios totales. Se asigna el recorrido de cada línea como una nueva columna. Inicialmente se añaden columnas de la línea duplicadas, estas definen lo que luego serán gráficos.
Se incluirá una columna de % de variación de pasajeros por línea en relación al mes previo (Octubre 2021):
Show code
df_pasajeros_mesprevio = (df_oct
.groupby('linea', as_index=False)
.agg(pax_total_oct = ('pax_total','sum'))
)Show code
datos_tabla = (df
.groupby(['linea','color'], as_index=False)
.agg(
Estacion_mas_usada = ('estacion', pd.Series.mode),
pax_total = ('pax_total','sum'))
.merge(df_pasajeros_mesprevio, on='linea', how='left')
.assign(
Usuarios = lambda x: [str(round(i/1000000,2))+'M' for i in x['pax_total']],
Variacion_oct = lambda x: (x['pax_total']/x['pax_total_oct']-1),
Recorrido = lambda x: np.select([
x['linea']=='A',
x['linea']=='B',
x['linea']=='C',
x['linea']=='D',
x['linea']=='E',
x['linea']=='H'],
['Plaza de Mayo - San Pedrito',
'J.M. Rosas - L.N. Alem',
'Constitución - Retiro',
'Congreso de Tucumán - Catedral',
'Retiro - Plaza de los Virreyes',
'Hospitales - Facultad de Derecho'],
default='Otro'),
Pasajeros_por_dia = lambda x: x['linea'],
Mapa = lambda x: x['linea'],
Horas = lambda x: x['linea'],
Porcentaje = lambda x: x['linea']
)
.rename({'linea':'Linea'},axis=1)
[['Linea','Recorrido','Estacion_mas_usada','Mapa','Usuarios',
'Variacion_oct', 'Porcentaje', 'Horas','Pasajeros_por_dia','color']]
)Los recorridos en la tabla original aparecen del color de la Línea de subte, con fondo gris. Para ello, se genera un diccionario que asigne el color de la línea a cada uno de los recorridos.
color_mapping = dict(zip(datos_tabla['Recorrido'], datos_tabla['color']))
pprint.pprint(color_mapping){'Congreso de Tucumán - Catedral': '#02db2e',
'Constitución - Retiro': '#233aa8',
'Hospitales - Facultad de Derecho': '#ffdd00',
'J.M. Rosas - L.N. Alem': '#eb0909',
'Plaza de Mayo - San Pedrito': '#18cccc',
'Retiro - Plaza de los Virreyes': '#c618cc'}También se genera un diccionario que asignará el color gris a cada uno de los recorridos. Esta es una forma sencilla de colorear toda una columna, aunque puede existir alguna alternativa más simple.
color_mapping_back = dict(zip(datos_tabla['Recorrido'], ['#f0f0f0']*6))
pprint.pprint(color_mapping_back){'Congreso de Tucumán - Catedral': '#f0f0f0',
'Constitución - Retiro': '#f0f0f0',
'Hospitales - Facultad de Derecho': '#f0f0f0',
'J.M. Rosas - L.N. Alem': '#f0f0f0',
'Plaza de Mayo - San Pedrito': '#f0f0f0',
'Retiro - Plaza de los Virreyes': '#f0f0f0'}Al generar la tabla, se elimina la columna de color, ya que no es relevante. Luego de aplicar el .style, se utiliza la función applymap() para definir el formato css de la columna de recorrido a partir de los diccionarios generadods anteriromente. Se añaden el título y subtítulo como en el caso anterior.
titulo ='Uso del subte en la Ciudad Autónoma de Buenos Aires'
subtitulo = 'Período de analisis: Noviembre 2021'
tabla_inicial = (datos_tabla
.drop('color',axis=1)
.style
.applymap(lambda v: f"color: {color_mapping.get(v, 'black')}")
.applymap(lambda v: f"background-color: {color_mapping_back.get(v, 'white')}")
.set_table_styles(custom_style)
.set_caption(f"""
<h1><span style="color: darkblue">{titulo}</span><br></h1>
<span style="color: black">{subtitulo}</span><br><br>
"""
)
.hide(axis='index')
.format({
'Variacion_oct': '{:,.2%}'.format
})
)
tabla_inicial| Linea | Recorrido | Estacion_mas_usada | Mapa | Usuarios | Variacion_oct | Porcentaje | Horas | Pasajeros_por_dia |
|---|---|---|---|---|---|---|---|---|
| A | Plaza de Mayo - San Pedrito | San Pedrito | A | 2.81M | 14.97% | A | A | A |
| B | J.M. Rosas - L.N. Alem | Federico Lacroze | B | 3.48M | 12.53% | B | B | B |
| C | Constitución - Retiro | Constitucion | C | 2.13M | 19.51% | C | C | C |
| D | Congreso de Tucumán - Catedral | Congreso de Tucuman | D | 3.0M | 11.58% | D | D | D |
| E | Retiro - Plaza de los Virreyes | Retiro E | E | 1.12M | 15.50% | E | E | E |
| H | Hospitales - Facultad de Derecho | Santa Fe | H | 1.52M | 9.22% | H | H | H |
Imágenes en tabla
En la tabla original se observa que las Líneas aparecen identificadas con una letra de color. Esta letra es una imagen, que se puede incluir en la tabla a partir del archivo .png de esa imagen. Estos archivos se encuentran almacenados localmente, con lo cual se pueden incluir en la tabla de la siguiente forma:
- Se genera una función que para cada Línea obtiene retorna el path de la imagen en formato html:
Show code
def map_linea_img(i):
path = f'lineas/{i.lower()}.jpg'
return '<img src="'+ path + '" width="15" >'Se aplica la función map_linea_img() a la columna linea del styler object:
(tabla_inicial
.format(formatter={
'Linea':map_linea_img,
'Variacion_oct': '{:,.2%}'.format
})
)| Linea | Recorrido | Estacion_mas_usada | Mapa | Usuarios | Variacion_oct | Porcentaje | Horas | Pasajeros_por_dia |
|---|---|---|---|---|---|---|---|---|
| Plaza de Mayo - San Pedrito | San Pedrito | A | 2.81M | 14.97% | A | A | A | |
| J.M. Rosas - L.N. Alem | Federico Lacroze | B | 3.48M | 12.53% | B | B | B | |
| Constitución - Retiro | Constitucion | C | 2.13M | 19.51% | C | C | C | |
| Congreso de Tucumán - Catedral | Congreso de Tucuman | D | 3.0M | 11.58% | D | D | D | |
| Retiro - Plaza de los Virreyes | Retiro E | E | 1.12M | 15.50% | E | E | E | |
| Hospitales - Facultad de Derecho | Santa Fe | H | 1.52M | 9.22% | H | H | H |
Plots en tabla
Show code
#https://stackoverflow.com/questions/47038538/insert-matplotlib-images-into-a-pandas-dataframeEste es uno de los puntos más complicados, por eso es necesario realizarlo de forma ordenada. Para los gráficos incluidos en la tabla, se comenzará generando el gráfico para una línea. Luego de observar que funciona, se incluye en la tabla para cada una de las líneas, mediante una función map_plot_{nombre_del_grafico}(). Se comienza por el caso más simple, de la evolución del uso de cada línea en el mes de noviembre 2021:
Evolución
Se obtiene la data de la cantidad de pasajeros por fecha en una línea particular:
Show code
i = 'A'
data_linea=(df
.query("linea==@i")
.groupby('fecha', as_index=False)
.pax_total
.sum()
)Se utiliza plotnine para generar el gráfico de la evolución de la línea A:
Show code
p=(ggplot(
data = data_linea,
mapping = aes(x='fecha', y='pax_total', group=1)
) +
geom_line()+
theme_minimal()+
labs(x='',y='N')+
scale_x_datetime(
labels = date_format("%Y-%m"),
breaks=date_breaks('7 days')
)+
theme_void()+
theme(
text=element_text(size=8),
axis_text_x=element_text(vjust=-0.5))+
labs(x = '', y = '')
)
print(p)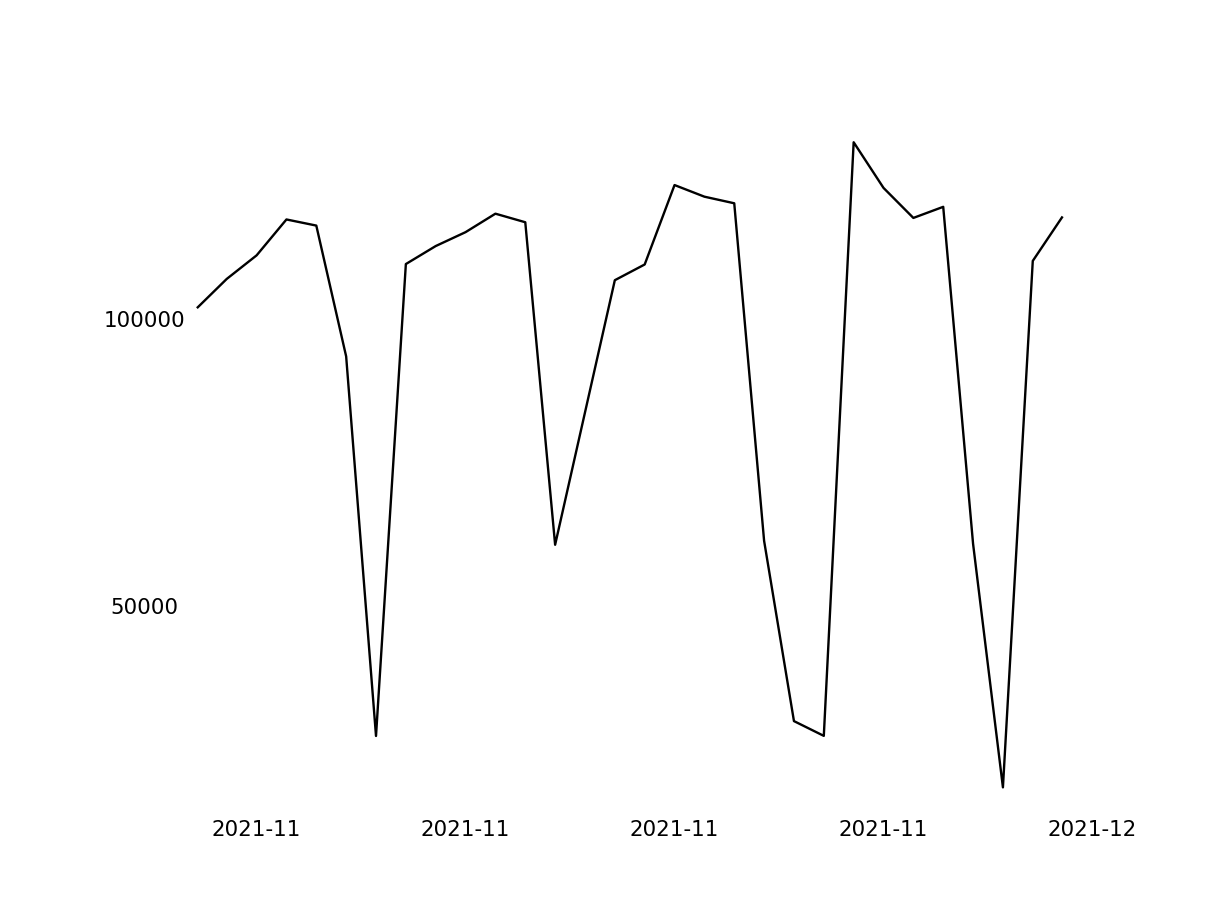
Habiendo definido el gráfico correctamente, se convierte en función:
Show code
def fig_evol_pax_total(i):
data_linea=df.query("linea==@i")
color = data_linea.color.max()
data_linea=(data_linea
.groupby('fecha', as_index=False)
.pax_total
.sum()
)
p = (ggplot(
data = data_linea,
mapping = aes(x='fecha', y='pax_total',group=1)
) +
geom_line(color=color)+
theme_minimal()+
labs(x='',y='N')+
scale_x_datetime(
labels = date_format("%Y-%m"),
breaks=date_breaks('7 days')
)+
labs(x = '', y = '') +
theme_void()+
theme(
panel_background= element_rect(fill=None),
plot_background = element_rect(fill=None),
text=element_text(size=7),
axis_text_x=element_text(vjust=-0.5)
)
)
return pLa función anterior retorna el gráfico para una línea i dada. Sin embargo, lo que se busca mappear en la tabla no es el gráfico, sino una imagen del gráfico. Para ello, se genera una función intermedia que toma el gráfico y lo convierte al path html de una imagen temporal:
Show code
def plotnine2html(p,i, width=5, height=2):
figfile = BytesIO()
p.save(figfile, format='png', width=width, height=height, units='in')
figfile.seek(0)
figdata_png = base64.b64encode(figfile.getvalue()).decode()
imgstr = f'<img src="data:image/png;base64,{figdata_png}" />'
return imgstrFinalmente, se genera la función de mappeo, que será utilizada para generar los gráficos en la tabla:
Show code
def map_plot_evol(i):
fig = fig_evol_pax_total(i)
return plotnine2html(fig,i)Ahora es posible aplicar la función tal como en el caso de las imagenes de las líneas de subte:
(tabla_inicial
.format(
formatter={
'Linea':map_linea_img,
'Pasajeros_por_dia': map_plot_evol,
'Variacion_oct': '{:,.2%}'.format
})
)| Linea | Recorrido | Estacion_mas_usada | Mapa | Usuarios | Variacion_oct | Porcentaje | Horas | Pasajeros_por_dia |
|---|---|---|---|---|---|---|---|---|
| Plaza de Mayo - San Pedrito | San Pedrito | A | 2.81M | 14.97% | A | A |  |
|
| J.M. Rosas - L.N. Alem | Federico Lacroze | B | 3.48M | 12.53% | B | B |  |
|
| Constitución - Retiro | Constitucion | C | 2.13M | 19.51% | C | C |  |
|
| Congreso de Tucumán - Catedral | Congreso de Tucuman | D | 3.0M | 11.58% | D | D |  |
|
| Retiro - Plaza de los Virreyes | Retiro E | E | 1.12M | 15.50% | E | E |  |
|
| Hospitales - Facultad de Derecho | Santa Fe | H | 1.52M | 9.22% | H | H |  |
Mapa
Al igual que en el caso anterior, primero se construye un gráfico (mapa) individual y luego se transforma en las funciones necesarias para el mappeo del gráfico a cada línea.
Se obtienen los datos del mapa:
Show code
url_mapa = 'http://cdn.buenosaires.gob.ar/datosabiertos/datasets/barrios/barrios.geojson'
mapa = gpd.read_file(url_mapa)En este caso, se genera directamente la función del gráfico aplicandola sobre una línea:
Show code
def fig_mapa(i):
"""
Generación de mapa de uso de cada lìnea
"""
data_linea=(df_pasajeros_estaciones
.query("linea==@i")
.assign(
pax_percent = lambda x:
x['pax_total']/
df_pasajeros_estaciones.query("linea==@i")['pax_total'].sum()*100
)
)
color = data_linea.color.max()
lbreaks = round(
data_linea['pax_percent'].quantile([0,0.25,0.5,0.75,1]),2
)
p = (ggplot(data=mapa)+
geom_map(fill='white', color = "black", size = 0.1)+
geom_point(data=data_linea,
mapping=aes(x='long',y='lat', size='pax_percent'),
alpha=0.5, color='black', shape='o', fill=color)+
scale_size_continuous(
lbreaks=lbreaks,
range=[1,10],
limits = [
data_linea['pax_percent'].min()-1,
data_linea['pax_percent'].max()+1
],
labels=lambda l: [f'{round(i)}%' for i in l])+
theme_void()+
theme(legend_position='right')+
labs(size='%')
)
return p
print(fig_mapa(i=i)+theme(legend_position='none'))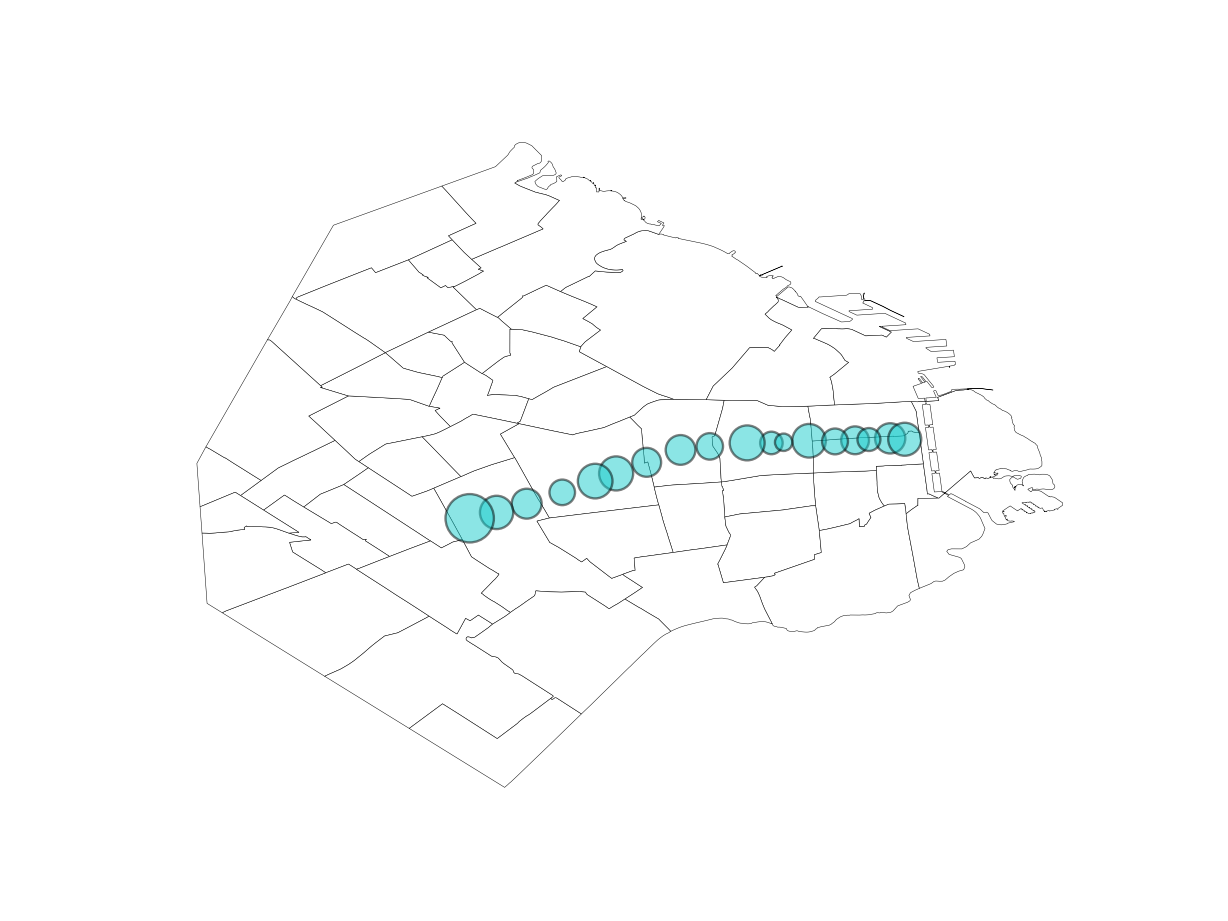
Se genera la función de mappeo:
Show code
def map_plot_mapa(i):
fig = fig_mapa(i)
return plotnine2html(fig, i, width=5, height=5)Se incluye el plot en la tabla:
(tabla_inicial
.format(
formatter={
'Linea':map_linea_img,
'Pasajeros_por_dia': map_plot_evol,
'Mapa':map_plot_mapa,
'Variacion_oct': '{:,.2%}'.format
})
)| Linea | Recorrido | Estacion_mas_usada | Mapa | Usuarios | Variacion_oct | Porcentaje | Horas | Pasajeros_por_dia |
|---|---|---|---|---|---|---|---|---|
| Plaza de Mayo - San Pedrito | San Pedrito |  |
2.81M | 14.97% | A | A | |
|
| J.M. Rosas - L.N. Alem | Federico Lacroze |  |
3.48M | 12.53% | B | B | |
|
| Constitución - Retiro | Constitucion |  |
2.13M | 19.51% | C | C | |
|
| Congreso de Tucumán - Catedral | Congreso de Tucuman |  |
3.0M | 11.58% | D | D | |
|
| Retiro - Plaza de los Virreyes | Retiro E |  |
1.12M | 15.50% | E | E | |
|
| Hospitales - Facultad de Derecho | Santa Fe |  |
1.52M | 9.22% | H | H | |
Porcentajes por grupos
Una de las funcionalidades de gt permite transformar una columna con listas de porecntajes en gráficos de porcentajes. En este caso, se decidió hacerlo con plotnine.
Show code
def fig_percent(i):
temp = (df
.query('linea==@i')
.assign(
hora_grupo = lambda x: pd.cut(
x['hora'], bins=3, labels = ['Mañana', 'Tarde', 'Noche'])
)
.groupby(['linea','hora_grupo'], as_index=False)
.agg(pax_total = ('pax_total','sum'))
)
temp['perc']=round(
temp['pax_total'] / temp.groupby('linea')['pax_total'].transform('sum')*100,2)
temp['perc_lab'] = [str(i)+'%' for i in temp['perc']]
p=(ggplot(data=temp,
mapping=aes(x='linea', y='perc', fill='hora_grupo', label='perc_lab'))+
geom_col(position= position_stack(reverse=True))+
geom_text(
position = position_stack(vjust = .5, reverse=True),
color='white', size=8)+
coord_flip()+
scale_fill_manual(['grey', '#A3B1C9','#4C699E'])+
theme_void()+
theme(legend_position='none')
)
return p
print(fig_percent(i='A'))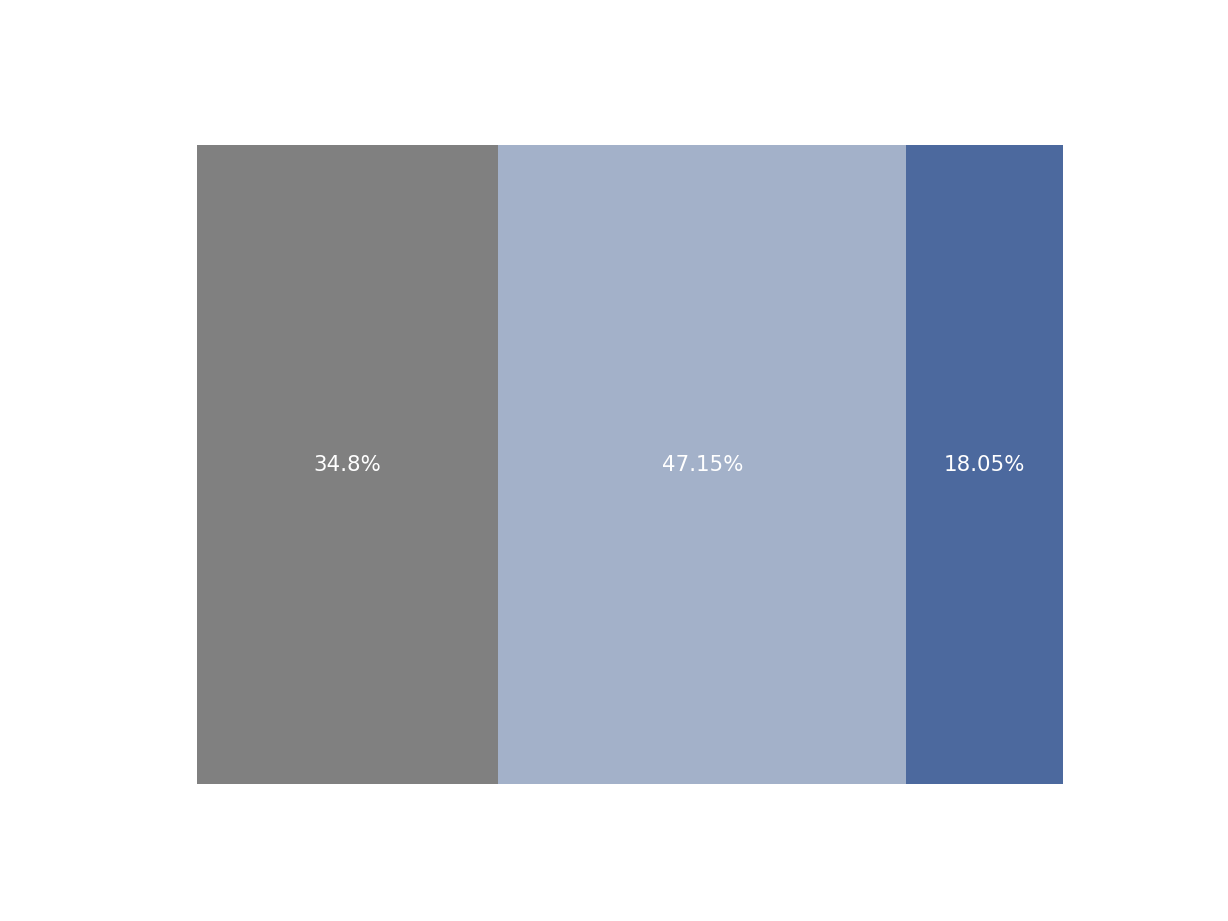
Se genera la función de mappeo:
Show code
def map_plot_percent(i):
fig = fig_percent(i)
return plotnine2html(fig,i, width=4, height=0.4)Se incluye el plot en la tabla:
(tabla_inicial
.format(
formatter={
'Linea':map_linea_img,
'Pasajeros_por_dia': map_plot_evol,
'Mapa':map_plot_mapa,
'Porcentaje':map_plot_percent,
'Variacion_oct': '{:,.2%}'.format
})
)| Linea | Recorrido | Estacion_mas_usada | Mapa | Usuarios | Variacion_oct | Porcentaje | Horas | Pasajeros_por_dia |
|---|---|---|---|---|---|---|---|---|
| Plaza de Mayo - San Pedrito | San Pedrito | |
2.81M | 14.97% |  |
A | |
|
| J.M. Rosas - L.N. Alem | Federico Lacroze | |
3.48M | 12.53% |  |
B | |
|
| Constitución - Retiro | Constitucion | |
2.13M | 19.51% |  |
C | |
|
| Congreso de Tucumán - Catedral | Congreso de Tucuman | |
3.0M | 11.58% |  |
D | |
|
| Retiro - Plaza de los Virreyes | Retiro E | |
1.12M | 15.50% |  |
E | |
|
| Hospitales - Facultad de Derecho | Santa Fe | |
1.52M | 9.22% |  |
H | |
Circular plot
En este caso se utiliza R para el cálculo de la hora promedio a través del paquete {circular}
Show code
library(circular)
library(reticulate)
library(tidyverse)
library(reshape)
get_hour <- function(.linea, .df) {
temp <- .df %>%
filter(linea == .linea) %>%
select(hora, pax_total)
hora <- untable(temp, num = temp$pax_total) %>%
select(-pax_total) %>%
mutate(hora_circular = circular(hora,
template = "clock24",
units = "hours")) %>%
summarise(hora = mean(hora_circular)) %>%
pull(hora)
as.numeric(hora) %% 24
}
df_horas_promedio = data.frame(Linea=py$df %>% pull(linea) %>% unique()) %>%
mutate(hora_promedio=map(Linea, ~get_hour(.linea=.x, .df=py$df)))Se define la función que genera los gráficos circulares:
Show code
def gen_clock_plot(df_, hora_promedio, x='hora', y='pax_total', color='blue'):
"""
Generar un gráfico de barras con coordenadas polares
Inputs:
- df: dataframe
- x: nombre de la variable x
- y: nombre de la variable y
"""
fig, ax = plt.subplots(figsize=(4,4))
ax = plt.subplot(111, polar=True)
cr = df_[y].astype('float').to_numpy()
hour = df_[x].astype('float').to_numpy()
N = 24
bottom = 2
theta = np.linspace(0.0, 2 * np.pi, N, endpoint=False)
width = (2*np.pi) / N
bars = ax.bar(theta, cr,
width=width,
bottom=bottom,
color='lightgrey',
edgecolor='white')
ax.vlines(
x= hora_promedio*theta.max()/24,
ymin=0, ymax=df_['pax_total'].max(),
color=color)
ax.set_theta_zero_location("N")
ax.set_theta_direction(-1)
ticks = ['0:00', '3:00', '6:00', '9:00', '12:00', '15:00', '18:00', '21:00']
ax.set_xticklabels(ticks)
return fig
def fig_clock_plot(i):
data_linea=df.query("linea==@i")
color = data_linea.color.max()
data_hora = (pd.DataFrame({'hora':range(0,24)})
.merge(df
.query('linea==@i')
.groupby('hora', as_index=False)
.agg(pax_total = ('pax_total','sum')),
how='left'
)
.fillna(0)
)
hora_promedio = r.df_horas_promedio.query("Linea==@i").hora_promedio
return gen_clock_plot(data_hora, color=color, hora_promedio=hora_promedio)
fig_clock_plot(i=i)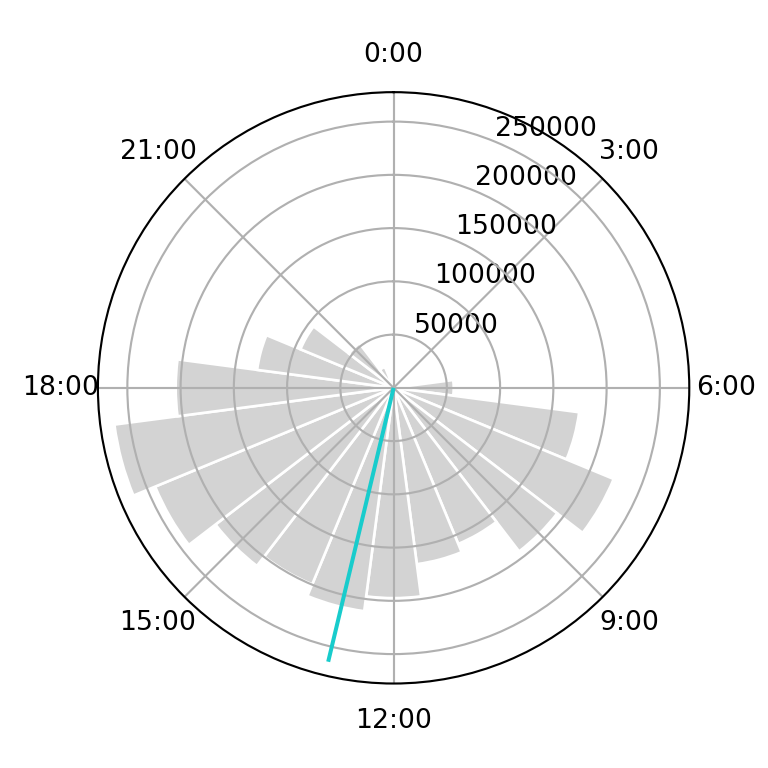
Se generan las funciones de mappeo:
Show code
def clock2inlinehtml(p,i):
figfile = BytesIO()
plt.savefig(figfile, format='png', dpi=100, transparent=True)
figfile.seek(0)
figdata_png = base64.b64encode(figfile.getvalue()).decode()
imgstr = f'<img src="data:image/png;base64,{figdata_png}" />'
figfile.close()
return imgstr
def map_plot_reloj(i):
plt.figure(figsize=(5,5))
fig = fig_clock_plot(i)
return clock2inlinehtml(fig,i)Se añaden los gráficos al df. Se visualizará en el paso siguiente, junto con algunas transformaciones adicionales:
tabla_plots = (tabla_inicial
.format(
formatter={
'Linea':map_linea_img,
'Pasajeros_por_dia': map_plot_evol,
'Mapa':map_plot_mapa,
'Porcentaje':map_plot_percent,
'Horas':map_plot_reloj,
'Variacion_oct': '{:,.2%}'.format
})
)Estilo final
Algunas cuestiones de estilo final:
Show code
fuente = "<div><br>Elaboración propia en base a datos del Portal de datos abiertos de la Ciudad de Buenos Aires</br></div>"
caption_porcentaje = "<div>(1): % de pasajeros por estación en relación al total de pasajeros en esa línea. Para los cortes se utilizaron los cuantiles de la distribución. Se observa que la Línea C presentó un uso muy elevado en las cabeceras, mientras que en el resto de las líneas el uso fue más distribuido.</div>"
caption_variacion = """<div>(2): % Variación en relación a Octubre 2021.</div>"""tabla_final = HTML(tabla_plots
.to_html()
.replace('Mapa','% Pasajeros por estación (1)')
.replace('Porcentaje','% Pasajeros por hora')
.replace('Variacion_oct','% Variación (2)')
.replace('Horas','Pasajeros por hora')
.replace('Estacion_mas_usada','Estación más utilizada')
+ f'<caption>{caption_porcentaje}<br>{caption_variacion}<br>{fuente}</>'
)
tabla_final| Linea | Recorrido | Estación más utilizada | % Pasajeros por estación (1) | Usuarios | % Variación (2) | % Pasajeros por hora | Pasajeros por hora | Pasajeros_por_dia |
|---|---|---|---|---|---|---|---|---|
| Plaza de Mayo - San Pedrito | San Pedrito | |
2.81M | 14.97% | |
 |
|
|
| J.M. Rosas - L.N. Alem | Federico Lacroze | |
3.48M | 12.53% | |
 |
|
|
| Constitución - Retiro | Constitucion | |
2.13M | 19.51% | |
 |
|
|
| Congreso de Tucumán - Catedral | Congreso de Tucuman | |
3.0M | 11.58% | |
 |
|
|
| Retiro - Plaza de los Virreyes | Retiro E | |
1.12M | 15.50% | |
 |
|
|
| Hospitales - Facultad de Derecho | Santa Fe | |
1.52M | 9.22% | |
 |
|
Elaboración propia en base a datos del Portal de datos abiertos de la Ciudad de Buenos Aires
Show code
import dataframe_image as dfi
dfi.export(tabla_plots, 'df_styled.png')Comentarios finales
En este post se mostraron varias formas de modificar el estilo en tablas pandas. Esto no quiere decir que sean la única o mejor forma de realizar estos pasos. Cualquier comentario es bienvenido!
Contacto ✉
Karina Bartolome, Linkedin, Twitter, Github, Blogpost